Clear Sky Science · de
Ein hybrider Rahmen zur Merkmalsauswahl und Interpretierbarkeit zur Vorhersage gelöster Sauerstoffgehalte in Trinkwasseraufbereitungsanlagen
Warum Sauerstoff im Trinkwasser wichtig ist
Gelöster Sauerstoff — die winzigen Bläschen von Sauerstoffgas, die im Wasser gelöst sind — bestimmt still und entscheidend, ob unser Trinkwasser klar, sicher und geschmacklich einwandfrei bleibt. Zu wenig Sauerstoff im Rohwasser kann Metalle wie Eisen und Mangan lösen, schädliche Mikroben begünstigen und die Aufbereitung schwieriger und teurer machen. Diese Studie zeigt, wie der intelligente Einsatz realer Betriebsdaten und moderner Methoden des maschinellen Lernens die Sauerstoffwerte in einer großen Trinkwasseraufbereitungsanlage vorhersagen kann. Das hilft den Betreiberinnen und Betreibern, die Wasserqualität hoch zu halten und gleichzeitig Zeit, Energie und Laborkosten zu sparen.
Lebensraum für die Wasseraufbereitung
In vielen Talsperren und Flüssen schwanken die Sauerstoffwerte mit den Jahreszeiten, durch Verschmutzung und durch die Wasserbewegung. Wird das Wasser stagnierend oder mit Nährstoffen überladen, kann der Sauerstoff sinken, was Bedingungen schafft, die unerwünschte Stoffe aus Sedimenten freisetzen und problematische Mikroben fördern. In Trinkwasseraufbereitungsanlagen ist die Aufrechterhaltung gesunder Sauerstoffwerte besonders wichtig für biologische Filter und zur Verhinderung der Freisetzung von Metallen und anderen schwer zu entfernenden Verbindungen. Die meisten früheren Studien konzentrierten sich jedoch auf Flüsse oder Abwasseranlagen und lassen damit eine Wissenslücke für behandelte Trinkwassersysteme bestehen, in denen Prozessschritte wie Flockung, Filtration und Chlorung das Sauerstoffverhalten auf besondere Weise verändern.
Ein Jahrzehnt an Daten von Fluss bis Zapfstelle
Die Forschenden griffen auf zehn Jahre täglicher Aufzeichnungen einer großtechnischen Wasseraufbereitungsanlage in Ahvaz, Iran, zurück, die Wasser aus dem Karun-Fluss für etwa 450.000 Menschen aufbereitet. Sie nutzten sieben routinemäßig gemessene Eigenschaften des filtrierten Zulaufwassers — historischer gelöster Sauerstoff, Nitrit, Chlorid, elektrische Leitfähigkeit, Trübung, pH und Temperatur — um den Sauerstoffgehalt im Auslassbecken der Anlage vorherzusagen. Nach sorgfältiger Prüfung der Daten, dem Umgang mit Ausreißern und der Standardisierung der Messwerte trainierten sie zwei verbreitete baumbasierte Modelle des maschinellen Lernens: Random Forest und XGBoost. Diese Modelle lernen Muster, indem sie viele Entscheidungsbäume erstellen und deren Ergebnisse kombinieren, wodurch sie komplexe, nichtlineare Zusammenhänge erfassen können, ohne handgefertigte Gleichungen zu benötigen. 
Die Signale finden, die am meisten zählen
Eine zentrale Herausforderung bestand darin, zu entscheiden, welche der sieben Eingangsgrößen das Sauerstoffverhalten wirklich treiben und welche nur Rauschen oder unnötige Komplexität hinzufügen. Anstatt einer einzigen Rangfolge zu vertrauen, entwickelte das Team eine „hybride“ Auswahl-Pipeline, die die Daten aus mehreren Blickwinkeln betrachtete. Die Mutual Information hob Variablen hervor, die am stärksten mit dem Sauerstoff verbunden sind, die Mean Decrease in Impurity zeigte, welche Messgrößen innerhalb der Bäume am nützlichsten waren, und die Permutation Importance testete, wie sehr die Vorhersagen sich verschlechterten, wenn die Werte einer Variablen durcheinandergebracht wurden. Darüber hinaus erklärte die SHAP-Methode jeweils für einzelne Fälle, wie jedes Merkmal die Prognose nach oben oder unten beeinflusste, und lieferte so sowohl globale als auch fallbezogene Einsichten. Über alle vier Techniken hinweg hoben sich drei Eingaben klar hervor: der Sauerstoffwert des Vortags, die Wassertemperatur und die Trübung. Größen wie pH und Nitrit, zwar wissenschaftlich relevant, trugen in dieser Anlage wenig zur Verbesserung der Vorhersagen bei.
