Clear Sky Science · de
Erstellung und Anwendung eines Wissensgraphen für Saatgut-Qualitätsnormen
Warum Saatgutvorschriften für unsere gesamte Nahrungsmittelversorgung wichtig sind
Hinter jeder Tüte Reis oder jedem Paket Gemüsesaatgut steckt ein Geflecht technischer Normen, die Ernteerträge und Ernährungssicherheit stillschweigend schützen. Diese Regelwerke zur Saatgutqualität stecken jedoch meist in dichten PDF-Dokumenten, die für Landwirte, Aufsichtsbehörden und Unternehmen schwer durchschaubar und durchsuchbar sind. Die vorliegende Studie zeigt, wie sich diese statischen Dokumente in eine lebendige "Karte" vernetzter Fakten — einen Wissensgraphen — verwandeln lassen, um landwirtschaftliche Normen transparenter, durchsuchbarer und für das Zeitalter der digitalen Landwirtschaft brauchbar zu machen. 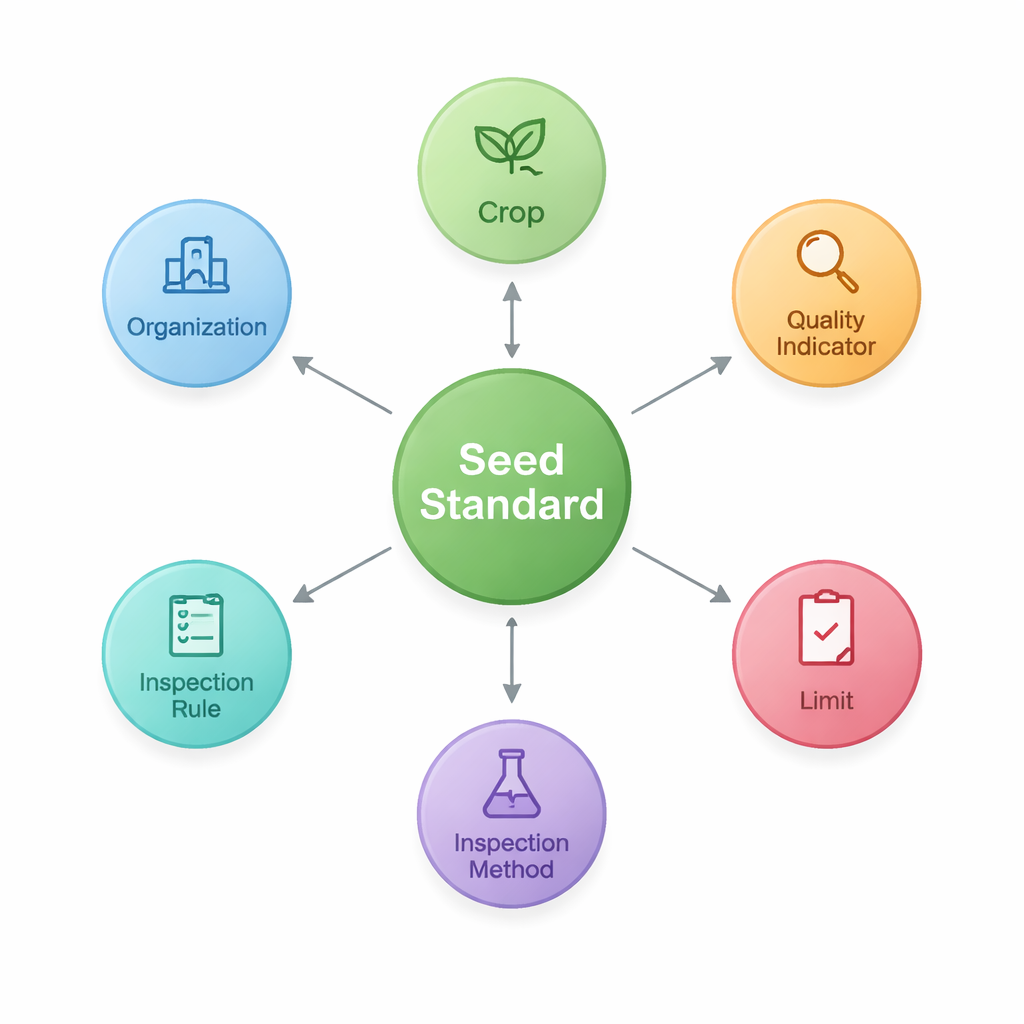
Von Papiernormen zu intelligenten Informationen
Saatgut-Qualitätsnormen legen fest, was als akzeptables Saatgut gilt: wie rein die Charge sein muss, wie viele Samen keimen sollten, wie viel Feuchtigkeit zulässig ist und welche Methoden zur Prüfung dieser Merkmale verwendet werden. In China hat die Anzahl solcher Dokumente stark zugenommen, viele existieren nach wie vor nur als gescannte Seiten oder unstrukturierter Text. Einfache Stichwortsuchen stoßen an ihre Grenzen bei praktischen Fragen wie "Welche Reinheitsgrenzen gelten für diese Kulturpflanze?" oder "Welche Regel hat eine ältere ersetzt?". Die Autoren argumentieren, dass diese Normen, um mit dem raschen Wandel in der Landwirtschaft Schritt zu halten, von rein menschenlesbaren Seiten zu maschinenverständlichem Wissen überführt werden müssen, das schnelle Abfragen, Vergleiche und automatisierte Prüfungen unterstützt.
