Clear Sky Science · de
SSG–CAM: Verbesserung der visuellen Interpretierbarkeit durch verfeinerte zweiter Ordnung Gradienten und evolutionäre Mehrschichtfusion
Warum es wichtig ist, ins Innere von KI zu blicken
Moderne Bilderkennungssysteme können Tumore, Verkehrsschilder oder winzige Parasiten in Blutzellen mit übermenschlicher Geschwindigkeit erkennen – doch sie zeigen selten genau, warum sie eine Entscheidung getroffen haben. Dieses „Black-Box“-Verhalten ist besonders in der Medizin und in sicherheitskritischen Bereichen problematisch, wo ein falsches Urteil schwerwiegende Folgen haben kann. Die Arbeit stellt einen neuen Ansatz vor, mit dem sich Deep‑Learning‑Modelle visuell klarer und verlässlicher erklären lassen, sodass Menschen sehen können, welche Bildbereiche die Wahl der KI tatsächlich beeinflusst haben.
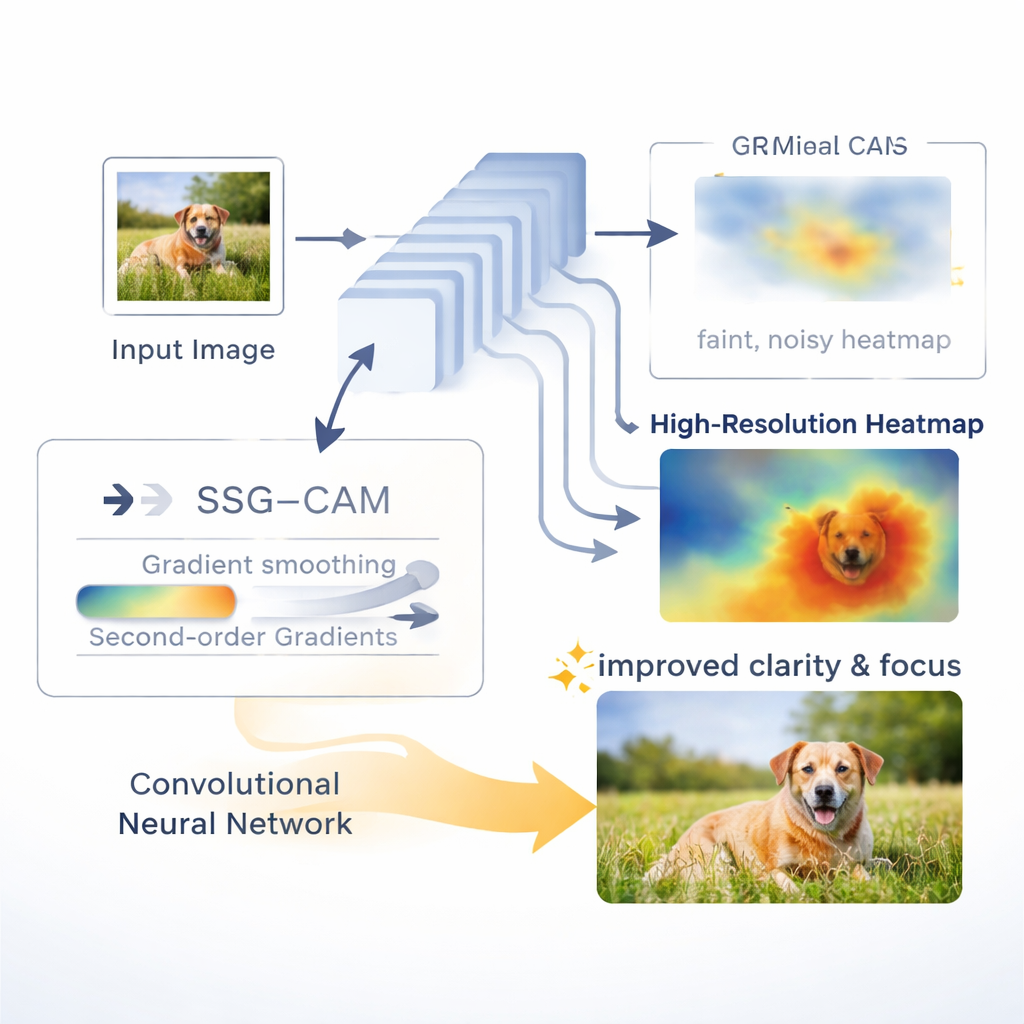
Von unscharfen Heatmaps zu schärferen Erklärungen
Eine verbreitete Werkzeugfamilie, die sogenannten Class Activation Maps (CAMs), verwandelt das Innenleben eines neuronalen Netzes in bunte Heatmaps, die über das Originalbild gelegt werden. Helle Bereiche zeigen, wo das Modell „hingeschaut“ hat, um etwa zu entscheiden, dass ein Bild einen Vogel oder eine kranke Zelle enthält. Bestehende CAM‑Methoden stützen sich oft auf einfache, erstordnungs Gradientensignale innerhalb des Netzes. Diese Signale können verrauscht sein oder „sättigen“, das heißt, sie verändern sich nicht mehr, obwohl Detailunterschiede weiterhin relevant sind. Infolgedessen können Heatmaps große Hintergrundflächen hervorheben, feine Details übersehen oder inkonsistente Erklärungen über verschiedene Schichten hinweg liefern.
