Clear Sky Science · de
Leistungsbewertung eines generativen, vortrainierten Transformers bei der nationalen Tierärztezulassungsprüfung in Japan
Warum bessere Tierarztprüfungen uns alle betreffen
Hinter jedem Besuch in der Tierklinik stehen Jahre strenger Ausbildung und eine hochbrisante nationale Prüfung. In Japan müssen angehende Tierärzte die nationale Tierärztezulassungsprüfung (NVLE) bestehen, die alles abfragt – von Grundlagen der Biologie bis hin zu komplexem klinischem Urteilsvermögen. Diese Studie stellte eine aktuelle Frage: Können heutige fortgeschrittene KI‑Sprachmodelle, dieselben Systeme, die beliebte Chatbots antreiben, diese anspruchsvolle Prüfung auf Japanisch lösen – und was könnte das für die tierärztliche Ausbildung und die Versorgung von Tieren bedeuten?
KI an einer echten tierärztlichen Zulassungsprüfung testen
Die Forschenden konzentrierten sich auf drei Generationen großer Sprachmodelle von OpenAI: GPT‑4o, o1 und o3. Diese Systeme sind darauf ausgelegt, menschenähnlichen Text zu lesen und zu erzeugen, wurden jedoch nie speziell für die Veterinärmedizin trainiert. Um sie zu prüfen, nutzte das Team die 74. NVLE (2023) Japans als Benchmark. Die Prüfung ist in fünf Abschnitte unterteilt, darunter textbasierte Fragen und bildbasierte Aufgaben mit Röntgenaufnahmen, Fotos oder Diagrammen. Alle Fragen sind Multiple‑Choice mit fünf Antwortoptionen – genau wie die echte Prüfung der Studierenden. Die Modelle erhielten jede Frage über ein standardisiertes Skript und mussten ausschließlich die Nummer der gewählten Option zurückgeben, ohne die Möglichkeit, zu „erklären“ oder sich zusätzliche Punkte zu erschreiben.
Welches KI‑Modell lag vorn?
Als die drei Modelle die 74. NVLE im einfachsten Setup bearbeiteten – japanische Fragen und eine einfache Anweisungsaufforderung – traten zwei klare Trends zutage. Erstens lieferten alle Modelle starke Leistungen in den textbasierten Abschnitten, wobei o1 und o3 durchweg bessere Ergebnisse erzielten als GPT‑4o. Zweitens sank die Leistung in bildintensiven Abschnitten, doch o1 und o3 blieben weiterhin über der offiziellen Mindestbestehensgrenze, während GPT‑4o in einem dieser Abschnitte nicht genügte. Insgesamt beantwortete GPT‑4o etwa 78 % der Fragen korrekt, o1 erreichte etwa 92 % und o3 etwa 93 %. Da o3 o1 im Gesamtergebnis leicht übertraf, wählten die Forschenden o3 für die weiteren Experimente.
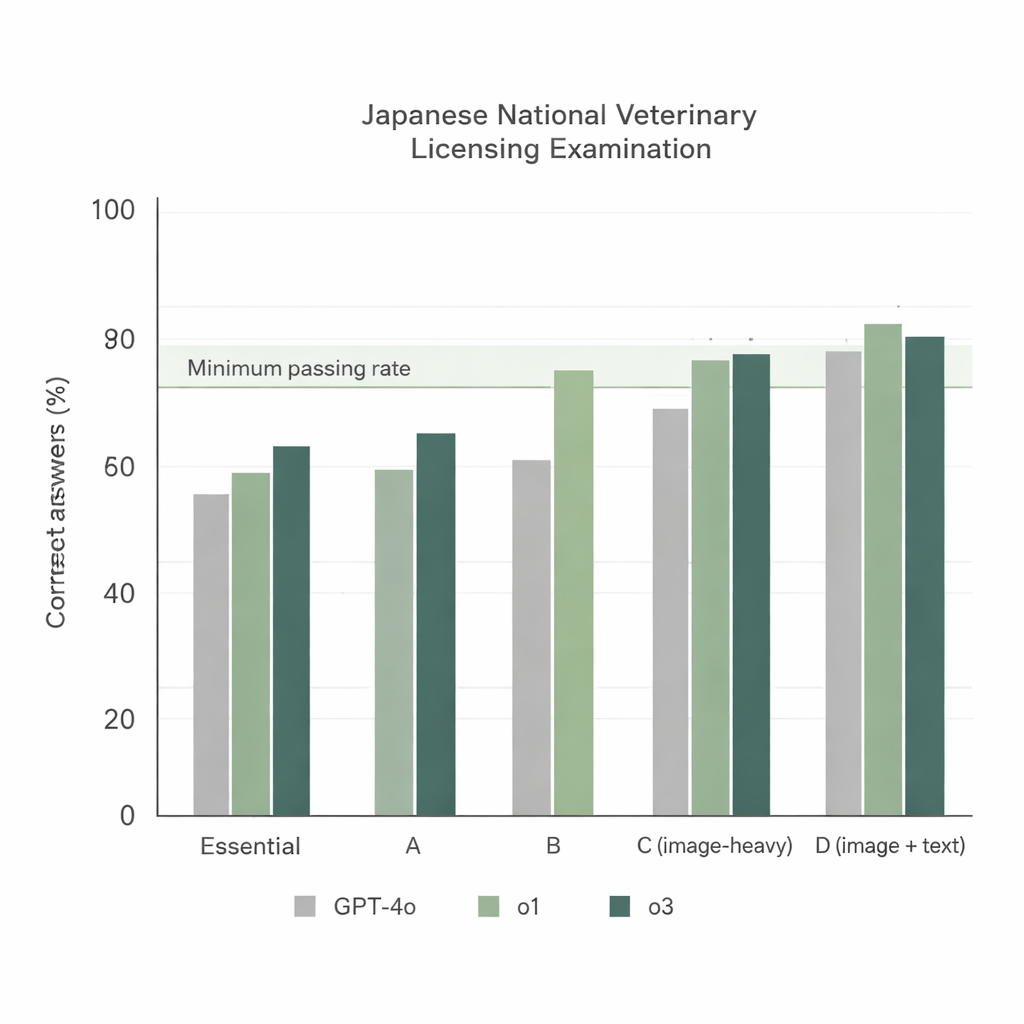
Helfen Prompts oder Übersetzungen wirklich?
