Clear Sky Science · de
Vergleichende Studie zur Vorhersage postoperativer Fernmetastasen beim Lungenkrebs basierend auf Machine-Learning-Modellen
Warum die Vorhersage der Krebsausbreitung wichtig ist
Lungenkrebs gehört nach wie vor zu den tödlichsten Krebsarten, selbst wenn Chirurgen alle sichtbaren Tumoren entfernen. Viele Patientinnen und Patienten entwickeln später verborgene Tumorherde, die im Gehirn, in Knochen, Leber oder anderen Organen auftreten. Ärztinnen und Ärzte möchten möglichst früh nach der Operation wissen, welche Patientinnen und Patienten wahrscheinlicher eine solche Fernmetastasierung entwickeln, um Nachsorgetermine und Behandlungen anzupassen. Diese Studie untersucht, ob moderne Computerprogramme, sogenannte Machine-Learning-Modelle, helfen können vorherzusagen, wer ein höheres Risiko hat, basierend auf Informationen, die Krankenhäuser bereits routinemäßig erfassen.
Genauer Blick auf viele Patientendaten
Die Forschenden untersuchten die Daten von 3.120 Personen mit Lungenkrebs im Stadium I bis III, denen die Tumoren in einem einzigen Krebszentrum in China entfernt worden waren. Alle hatten mindestens zwei Jahre Nachbeobachtung. Für jede Person sammelte das Team 52 Informationsarten, darunter Alter, Geschlecht, Körpergewicht, Raucheranamnese, Befunde aus Bildgebung, Operationsdetails, Laborwerte und ob nach der Operation zusätzliche Behandlungen wie Chemotherapie oder Strahlentherapie erfolgten. Im Verlauf entwickelten 596 dieser Patientinnen und Patienten Fernmetastasen, während 2.524 dies nicht taten. Diese realistische Mischung ermöglichte es dem Team, Merkmale zu identifizieren, die mit späterer Ausbreitung verknüpft waren.
Computern beibringen, Risikomuster zu erkennen
Statt sich auf eine einzige Formel zu verlassen, verglichen die Wissenschaftler neun verschiedene Machine-Learning-Methoden, von einfachen Entscheidungsbäumen bis zu fortgeschrittenen Techniken, die viele kleine Modelle kombinieren. Zunächst nutzten sie einen mathematischen Filter, um die ursprünglichen 52 Faktoren auf eine kleinere, aussagekräftigere Menge zu reduzieren. Dann trainierten sie in wiederholten Durchläufen jedes Modell an Teilen der Daten und testeten es an Patientinnen und Patienten, die das Modell zuvor noch nicht „gesehen“ hatte. Da nur etwa einer von fünf Patienten Metastasen entwickelte, passten sie das Training so an, dass das Programm nicht einfach für alle „niedriges Risiko“ vorhersagte. Die Bewertung erfolgte mit mehreren Kennzahlen, unter anderem wie gut die Modelle zwischen Hoch- und Niedrigrisikopersonen unterscheiden konnten und wie eng die vorhergesagten Risiken mit dem tatsächlich Beobachteten übereinstimmten.
Das zuverlässigste Modell finden
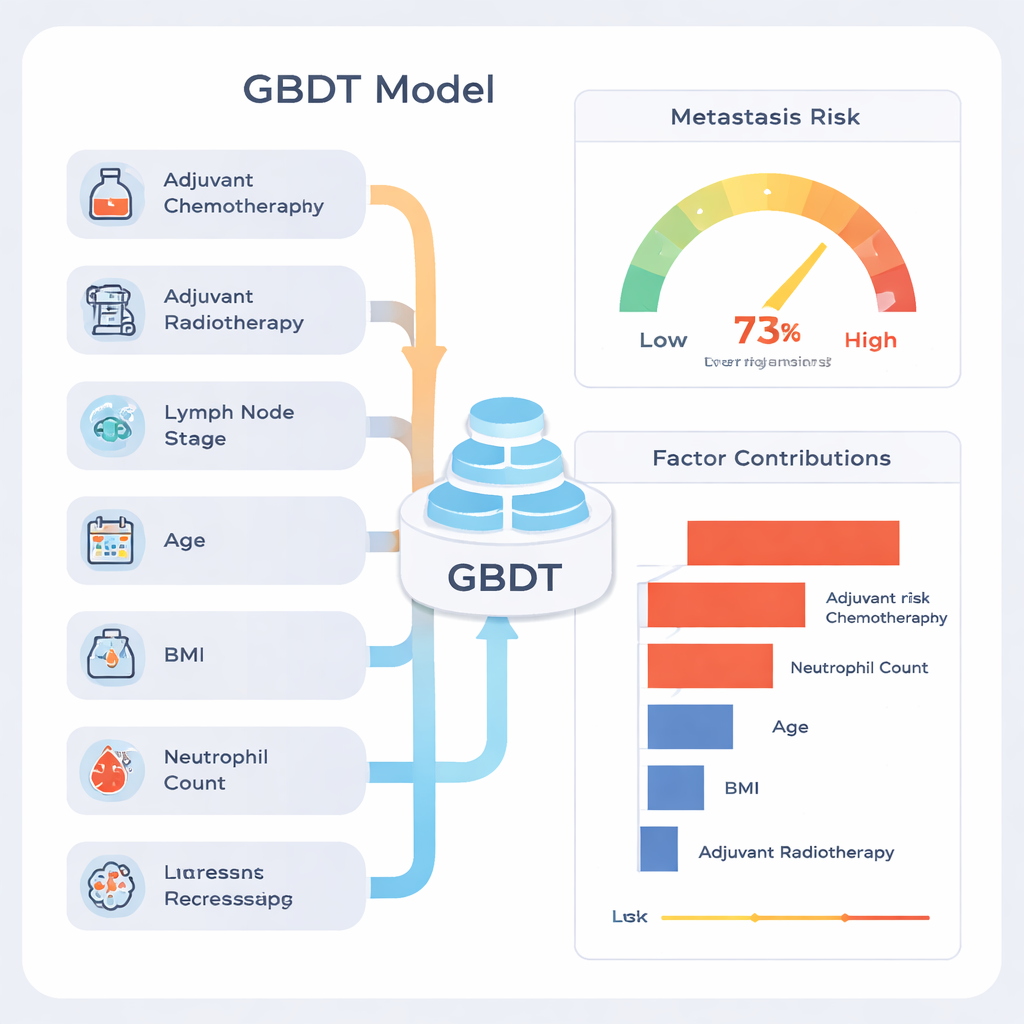