Ein Kartenwerk des Saatgutwissens aufbauen
Um dies zu erreichen, entwerfen die Forscher zunächst eine Ontologie — einen gemeinsamen Bauplan, der die zentralen Bausteine der Saatgutnormen und deren Verknüpfungen definiert. Sie identifizieren sieben Kerntypen, darunter die Norm selbst, die betrachtete Kulturpflanze, Qualitätsindikatoren wie Reinheit oder Keimungsrate, die zahlenmäßigen Grenzwerte für diese Indikatoren, Prüfmethoden und -regeln sowie die Organisationen, die die Dokumente erstellen oder veröffentlichen. Diese Struktur erfasst Muster wie "Kulturpflanze–Qualitätsindikator–Grenzwert", die in der Landwirtschaft besonders wichtig sind. Auf Basis dieses Bauplans speichern sie die extrahierten Fakten als Knoten und Kanten in einer Graphdatenbank (Neo4j) und schaffen so ein Netz von 2.436 Entitäten, verbunden durch 3.011 Beziehungen.
Regelbasiertes Vorgehen kombiniert mit maschinellem Lernen
Die eigentliche Herausforderung besteht darin, aus unübersichtlichen Quelldokumenten saubere, verlässliche Fakten zu extrahieren. Saatgutnormen enthalten sauber formatierte Tabellen, starre Metadaten auf der Titelseite und lange, frei formulierte Textabschnitte. Keine einzelne Technik bewältigt all das gleichermaßen gut. Das Team entwickelt deshalb ein hybrides Extraktionssystem. Sie nutzen präzise Regelmuster (Reguläre Ausdrücke), um strukturierte Tabellen und grundlegende Dokumentinformationen auszulesen, die oft festen Formaten folgen. Für die komplexeren narrative Texte — etwa detaillierte Prüfregeln — trainieren sie eine moderne Sprachmodell-Pipeline namens BERT–BiLSTM–CRF, um Schlüsselbegriffe, Codes und Fachausdrücke zu erkennen. Dieses Modell lernt aus sorgfältig annotierten Beispielen und kann Entitäten identifizieren, selbst wenn sie in variabler Formulierung und in langen Sätzen auftreten. 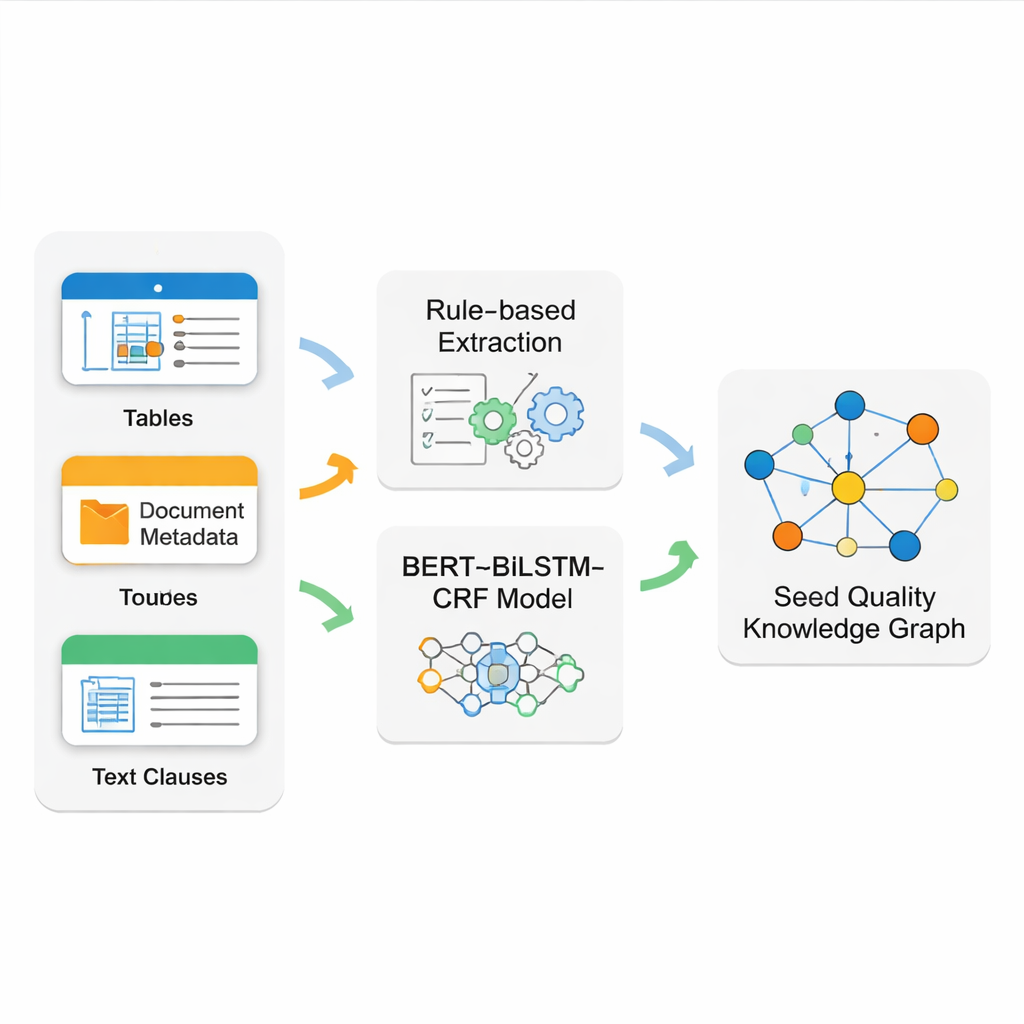
Wie gut das System in der Praxis funktioniert
