Clear Sky Science · de
AE-LFOG-YOLO: robuste Helmerkennung durch adaptive Anker und lichtinvariante Lernverfahren
Warum intelligente Helmkontrollen wichtig sind
Auf großen Baustellen und in unterirdischen Tunneln kann ein einfacher Schutzhelm den Unterschied zwischen einer Beinahe‑Verletzung und einer lebensverändernden Verletzung ausmachen. Doch in der Hektik realer Baustellen vergessen oder verzichten Menschen darauf, Helme zu tragen, und menschliche Aufsichtspersonen können nicht jede Ecke ständig überwachen. Diese Studie untersucht, wie man ein automatisiertes Kamerasystem baut, das zuverlässig erkennt, wer einen Helm trägt und wer nicht — selbst wenn der Tunnel dunkel ist, durch Lampen geblendet wird oder viele Arbeiter in unterschiedlichen Entfernungen zur Kamera zu sehen sind.
Herausforderungen beim Sehen unter harten Tunnelbeleuchtungen
Tunnelbaustellen sind visuell extreme Umgebungen. Helle Scheinwerfer erzeugen Blendung, während tiefe Schattenbereiche Details verbergen. Menschen bewegen sich zur Kamera hin und von ihr weg, sodass Helme in sehr unterschiedlichen Größen erscheinen. Standard‑KI‑Erkenner versagen in diesen Bedingungen oft: Sie übersehen Helme in dunklen Bereichen, verwechseln andere runde Objekte mit Helmen oder haben Probleme mit sehr kleinen bzw. weit entfernten Arbeitern. Viele bestehende Systeme versuchen, das durch Aufhellen oder Reinigen der Bilder vor der Erkennung oder durch das Verändern einiger Komponenten populärer YOLO‑Modelle zu beheben. Da diese Schritte jedoch meist als nachträgliche Fixes und nicht als Teil eines integrierten Lernprozesses umgesetzt sind, bleiben Leistungspotenziale ungenutzt und die Systeme sind weniger robust gegenüber Änderungen in Beleuchtung oder Szenenaufbau.
Ein neuer Weg, Kameras beizubringen, schlechte Beleuchtung zu ignorieren
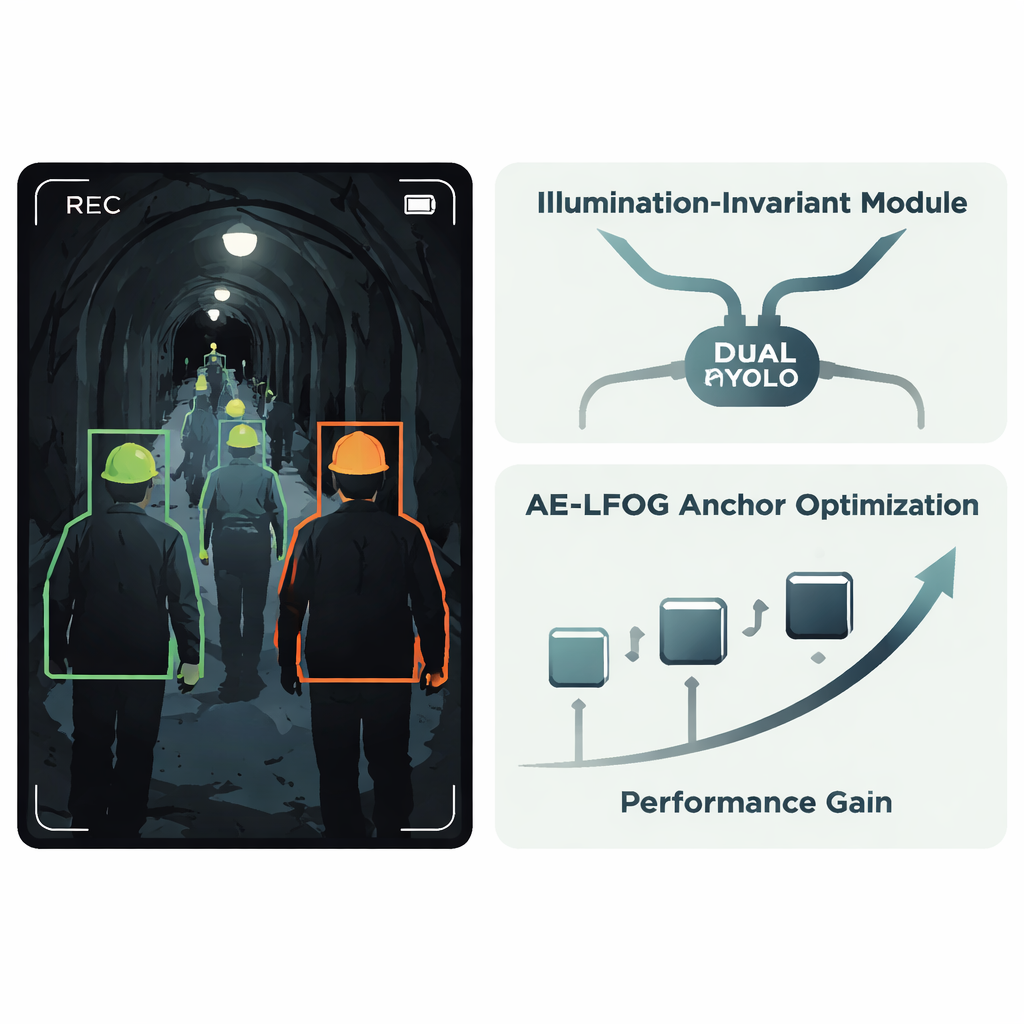
Die Autoren schlagen ein verbessertes System namens AE‑LFOG‑YOLO vor, das auf dem weit verbreiteten YOLOv8‑Detektor aufbaut. Die erste zentrale Idee ist ein Illumination‑Invariant Module, eine kleine Einheit im Netzwerk, die lernt, "was das Licht tut" von "wie die Objekte tatsächlich aussehen" zu trennen. Sie teilt eingehende Merkmalskarten in einen Teil, der hauptsächlich Beleuchtungsmuster widerspiegelt, und einen Teil, der stabilere Form‑ und Texturinformationen erfasst, etwa die geschwungene Kante eines Helms. Durch spezielle Gating‑Operationen und einen Zweig, der sich auf Kanten und Ecken konzentriert, dämpft das Modul Helligkeitsschwankungen und betont stabile Geometrie. Da dies innerhalb des Detektors und nicht in einem separaten Vorverarbeitungsschritt geschieht, kann das Gesamtsystem end‑to‑end trainiert werden, um sich auf die Helme selbst zu fokussieren, anstatt von Blendungen oder Dunkelheit getäuscht zu werden.