Unter den neun Ansätzen zeichnete sich ein Modell namens Gradient Boosting Decision Tree (GBDT) besonders aus. In den Testdaten ordnete es Patienten insgesamt mit einer Genauigkeit von etwa 77 % korrekt ein, und sein Kennwert für die Diskriminierung (die Fläche unter der ROC-Kurve) lag bei 0,81, was für medizinische Vorhersageinstrumente als stark gilt. Das Modell war besonders gut darin, Patientinnen und Patienten zu identifizieren, die metastasenfrei blieben (hoher „negativer prädiktiver Wert“), sodass ein niedriges Risiko in der Regel beruhigend war. Als das Team das Verhalten des Modells über viele verschiedene zufällige Aufteilungen der Daten hinweg untersuchte, blieb die Leistung stabil, was darauf hindeutet, dass es sich nicht nur Eigenheiten eines bestimmten Datensatzteils eingeprägt hatte.
Was die Entscheidungen des Modells antreibt
Ein häufiger Vorwurf gegenüber Machine Learning ist, dass es eine „Black Box“ sein kann. Um dem zu begegnen, verwendeten die Autorinnen und Autoren eine Erklärmethode namens SHAP, die jedem Faktor einen Beitrag zur finalen Risikoschätzung für jede Patientin und jeden Patienten zuweist. Diese Analyse zeigte, dass die stärksten Signale waren, ob die Person nach der Operation eine Chemotherapie oder Strahlentherapie erhielt, wie viele Lymphknoten Krebs enthielten, Alter, Body-Mass-Index (BMI) und die präoperative Neutrophilenzahl, eine Form der weißen Blutkörperchen. Patientinnen und Patienten mit stärkerer Lymphknotenbeteiligung und Zeichen systemischer Entzündung wiesen tendenziell ein höheres vorhergesagtes Risiko auf. Die Autorinnen und Autoren betonen, dass hohe Beiträge von Chemotherapie und Strahlentherapie nicht bedeuten, diese Behandlungen verursachten Metastasen; vielmehr sind sie Marker dafür, dass Ärztinnen und Ärzte bereits einen aggressiveren Krankheitsverlauf eingeschätzt hatten, sodass diese Personen von vornherein ein höheres Risiko aufwiesen.
Wie das Patienten in der Praxis helfen könnte
Da das Modell mit Informationen arbeitet, die die meisten Krebszentren bereits dokumentieren, könnte es nach weiteren Tests in Krankenhaussoftware integriert werden. Für eine neue Patientin oder einen neuen Patienten, der gerade eine Lungenoperation hinter sich hat, könnte das System die Daten abrufen und eine personalisierte Wahrscheinlichkeit für Fernmetastasen ausgeben, zusammen mit einer einfachen Erklärung, welche Faktoren das Risiko nach oben oder unten treiben. Klinikteams könnten dies nutzen, um zu entscheiden, wer engmaschigere bildgebende Kontrollen, zusätzliche Beratung oder die Einschreibung in Studien erhalten sollte und wer intensive Überwachung wahrscheinlich sicher vermeiden kann. Die Studie wurde an einem einzigen Krankenhaus durchgeführt, daher muss das Werkzeug noch in anderen Regionen und Gesundheitssystemen überprüft und angepasst werden. Dennoch bietet sie einen vielversprechenden Ansatz, routinemäßige klinische Daten mit transparentem Machine Learning zu verbinden, um die Langzeitversorgung von Menschen mit Lungenkrebs zu verbessern.
Zitation: Guo, X., Xu, T., Luo, Y. et al. Comparative study on predicting postoperative distant metastasis of lung cancer based on machine learning models. Sci Rep 16, 6468 (2026). https://doi.org/10.1038/s41598-026-37113-w
Schlüsselwörter: Lungenkrebs, Fernmetastasen, Machine Learning, Risikovorhersage, postoperative Nachsorge