Ein sanfterer, zweiter Blick darauf, was das Netz sieht
Die Autoren schlagen Smooth Second-Order Gradient CAM, kurz SSG–CAM, vor. Anstatt sich nur auf den ersten Gradientenschub zu verlassen, betrachtet SSG–CAM auch, wie sich diese Gradienten selbst verändern – die Informationen zweiter Ordnung. Diese zusätzliche Sensibilität hilft zu offenbaren, auf welche Merkmale die Entscheidung des Netzes wirklich beruht, und verringert das Risiko, dass wichtige Hinweise ausgewaschen werden. Um zufälliges Rauschen zu dämpfen, glättet SSG–CAM die Gradienten vorsichtig mit einem Gauß‑Filter, ähnlich dem Weichzeichnen einer Kamera, das Sprenkel entfernt und Formen erhält. Schließlich kombiniert es die geglätteten Erst‑ und Zweitordnungs‑Signale so, dass starke, verlässliche Antworten betont und schwache oder inkonsistente unterdrückt werden, was sauberere, fokussiertere Heatmaps ergibt.
Algorithmen die besten Schichten auswählen lassen
Tiefe Netze arbeiten nicht in einem einzigen Schritt: frühe Schichten erfassen Kanten und Texturen, während tiefere Schichten ganze Objekte oder Konzepte kodieren. Viele CAM‑Methoden versuchen, Informationen aus mehreren Schichten zu verschmelzen, oft jedoch mit manuell gewählten oder festen Regeln. Die Studie zeigt, dass das naive Zusammenstapeln aller Schichten die Leistung tatsächlich verschlechtern kann, weil niedrigstufiges Rauschen die finale Erklärung verwischt. Um dies zu lösen, koppeln die Autoren SSG–CAM mit einer Optimierungsstrategie namens Differential Evolution und schaffen so das DE–SSG–CAM‑Framework. Dieser Algorithmus durchsucht automatisch Kombinationen von Merkmalsschichten und einigen Schlüsselparametern, um die Mischung zu finden, die am besten zu realen Objektformen in einem kleinen beschrifteten Satz passt. Einmal gefunden, lassen sich diese Einstellungen wiederverwenden und liefern starke Mehrschicht‑Erklärungen ohne aufwändige manuelle Feinabstimmung.
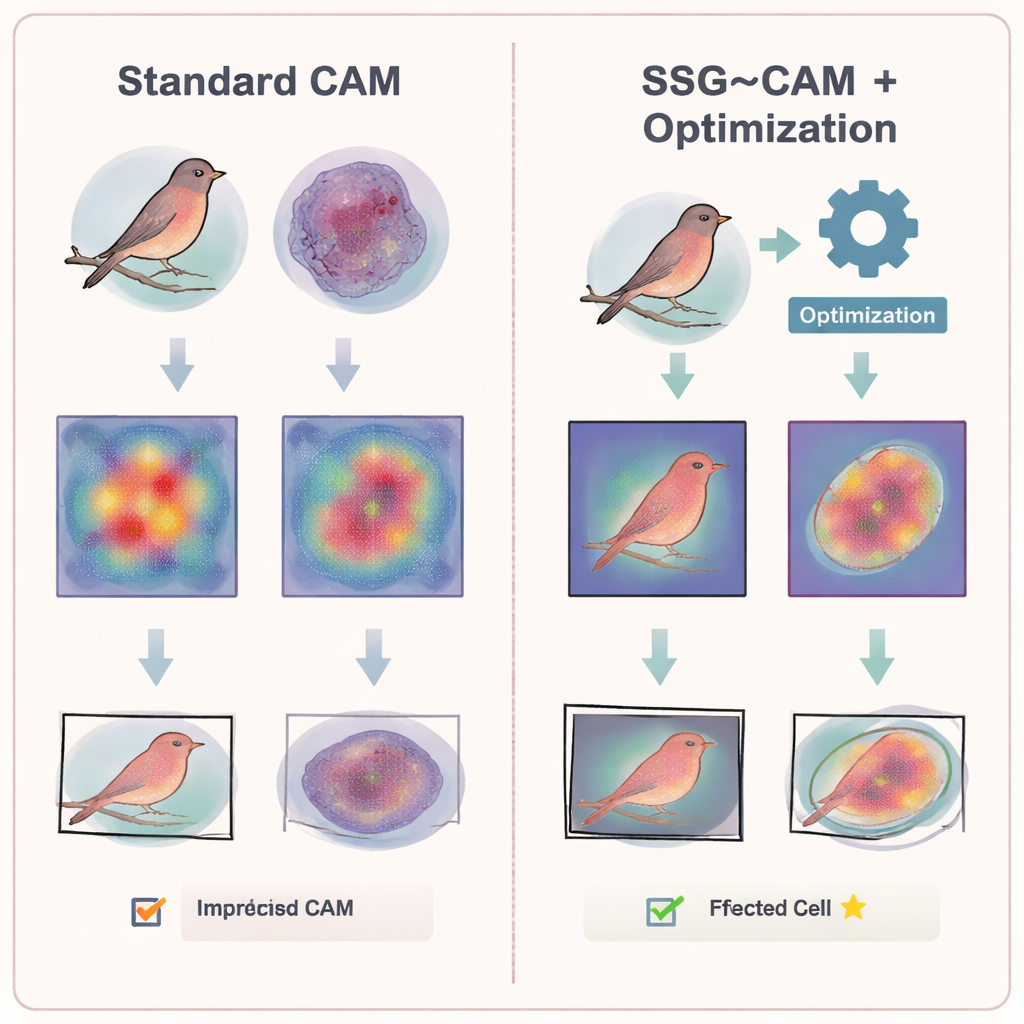
Methoden einer Prüfung unterzogen
Die Forschenden unterzogen SSG–CAM und DE–SSG–CAM einer Reihe anspruchsvoller Tests. Auf gängigen Bildbenchmarks verbesserte die neue Methode die schwach überwachte Objektlokalisierung – das Ziehen von Begrenzungsrahmen um Objekte nur mit Bild‑Level‑Labels – gegenüber mehreren populären CAM‑Varianten. Sie steigerte auch die Leistung bei schwach überwachten semantischen