Viel ist über „Prompt‑Engineering“ geschrieben worden – das Ausformulieren komplexer Anweisungen, um bessere Antworten von KI zu erhalten – sowie über das Übersetzen lokaler Prüfungsfragen ins Englische, um sie an die Trainingsdaten der Modelle anzupassen. Die Studie prüfte diese Ideen direkt mit dem Modell o3, indem sie einen einfachen Lösungs‑Prompt mit einem detaillierteren, optimierten Prompt sowie japanische Fragen mit zuvor vom Modell ins Englische übersetzten Versionen verglich. Überraschenderweise hatten diese Änderungen keine nennenswerte Auswirkung: o3 bestand in allen sechs Kombinationen mühelos, und der einfachste Ansatz (Originaltext auf Japanisch mit dem Basis‑Prompt) funktionierte genauso gut wie die komplizierteren Setups. Das deutet darauf hin, dass die neuesten Modelle die japanische Sprache für diese tierärztlichen Fragestellungen zuverlässig verstehen und keine ausgefeilten Prompts benötigen, um auf hohem Niveau zu arbeiten.
Wie stabil ist die Leistung bei neueren Prüfungen?
Um zu prüfen, ob die starken Ergebnisse zufällig waren, setzte das Team o3 anschließend der 75. (2024) und 76. (2025) NVLE aus, wiederum nur mit den originalen japanischen Fragen und dem normalen Prompt. Das Modell erzielte in beiden Prüfungen Gesamtergebnisse von über 92 % und übertraf die Bestehensgrenze in jedem Abschnitt, einschließlich der bildintensiven Bereiche. Die meisten Fragen erhielten über drei unabhängige Durchläufe hinweg dieselbe Antwort, was zeigt, dass o3‑Antworten im Allgemeinen stabil waren, selbst wenn ein gewisses Maß an Zufälligkeit zugelassen wurde. Bei genauerer Analyse der Fehler zeigte sich, dass diese in zwei Bereichen konzentriert waren: praktische veterinärmedizinische Kenntnisse (etwa japanische Veterinärgesetze) und klinische Medizin, die länderspezifische Regeln und mehrschrittiges Denken erfordern, statt reines Faktenwissen.
Was das bedeutet – und was nicht
Die Studie kommt zu dem Schluss, dass hochentwickelte GPT‑artige Modelle inzwischen Japans tierärztliche Zulassungsprüfung auf Japanisch bestehen können, ohne Übersetzungstricks oder komplexe Prompts. Für tierärztliche Fakultäten und Studierende eröffnet das Möglichkeiten, KI als Lernpartner, Fragengenerator oder Erklärhilfe für Prüfungsthemen einzusetzen. Für die Öffentlichkeit signalisiert es, dass KI zu einem mächtigen Werkzeug zur Organisation und Vermittlung veterinärmedizinischen Wissens wird. Die Autorinnen und Autoren betonen jedoch, dass diese Systeme nicht bereit sind, Tierärzte zu ersetzen oder medizinische Entscheidungen eigenständig zu treffen. Die Modelle können Bilder falsch interpretieren, Probleme mit nuanciertem klinischem Urteil haben und teilweise Fakten erfinden. Sorgfältig eingesetzt, können sie wertvolle Assistenten in der tierärztlichen Ausbildung und Informationsunterstützung werden – aber die Verantwortung für die Gesundheit der Tiere bleibt fest in menschlicher Hand.
Zitation: Kako, T., Kato, D., Iguchi, T. et al. Performance evaluation of generative pre-trained transformer on the National Veterinary Licensing Examination in Japan. Sci Rep 16, 4306 (2026). https://doi.org/10.1038/s41598-026-37300-9
Schlüsselwörter: Tierärztliche Zulassungsprüfungen, große Sprachmodelle, Künstliche Intelligenz in der Medizin, GPT‑Leistung, Japanische tierärztliche Ausbildung