Clear Sky Science · de
Die Auswirkung der K‑Wahl bei K‑facher Kreuzvalidierung auf Verzerrung und Varianz in überwachten Lernmodellen
Warum es wirklich wichtig ist, Ihr Modell zweimal zu prüfen
Von medizinischer Diagnose bis zur Bonitätsprüfung hängen viele Entscheidungen heute von maschinellen Lernmodellen ab, die an Vergangenheitsdaten trainiert wurden. Aber woran erkennen wir, ob ein Modell, das auf unserem Bildschirm gut aussieht, sich auch bei neuen, ungesehenen Fällen bewähren wird? Eine gängige Methode, Modelle „zu testen“, ist die K‑fache Kreuzvalidierung, bei der die Daten wiederholt in Trainings‑ und Testteile aufgeteilt werden. Diese Studie stellt eine auf den ersten Blick einfache, aber entscheidende Frage: Wie viele Teile — wie groß sollte k sein — und wie beeinflusst diese Wahl still und heimlich die Zuverlässigkeit der gemeldeten Leistungskennzahlen?
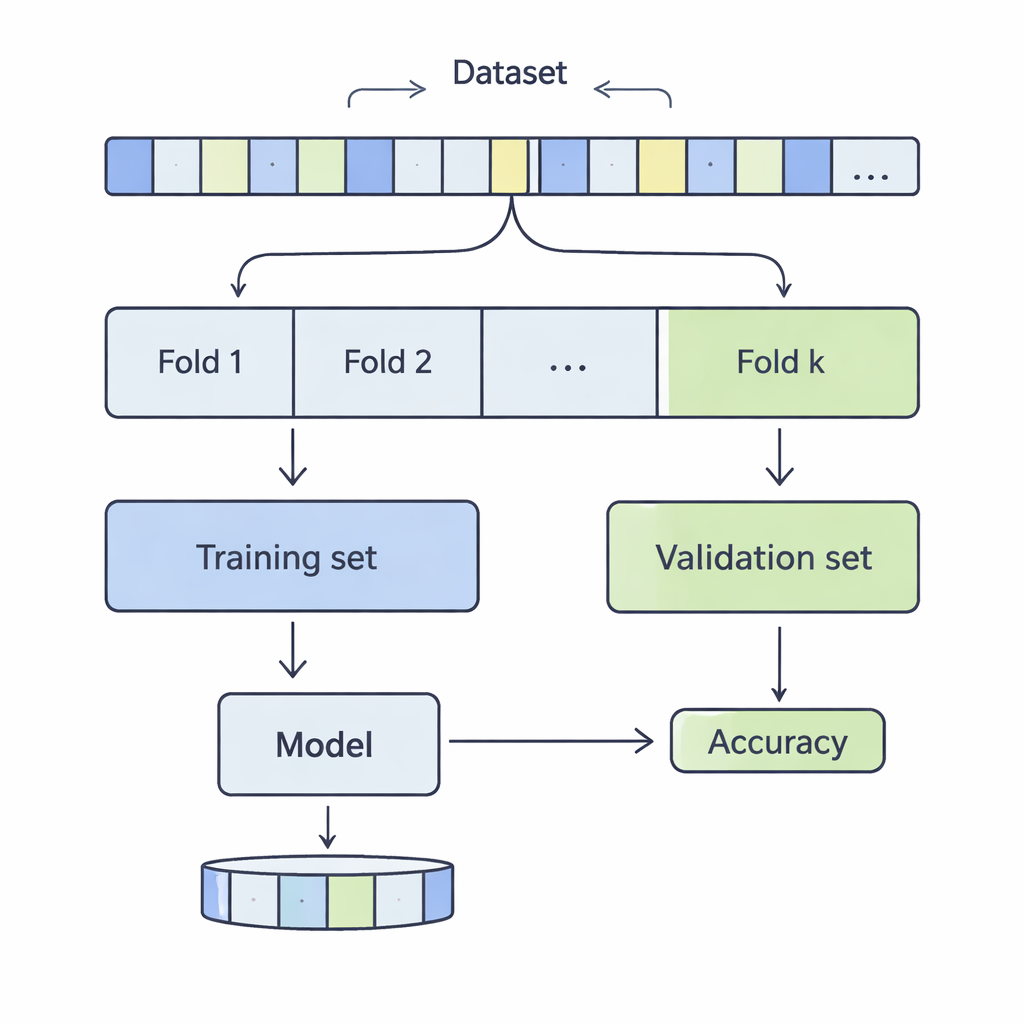
Wie die Daten für einen Realitätscheck aufgeteilt werden
Bei der K‑fachen Kreuzvalidierung werden Datensätze gemischt und in k gleich große Teile, sogenannte Folds, geteilt. Das Modell wird auf k‑1 dieser Folds trainiert und auf dem verbleibenden Fold bewertet; dieser Vorgang wiederholt sich, bis jeder Fold einmal als Testanteil fungiert hat. Die Autor:innen untersuchten k‑Werte von 3 bis 20 über 12 reale Datensätze mit Größen von wenigen tausend bis über einer halben Million Einträgen, aus Bereichen wie Einkommensvorhersage, medizinischen Ergebnissen, Cyberangriffen, Spielen und Weinqualität. Sie wendeten vier gebräuchliche Klassifikationsverfahren an — Support Vector Machines, Entscheidungsbäume, logistische Regression und k‑Nearest Neighbours — und maßen sorgfältig, wie die Wahl von k zwei zentrale Leistungsaspekte beeinflusste: Verzerrung (Bias) und Varianz.