Segmentierungsaufgaben, bei denen das Modell jeden Pixel kennzeichnen muss, ohne detaillierte Trainingsmasken. In einem „Bild‑Perturbations“-Experiment wurden die von jeder Methode hervorgehobenen Regionen unscharf gemacht. Als die Bereiche, die SSG–CAM auswählte, entfernt wurden, sank die Genauigkeit des Netzes am stärksten, was darauf hindeutet, dass diese hervorgehobenen Regionen tatsächlich kritisch für die Entscheidung des Modells waren und keine bloßen dekorativen Hotspots.
Winzige Parasiten in Blutzellen finden
Die eindrücklichste Anwendung stammt aus der biomedizinischen Bildgebung. Die Autoren nutzten ihren Ansatz, um Malaria‑Parasiten in Bildern roter Blutkörperchen zu lokalisieren, eine Aufgabe, bei der die infizierten Bereiche winzig und unregelmäßig sein können. Unter Verwendung nur von Bild‑Level‑Infektionslabels für das Training erzeugte DE–SSG–CAM Pseudo‑Masken, die mit Expertenumrissen eng übereinstimmten und einen mittleren Intersection-over-Union‑Wert (mIoU) von 62,38 % erreichten — ein starkes Ergebnis für ein so herausforderndes, schwach beschriftetes Problem. Das Framework übertrug sich außerdem gut auf einen anderen Netzwerktype, ResNet34, was zeigt, dass die Technik nicht an eine einzige Architektur gebunden ist und sich über verschiedene Designs hinweg anpasst.
Was das für Anwenderinnen und Anwender bedeutet
Für Nicht‑Fachleute ist die Kernbotschaft, dass diese Methoden die „Begründung“ von KI sichtbarer und vertrauenswürdiger machen. SSG–CAM liefert schärfere, weniger verrauschte Heatmaps, die besser mit dem übereinstimmen, was Menschen als das eigentliche Objekt oder die Läsion ansehen würden, während DE–SSG–CAM automatisch lernt, wie Informationen aus verschiedenen Netzwerktiefen zu kombinieren sind. Zusammen rücken sie visuelle Erklärungen einen Schritt näher an etwas, auf das Ärzte, Ingenieure und Regulierungsbehörden sich verlassen können, wenn sie fragen: „Warum hat das Modell gesagt, dieses Bild zeige eine Krankheit — oder eine Gefahr?“
Zitation: Chen, Z., Zhang, Y.J., Pan, L. et al. SSG–CAM: enhancing visual interpretability through refined second-order gradients and evolutionary multi-layer fusion. Sci Rep 16, 6848 (2026). https://doi.org/10.1038/s41598-026-37278-4
Schlüsselwörter: erklärbare KI, Class-Activation-Maps, Visualisierung tiefer Lernmodelle, medizinische Bildanalyse, Objektlokalisierung