Im Test zeigt sich das hybride Vorgehen als leistungsfähig. Das Sprachmodell erzielt eine Gesamt-F1-Score (eine Balance aus Genauigkeit und Vollständigkeit) von etwa 91,6 % und übertrifft damit zwei gängige Basismodelle. Es ist besonders gut darin, strukturierte Elemente wie Normcodes zu erkennen, und bleibt auch bei schwierigeren Aufgaben wie langen Prüfregeln robust. Sobald all diese Informationen im Wissensgraphen vorliegen, können Nutzer visuell erkunden, wie eine Norm mit früheren Versionen verknüpft ist, welche Organisationen sie entworfen haben, welche Kulturpflanzen und Indikatoren sie abdeckt und welche Prüfmethoden vorgeschrieben sind. Statt lange PDFs durchzublättern, können Behörden und Saatgutfirmen gezielte Suchen durchführen und vernetzte Ergebnisse in Sekunden sehen.
Was das für Landwirte und Ernährungssysteme bedeutet
Für Nicht-Fachleute ergibt sich eine intelligentere Möglichkeit, die Regeln zu verwalten, die Saatgut zuverlässig und Ernten produktiv halten. Die Studie zeigt, dass sich verstreute Saatgutnormen durch eine klare konzeptionelle Gestaltung und die Kombination von regelbasierten und lernbasierten Extraktionsmethoden in eine kohärente, durchsuchbare Wissensbasis überführen lassen. Das legt die technische Grundlage für "SMART"-Normen, die Computer lesen, abgleichen und bei Regeländerungen aktualisieren können. Langfristig könnten solche Werkzeuge Landwirten und Agrarunternehmen helfen, schnell zu prüfen, ob Saatgut aktuellen Qualitätsanforderungen entspricht, Regulatoren beim Nachverfolgen von Überarbeitungen und Lücken unterstützen und zu stabileren Erträgen sowie Ernährungssicherheit beitragen.
Zitation: Yang, Z., He, Q. & Zhang, J. Construction and application of knowledge graph for seed quality standard documents. Sci Rep 16, 5997 (2026). https://doi.org/10.1038/s41598-026-37084-y
Schlüsselwörter: Qualitätsstandards für Saatgut, Wissensgraph, Digitalisierung der Landwirtschaft, Named Entity Recognition, intelligente Normen