Clear Sky Science · de
Innovative zeitliche Zusammenfassung für komplexe Videoklassifikation
Warum intelligentere Videozusammenfassungen wichtig sind
Von Sicherheitskameras bis zu Streaming-Plattformen wird mehr Video aufgezeichnet, als Menschen oder Computer bequem verarbeiten können. Jede Sekunde Filmmaterial enthält Dutzende von Einzelbildern, doch viele davon sind nahezu identisch. Dieses Paper untersucht eine Methode, lange Videos auf die aussagekräftigsten Momente zu reduzieren, sodass Computer weiterhin Aktionen wie Kochen, Sport treiben oder mit einem Hund spazierengehen erkennen können — bei deutlich geringerem Zeit-, Speicher- und Energieaufwand. Solche Fortschritte könnten leistungsfähige Videoanalyse auf alltägliche Geräte bringen, von Haushaltsrobotern bis zu tragbaren Kameras.

Von endlosen Frames zu Schlüsselmomenten
Traditionelle Systeme zur Videoklassifikation versuchen, zu erkennen, was in einem Clip passiert — etwa Gemüse schneiden oder einen Basketball werfen — indem sie lange Bildfolgen in schwere Deep‑Learning‑Modelle einspeisen. Diese Modelle müssen sowohl das Aussehen (wie Dinge aussehen) als auch die zeitliche Abfolge (wie sie sich bewegen) verarbeiten. Die Verarbeitung aller Frames führt zu großen Datensätzen, hohem Speicherbedarf sowie langsamer, energieintensiver Berechnung. Die Autoren argumentieren, dass viele dieser Frames redundant sind: Wenn sich vom einen Frame zum nächsten nichts Wesentliches ändert, bringt die Analyse beider nur wenig. Die zentrale Idee des Papiers ist es, eine deutlich kleinere Menge von „Schlüsselbildern“ auszuwählen, die dennoch die wichtigen Änderungen in der Szene erfassen.
Veränderung zwischen Frames messen
Um diese Schlüsselmomente zu finden, entwerfen und vergleichen die Forschenden mehrere Methoden, um zu messen, wie stark sich ein Frame von einem anderen unterscheidet. Statt sich nur auf die klassische euklidische Distanz zu stützen, die alle Pixel gleich bewertet, prüfen sie Alternativen, die sensibler auf strukturelle Veränderungen reagieren. Ihr Hauptvorschlag, die sogenannte „Norm der Zeilen“-Distanz, konzentriert sich auf die größten Unterschiede entlang jeder Pixelzeile und nimmt dann die ausgeprägteste Zeile als Maß für die Veränderung zwischen zwei Frames. Sie untersuchen außerdem spaltenbasierte Distanzen und Methoden, die auf Eigenwerten von Matrizen beruhen, welche zusammenfassen, wie sich Pixeldifferenzen verteilen. Alle diese Ansätze zielen darauf ab, bedeutende Bewegungen oder Szenenwechsel besser zu erkennen, etwa eine Hand, die nach einem Utensil greift, oder einen Spieler, der springt.
Wie die Zusammenfassungspipeline funktioniert
Der Zusammenfassungsprozess beginnt mit dem allerersten Frame eines Videos, der als initiales Schlüsselbild behandelt wird. Das System vergleicht dieses Schlüsselbild dann mit jedem nachfolgenden Frame mithilfe einer der Distanzmaße. Sobald die Distanz einen gewählten Schwellenwert überschreitet, wird der entsprechende Frame als neues Schlüsselbild markiert, was anzeigt, dass sich visuell etwas Wichtiges geändert hat. Das Verfahren wiederholt sich dann mit diesem neuen Schlüsselbild als Referenz, schreitet durch das Video und sammelt eine Kette repräsentativer Momentaufnahmen. Durch Anpassung des Schwellenwerts kann die Methode so wenig wie 20 Prozent oder so viel wie 80 Prozent der ursprünglichen Frames behalten und damit zwischen Kompaktheit und Detailtreue abwägen. Diese zusammengefassten Sequenzen werden anschließend an einen standardmäßigen Deep‑Learning‑Klassifikator übergeben, der ein leistungsfähiges Bildnetz (ResNet‑50) mit einem zeitlich sensiblen LSTM‑Modul kombiniert.