Was Bias und Varianz im Alltag bedeuten
Bias beschreibt hier, wie viel besser das Modell in der Kreuzvalidierung zu erscheinen scheint im Vergleich zu seiner Leistung auf einem separaten, unberührten Testset. Ein hoher positiver Bias bedeutet, dass das Modell während der Validierung übermäßig optimistisch wirkt — ähnlich einem Schüler, der die Übungstests besteht, aber in der echten Prüfung strauchelt. Varianz spiegelt wider, wie stark die Leistung des Modells von Fold zu Fold schwankt: Niedrige Varianz bedeutet, dass die Werte über verschiedene Datenschnitte hinweg stabil sind, hohe Varianz bedeutet starke Ausschläge. Idealerweise wollen wir sowohl Bias als auch Varianz niedrig halten, damit die gemeldete Genauigkeit zugleich realistisch und stabil ist.
Was passiert, wenn wir die Anzahl der Folds erhöhen
Über alle zwölf Datensätze und alle vier Algorithmen hinweg zeichnete sich ein deutliches Muster ab: Mit wachsendem k stieg die Varianz fast ausnahmslos an. Anders gesagt machte ein größeres k die gemeldete Genauigkeit weniger stabil von Fold zu Fold. Das widerspricht der verbreiteten Annahme, mehr Folds würden automatisch bessere, verlässlichere Schätzungen liefern. Der Grund ist, dass bei großem k jeder Validierungs‑Slice sehr klein und weniger repräsentativ wird, sodass die Ergebnisse empfindlicher auf Zufälligkeiten in den Daten reagieren. Gleichzeitig zeigte der Bias kein einheitliches Verhalten. Bei k‑Nearest Neighbours und Support Vector Machines neigte der Bias dazu, mit zunehmendem k zu steigen, was bedeutet, dass diese Modelle in der Kreuzvalidierung oft genauer erschienen, als sie auf dem zurückgehaltenen Testset tatsächlich waren. Entscheidungsbäume zeigten ungefähr ausgeglichene Muster, und die logistische Regression lag dazwischen mit gemischten, aber moderateren Bias‑Änderungen.
Warum die „Standard‑Einstellungen“ irreführend sein können
Die meisten praxisorientierten Leitfäden empfehlen einfach, fünf oder zehn Folds zu verwenden, unabhängig von Datensatz oder Lernalgorithmus. Die Analyse der Autor:innen zeigt, dass solche Einheitsratschläge in die Irre führen können. Bei einigen Datensätzen und Modellen verstärkten höhere k‑Werte übermäßig optimistische Eindrücke der Leistungsfähigkeit; bei allen untersuchten Fällen führte ein größeres k zu mehr Variabilität in den Schätzungen. Das ist besonders bedenklich in Bereichen mit hohen Einsätzen wie Gesundheitswesen, Finanzen oder Infrastruktur, wo falsches Vertrauen in die Genauigkeit eines Modells reale Konsequenzen haben kann. Die Studie argumentiert, dass die Effekte von k sowohl von der Natur der Daten (klein vs. groß, verrauscht vs. sauberer) als auch davon abhängen, wie der jeweilige Algorithmus aus wiederholt sehr ähnlichen Trainingsmengen lernt.
Kernergebnis für alle, die maschinelles Lernen nutzen
Die zentrale Lehre ist, dass die Anzahl der Folds in der Kreuzvalidierung kein harmloses technisches Detail ist — sie bestimmt direkt, wie vertrauenswürdig Ihre Genauigkeitsangaben sind. In diesen Experimenten machten mehr Folds die Ergebnisse konsequent wackliger und ließen einige Modelle oft besser erscheinen, als sie tatsächlich waren. Anstatt blind k=5 oder k=10 zu wählen, empfehlen die Autor:innen, k als Abstimmungsparameter zu behandeln: prüfen Sie, wie sich die Ergebnisse über einen kleinen Bereich von k‑Werten ändern, und betrachten Sie, wenn möglich, mehr als nur eine Leistungsmetrik. Für Praktiker und interessierte Leser ist die Botschaft klar: Beim Bewerten von Modellen des maschinellen Lernens kann die Art, wie Sie die Daten aufteilen, fast genauso wichtig sein wie das Modell selbst.
Zitation: Abedin, T., Xu, H. & Uddin, S. The impact of K selection in K‑fold cross-validation on bias and variance in supervised learning models. Sci Rep 16, 6084 (2026). https://doi.org/10.1038/s41598-026-37247-x
Schlüsselwörter: K‑fache Kreuzvalidierung, Bias‑Varianz‑Trade‑off, Modellbewertung, Validierung im maschinellen Lernen, überwachte Klassifikation