Clear Sky Science · de
Ein neuartiger Hybridansatz zur Dürrenprognose: Nutzung von Feature-Engineering und Ensemble-Methoden
Warum die Vorhersage von Trockenperioden wichtig ist
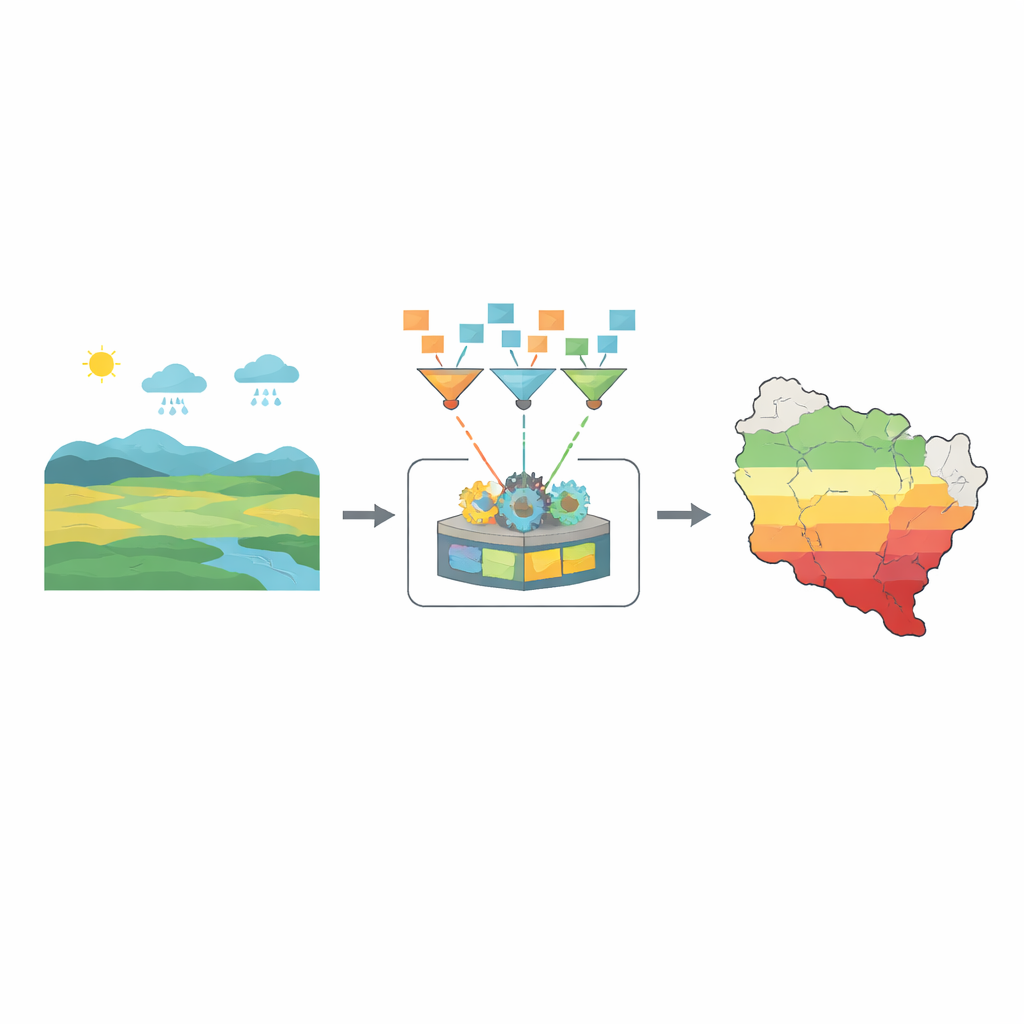
Dürren schleichen sich langsam an, können aber Ernten, Trinkwasserversorgung und ganze lokale Volkswirtschaften vernichten. Da der Klimawandel das Wetter unberechenbarer macht, brauchen Gemeinschaften Frühwarnungen, die über einfache Schätzungen des Niederschlags hinausgehen. Dieses Papier stellt eine neue Methode vor, um die Schwere von Dürren vorherzusagen, indem intelligente Kombinationen aus Mathematik und maschinellem Lernen Landwirtinnen, Planern und Behörden ein klareres Bild der kommenden Entwicklungen liefern.