Genaue Vorhersagen mit schlankeren Modellen
Indem sie sich auf die informativsten Eingaben konzentrierten und die am wenigsten nützlichen fallen ließen, reduzierten die Forschenden die Modellkomplexität um bis zu 70 Prozent, ohne die Genauigkeit wesentlich zu beeinträchtigen. Sowohl Random Forest als auch XGBoost reproduzierten die gemessenen Sauerstoffwerte am Auslass mit hoher Präzision, erklärten mehr als 93 Prozent der Variation und hielten typische Fehler unter 0,3 Milligramm pro Liter — also gut innerhalb des Bereichs, der für den täglichen Anlagenbetrieb nützlich ist. XGBoost schnitt insgesamt etwas besser ab, doch beide Modelle blieben robust, selbst wenn der Eingangsvariablensatz reduziert wurde. Diese Effizienz ist in der Praxis wichtig: Weniger erforderliche Messungen bedeuten geringere Überwachungskosten und schnellere, verlässlichere Vorhersagen, die in die Anlagensteuerung integriert werden können. 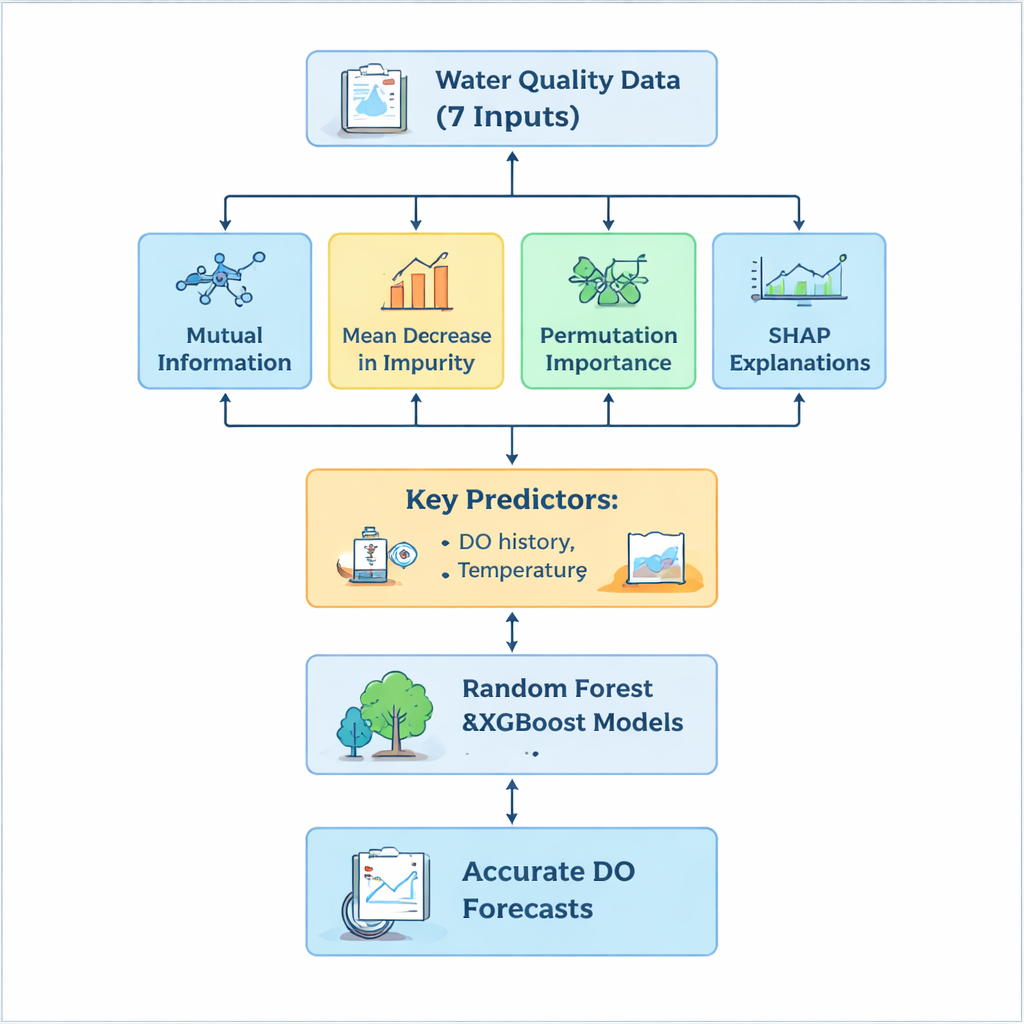
Was das für sicheres, effizientes Trinkwasser bedeutet
Für Nicht-Spezialistinnen und Nicht-Spezialisten ist die Schlussfolgerung einfach: Indem verschiedene datengestützte Methoden darüber „abstimmen“, welche Messgrößen am wichtigsten sind, können Betreiber kompakte, transparente Vorhersagetools bauen, die den gelösten Sauerstoff in Echtzeit zuverlässig prognostizieren. Das Vorauswissen darüber, wann der Sauerstoff möglicherweise absinken wird, erlaubt es einer Anlage, die Belüftung feinzujustieren, Filter zu schützen und Bedingungen zu vermeiden, die Metalle freisetzen oder schädliche Mikroben begünstigen — und das alles ohne übermäßigen Einsatz von Energie und Chemikalien. Über diese einzelne Anlage und Kenngröße hinaus lässt sich derselbe hybride Ansatz auf andere Umweltfragen anwenden, vom Nachverfolgen von Schadstoffen bis zur Vorhersage von Algenblüten, und bietet klarere und verlässlichere Orientierung dort, wo Wasserqualität und öffentliche Gesundheit zusammentreffen.
Zitation: Hoshyarzadeh, R., Hafshejani, L.D., Tishehzan, P. et al. A hybrid framework of feature selection and interpretability for dissolved oxygen prediction in drinking water treatment plants. Sci Rep 16, 6912 (2026). https://doi.org/10.1038/s41598-026-37276-6
Schlüsselwörter: gelöster Sauerstoff, Trinkwasseraufbereitung, maschinelles Lernen, Merkmalsauswahl, Wasserqualitätsüberwachung