Clear Sky Science · de
Expertenzuweisungssystem auf Basis der Verarbeitung natürlicher Sprache für Marie-Sklodowska-Curie-Maßnahmen
Warum die Wahl der richtigen Expertin bzw. des richtigen Experten wirklich zählt
Wenn tausende Forschungsanträge um begrenzte Mittel konkurrieren, hängt alles davon ab, wer sie bewertet. Wenn die zugewiesenen Expertinnen und Experten das Thema eines Antrags nicht wirklich verstehen, können vielversprechende Ideen missverstanden oder übersehen werden. Dieser Artikel untersucht, wie künstliche Intelligenz, insbesondere moderne sprachverarbeitende Systeme, dabei helfen kann, Anträge genauer und fairer als heutige keyword-basierte Werkzeuge den bestmöglichen Expertinnen und Experten zuzuordnen.
Das Problem mit Keyword-Checklisten
Bisher beruhte die Expertenzuweisung in großen europäischen Förderprogrammen wie den Marie-Skłodowska-Curie-Postdoktorandenstipendien stark auf Schlagwörtern. Die aktuelle Plattform durchsucht Antragsbeschreibungen und Gutachterprofile nach übereinstimmenden Begriffen und schlägt dann drei Expertinnen bzw. Experten plus Alternativen vor. Vice Chairs — erfahrene Wissenschaftlerinnen und Wissenschaftler, die den Prozess überwachen — ändern jedoch etwa 40 % dieser Zuweisungen. Dieses Ausmaß an menschlicher Korrektur macht das System arbeitsintensiv, langsam und relativ undurchsichtig, insbesondere da jährlich bis zu 10.000 Anträge eingehen, oft in neuen Gebieten, in denen starre Schlagwortlisten schlecht funktionieren.
Forschung wie ein Mensch lesen — in großem Maßstab
Die Autorinnen und Autoren entwickelten ein neues Zuweisungssystem, das versucht, Forschung eher so zu „lesen“, wie es ein menschlicher Experte tun würde. Anstatt sich auf Labels zu stützen, sammelt es die Publikationen jeder Expertin bzw. jedes Experten über ORCID, ein globales Forscheridentifikationssystem, und baut eine Datenbank mit mehr als 2.800 Artikelsummaries auf. Sowohl Antragsexposés als auch Publikationsabstracts werden dann von GALACTICA verarbeitet, einem großen Sprachmodell, das speziell auf wissenschaftliche Texte trainiert wurde. GALACTICA verwandelt jedes Abstract in einen numerischen Fingerabdruck, der seine Bedeutung erfasst, nicht nur die Wortwahl. Durch den Vergleich dieser Fingerabdrücke kann das System abschätzen, wie eng der Inhalt eines Antrags mit der früheren Arbeit einer Expertin bzw. eines Experten übereinstimmt.
Drei Wege, Expertise zusammenzufassen
Eine Herausforderung besteht darin, dass Expertinnen und Experten Dutzende von Publikationen haben können. Das System benötigt daher einen einzelnen Score pro Expertin/Experten und Antrag. Die Autorinnen und Autoren testeten drei einfache Methoden zur Kombination der Ähnlichkeitswerte. Die Summen-Strategie addiert alle Ähnlichkeitswerte und belohnt breite und wiederholte Relevanz. Die Produkt-Strategie multipliziert sie, was konsistente Ähnlichkeit über viele Publikationen betont, schwache Übereinstimmungen jedoch stark bestraft. Die Maximum-Strategie behält nur die stärkste Einzelübereinstimmung bei, in der Annahme, dass ein einziges sehr eng verwandtes Paper für eine Zuweisung ausreichen kann. Diese Scores werden dann verwendet, um 48 Kandidatinnen und Kandidaten für jeden der 181 Anträge zu rangieren, und die Rankings werden mit den finalen Expertinnen-/Expertenauswahlen der Vice Chairs verglichen.