Von wechselndem Himmel zu nutzbaren Signalen
Die Studie beginnt mit einer einfachen Erkenntnis: Das heutige Klima ist unübersichtlich. Temperaturschwankungen, veränderte Winde und ungleichmäßige Niederschläge folgen nicht mehr sauberen statistischen Mustern. Traditionelle Prognoseinstrumente haben Schwierigkeiten mit dieser Komplexität. Die Autorinnen und Autoren greifen stattdessen auf große Sammlungen von Wetter- und Landschaftsdaten zurück, darunter Niederschlag, Temperatur, Luftfeuchtigkeit, Wind, Geländehöhe, Hangneigung, Bodenqualität und ein Vegetationsgesundheitsindex. Ihr Ziel ist es, diese Rohdaten in eine kleinere Anzahl aussagekräftiger Signale zu verwandeln, die beschreiben, wie nah eine Region an verschiedenen Dürrestufen ist — von gesunden Bedingungen bis zu extremer Wasserknappheit.
Die wenigen Zahlen wählen, die am meisten zählen
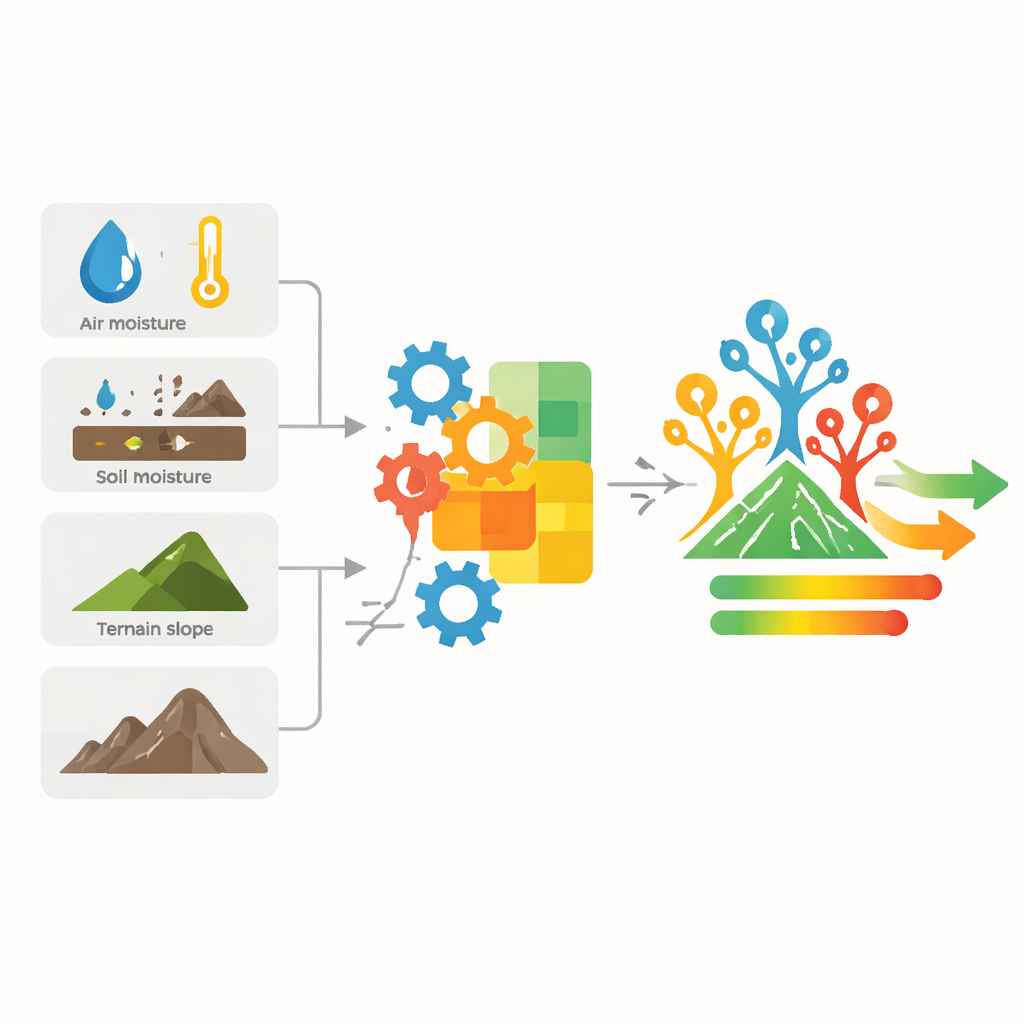
Nicht jede Messgröße ist gleichermaßen hilfreich. Ländernamen oder Verwaltungscodes zum Beispiel erklären kaum, warum Pflanzen vertrocknen. Das Team bereinigt zunächst die Daten und führt dann eine Korrelationsanalyse durch, um zu sehen, welche Faktoren gemeinsam variieren und welche tatsächlich helfen, nasse von trockenen Perioden zu unterscheiden. Sie finden heraus, dass bestimmte Merkmale herausstechen: ein Vegetationsindex, die Hangsteilheit in eine Richtung und drei bodennahe, feuchtigkeitsbezogene Temperaturen. Diese sorgfältig ausgewählten Eingangsgrößen bilden das Rückgrat des Vorhersagesystems.