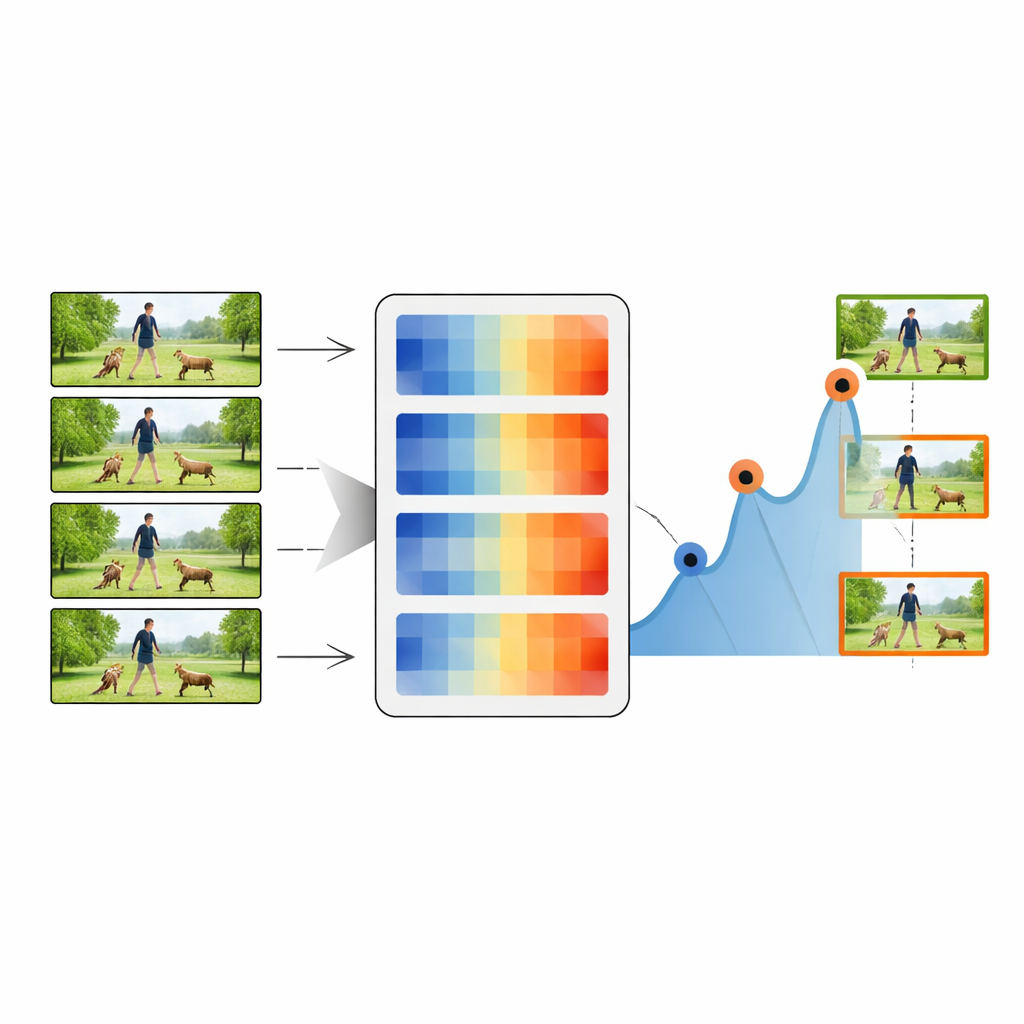
Die Methode im Test
Die Autoren bewerten ihren Ansatz sorgfältig auf vier bekannten Videosammlungen: alltägliche Küchenaktivitäten (MMAC), Sport und allgemeine Aktionen (UCF101 und UCF11) sowie variantenreichere, herausfordernde Clips (HMDB51). Über diese Benchmarks hinweg liefert die Norm‑der‑Zeilen‑Distanz durchgängig das beste Verhältnis von Geschwindigkeit und Genauigkeit. Mit nur etwa der Hälfte der Frames erreicht ihr System auf mehreren Datensätzen Klassifikationsgenauigkeiten über 90 Prozent — oft vergleichbar mit oder besser als komplexere Methoden, die vollständige, nicht zusammengefasste Videos verwenden. Sie messen außerdem, wie gut die Zusammenfassungen den Originalinhalt abdecken, wie redundant die ausgewählten Frames sind und wie vielfältig die erfassten Momente werden. Die vorgeschlagene Metrik erreicht hohe Abdeckung bei geringer Redundanz, was bedeutet, dass sie die Erzählung des Videos bewahrt, ohne ähnliche Frames zu wiederholen.
Schnellere Entscheidungen für reale Videos
Indem die Anzahl der Frames ungefähr halbiert wird, halbiert die Methode praktisch die Verarbeitungszeit auf Standard‑Hardware und erzielt weiterhin spürbare Beschleunigungen selbst auf modernen Grafikkarten. Für reale Systeme, die in Echtzeit reagieren müssen — wie Überwachung, autonome Roboter oder mobile Apps — ist diese Arbeitslastreduktion entscheidend. Die Studie zeigt, dass ein sorgfältig entworfener Distanzmaßstab als intelligenter Türsteher fungieren kann, der auswählt, welche Frames Aufmerksamkeit verdienen und welche sicher übersprungen werden können.
Schlussfolgerung für den Alltag
Einfach gesagt zeigt diese Arbeit, dass Computer nicht jeden einzelnen Frame sehen müssen, um zu verstehen, was in einem Video passiert. Indem sie sich auf die Momente konzentrieren, in denen sich das Bild wirklich verändert, und nahezu identische Frames ignorieren, bewahrt die vorgeschlagene Technik das Wesentliche einer Aktion und reduziert gleichzeitig die Datenmenge drastisch. Das macht hochwertige Videoverständnislösungen auf begrenzter Hardware praktikabler und ebnet den Weg für schnellere, effizientere Werkzeuge zur Analyse der wachsenden Flut visueller Informationen in unserem Alltag.
Zitation: Khan, A., Rahnama, A., Islam, A. et al. Innovative temporal summarization for complex video classification. Sci Rep 16, 7970 (2026). https://doi.org/10.1038/s41598-026-37111-y
Schlüsselwörter: Videoklassifikation, Videozusammenfassung, Auswahl von Schlüsselbildern, Aktionserkennung, Effizienz in der Computer Vision