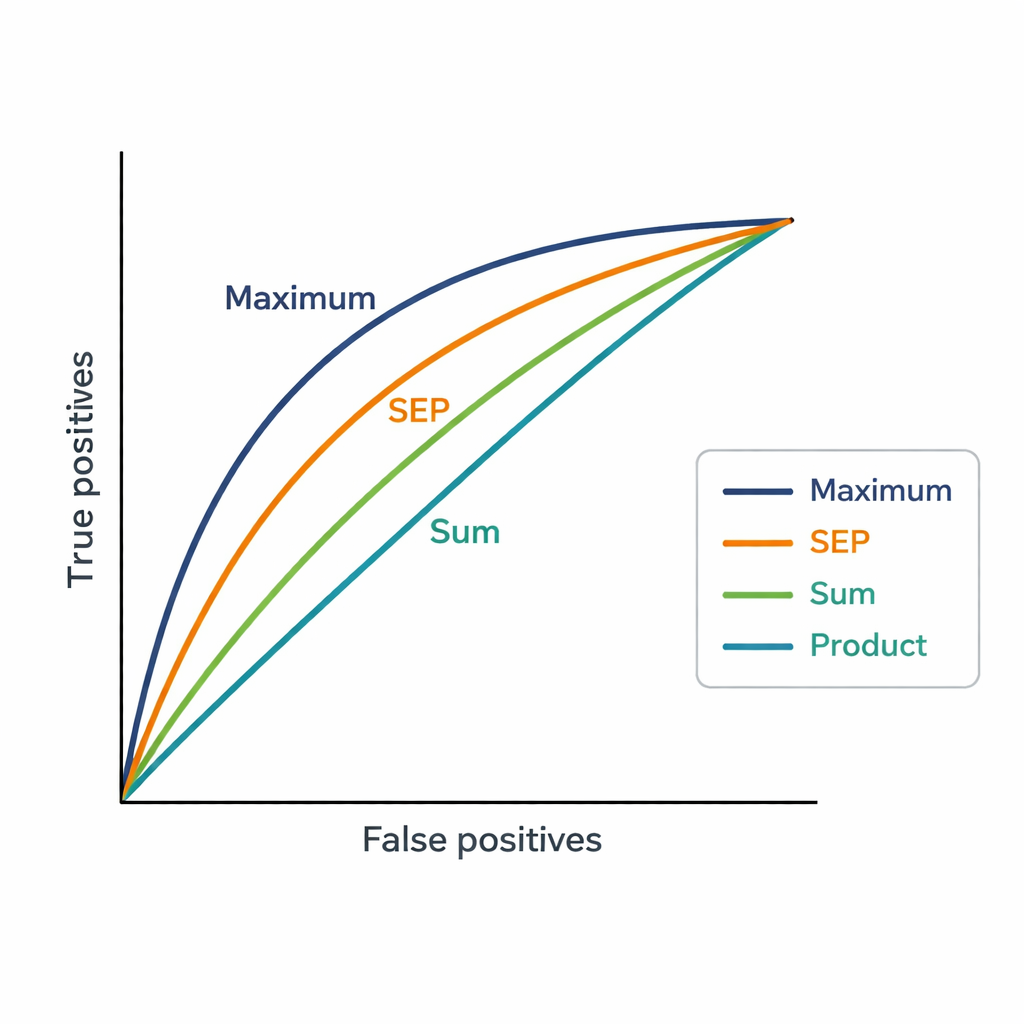
Was die Zahlen über menschliche Entscheidungen verraten
Die Maximum-Strategie stimmte am engsten mit den Entscheidungen der Vice Chairs überein und erreichte einen AUC-Wert von 0,82, besser als sowohl das bestehende keyword-basierte System (AUC 0,75) als auch die anderen Aggregationsmethoden. In der Praxis tauchte die von den Vice Chairs gewählte Expertin bzw. der gewählte Experte meist unter den vier besten Vorschlägen der Maximum-Methode auf. Das deutet darauf hin, dass Menschen bei der Zuweisung von Gutachterinnen und Gutachtern dazu neigen, darauf zu achten, ob es mindestens eine sehr starke Verbindung zwischen der früheren Arbeit einer Expertin bzw. eines Experten und einem Antrag gibt, anstatt zu verlangen, dass alle Publikationen der Expertin bzw. des Experten übereinstimmen. Die neue Methode erzeugt außerdem deutlich feinere Werte als die groben „Affinity“-Stufen der Plattform, was eine klarere Unterscheidung zwischen eng platzierten Expertinnen und Experten ermöglicht.
Was das für künftige Begutachtungen bedeutet
Für die interessierte Leserin bzw. den interessierten Leser ist die Schlussfolgerung klar: Durch den Einsatz von KI, die wissenschaftliche Sprache versteht, können Förderorganisationen Anträge besser mit den richtigen Expertinnen und Experten zusammenbringen, manuelle Korrekturen reduzieren und den Prozess konsistenter sowie transparenter gestalten. Unterschiedliche Methoden zur Zusammenführung von Evidenz aus Publikationen betonen verschiedene Aspekte von Expertise, doch die einfache Regel „beste Einzelübereinstimmung“ scheint das menschliche Entscheidungsverhalten gut abzubilden. Werden solche Systeme breiter getestet und mit neueren Sprachmodellen kombiniert, könnten sie weltweit zu einem zentralen Bestandteil fairerer und effizienterer Forschungsbewertungen werden.
Zitation: Álvarez-García, E., García-Costa, D., De Waele, I. et al. Expert assignment system based on natural language processing for Marie Sklodowska-Curie actions. Sci Rep 16, 6396 (2026). https://doi.org/10.1038/s41598-026-37115-8
Schlüsselwörter: Begutachtung, Expertenmatching, Forschungsförderung, Verarbeitung natürlicher Sprache, große Sprachmodelle