Rohdaten in Dürren-Fingerabdrücke verwandeln
Anstatt diese fünf Eingangsgrößen einfach einem Algorithmus zu übergeben, entwerfen die Autorinnen und Autoren neue kombinierte Kennzahlen, die widerspiegeln, wie Dürre in der Natur tatsächlich funktioniert. Sie entwickeln einfache, aber aussagekräftige Formeln — unter Verwendung vertrauter Operationen wie Addition, Multiplikation, Quadratwurzeln und Logarithmen —, um Konzepte wie allgemeine Trockenheit, die hilfreiche Wirkung jüngerer Niederschläge, wie schnell Hitze Bedingungen in Richtung Dürre treibt, wie viel Wasser noch im Boden verbleibt und das Gleichgewicht zwischen zugewinnener Feuchte und Verdunstungsverlust zu erfassen. Jede Formel erzeugt einen neuen Index, der für jeden Ort und jede Woche im Datensatz wie ein Fingerabdruck aktuellen Dürrendrucks wirkt.
Ein Wald von Entscheidungen stimmt über das Ergebnis ab
Diese konstruierten Indizes werden anschließend einem maschinellen Lernverfahren namens Random Forest übergeben. Statt einer großen Entscheidungsregel wächst dieses Verfahren viele einfache Entscheidungsbäume, von denen jeder einen leicht anderen Ausschnitt der Daten sieht. Jeder Baum gibt seine Einschätzung ab, welchem Dürreniveau eine Situation zuzuordnen ist, und die finale Antwort des Waldes basiert auf Mehrheitsentscheid. Durch Feinabstimmung der Baumanzahl und der Tiefe, bis zu der jeder Baum die Daten aufspalten darf, finden die Forschenden einen Punkt, an dem das Modell sowohl genau als auch unempfindlich gegenüber Überanpassung ist. An gehaltenen Testdaten klassifiziert ihr hybrides System das Dürreniveau in fast allen Fällen korrekt und zeigt deutlich weniger Fehler als gebräuchlichere Werkzeuge wie k-nearest neighbors, Support Vector Machines oder einfache logistische Regression.
Was das für das Leben vor Ort bedeutet
Für Nichtfachleute lautet die Kernbotschaft: Eine kleine Anzahl gut gestalteter Indikatoren, die in dem verankert sind, wie Wärme und Feuchte tatsächlich interagieren, kann ein sehr zuverlässiges Frühwarnsystem antreiben. Durch die Kombination von leicht nachvollziehbaren Gleichungen mit einer abstimmungsbasierten Lernmethode erreicht das Modell hohe Genauigkeit, bleibt zugleich relativ ressourcenschonend zu betreiben und ist leichter zu interpretieren als viele Blackbox-Modelle des Deep Learning. Wenn dieser hybride Ansatz übernommen und an lokale Daten angepasst wird, könnte er Landwirtinnen helfen, Aussaattermine anzupassen, Wasserverwaltern bei Speicher- und Abgabemanagement unterstützen und Katastrophenschutzbehörden ermöglichen, sich auf eskalierende Trockenperioden vorzubereiten, bevor diese zu ausgewachsenen Krisen werden.
Zitation: Charjan, O., Gajbhiye, K., Warhade, J. et al. A Novel Hybrid Approach To Drought Forecasting: Leveraging Feature Engineering And Ensemble Methods. Sci Rep 16, 7972 (2026). https://doi.org/10.1038/s41598-026-37206-6
Schlüsselwörter: Dürrenprognose, Klima-Risiko, Maschinelles Lernen, Landwirtschaft, Frühwarnsysteme