Dem Modell erlauben, seine eigenen Sehgewohnheiten zu entwickeln
Die zweite Hauptidee betrifft, wie der Detektor vermutet, wo Objekte auftreten könnten. Viele Detektoren starten mit einem festen Satz von "Ankerboxen", die wahrscheinliche Objektgrößen und ‑formen vorschlagen; diese werden in der Regel einmal aus den Trainingsdaten gewählt und dann nicht mehr angepasst. In Tunneln kann die scheinbare Größe eines Helms jedoch mit Kameraentfernung und Blickwinkel stark variieren. AE‑LFOG‑YOLO ersetzt statische Anker durch einen dynamischen Prozess namens Adaptive Evolutionary – Light Field Optimized Generation. Am Ende jeder Trainingsrunde werden die Ankerboxen behutsam perturbiert, bewertet, wie gut sie reale Helme aller Größen abdecken, und zusätzlich darauf geprüft, ob ihre Dimensionen mit grundlegenden Kameraprinzipien übereinstimmen — also wie groß ein echter Helm auf dem Sensor bei typischen Arbeitsdistanzen aussehen sollte. Besser bewertete Ankersätze überleben in die nächste Runde. Im Laufe der Zeit „entwickelt“ der Detektor Anker, die sowohl zu den Daten passen als auch respektieren, wie Kameras die Welt tatsächlich abbilden.
Das Training an die reale Bildqualität anpassen
Über die Veränderung dessen, wonach das Modell sucht, hinaus ändern die Autoren auch, wie es lernt. Sie führen eine Trainingsstrategie ein, die bei schlechter Bildqualität mehr Gewicht auf die präzise Lokalisierung der Helme legt und bei guten Bedingungen stärker auf die richtige Klassifizierung Helm vs. kein Helm abzielt. Ein physik‑basiertes Score, ebenfalls aus Kamerabildgebungsprinzipien abgeleitet, sagt dem System, wie vertrauenswürdig die Bilder in jeder Phase sind. Sind Beleuchtung oder Fokus schlecht, erhöht der Trainingsprozess automatisch die Bedeutung korrekt platzierter Begrenzungsrahmen; verbessern sich die Bedingungen, verschiebt sich das Gewicht zugunsten der Klassifikation. Das erzeugt eine Rückkopplung, in der das Modell seine Prioritäten kontinuierlich an die physikalische Umgebung anpasst, der es in realen Tunneln begegnen wird.
Was die Tests in der Praxis zeigen
Die Forschenden testen ihren Ansatz auf einem realen Tunnel‑Schutzhelmdatensatz und vergleichen ihn mit mehreren fortgeschrittenen YOLO‑basierten Methoden. AE‑LFOG‑YOLO erkennt Helme mit sehr hoher Genauigkeit und identifiziert etwa 95 Prozent der Helme bei einem Standard‑Overlap‑Schwellenwert korrekt; es übertrifft die einfache YOLOv8‑Baseline sowohl bei Präzision als auch bei Recall. Es läuft schnell genug für den Echtzeitbetrieb und erweist sich insbesondere dann als stark, wenn die Beleuchtung so manipuliert wird, dass extreme Dunkelheit oder Überbelichtung simuliert werden. Unter diesen harten Bedingungen behält das neue Modell höhere Zuversicht, entdeckt mehr kleine und entfernte Arbeiter und arbeitet über einen Helligkeitsbereich, der mehr als ein Drittel breiter ist als der der Baseline — das heißt, es bleibt in einer deutlich größeren Menge realer Szenen zuverlässig.
Wie das hilft, Arbeiter sicherer zu machen
Für Nicht‑Spezialisten ist die Schlussfolgerung klar: Indem ein KI‑System nicht nur Pixel, sondern auch die Physik dessen lernt, wie Kameras in schwierigen Umgebungen sehen, liefert diese Arbeit einen intelligenteren, verlässlicheren Wächter an der Tunnelwand. AE‑LFOG‑YOLO kann irreführende Beleuchtung besser ignorieren und sich an wechselnde Blickwinkel anpassen, wodurch verpasste Erkennungen und Fehlalarme reduziert werden. Über Monate auf einer betrieblichen Bahnbau‑Strecke eingesetzt, hat es bereits gezeigt, dass es Sicherheitsteams dabei unterstützen kann, sicherzustellen, dass Arbeiter ihre Helme tragen — ein praktischer Schritt hin zu sichereren, besser überwachten Baustellen.
Zitation: Liu, S., Wang, J. AE-LFOG-YOLO: robust safety helmet detection via adaptive anchors and illumination invariant learning. Sci Rep 16, 6402 (2026). https://doi.org/10.1038/s41598-026-37326-z
Schlüsselwörter: Schutzhelmerkennung, Tunnelbau, Computer Vision, Niedriglichtabbildung, YOLOv8