Clear Sky Science · de
Wissensverankertes großes Sprachmodell zur Generierung personalisierter Trainingspläne im Sport
Klügere Trainingspläne für den Alltag
Die meisten Fitness-Apps versprechen personalisierte Trainings, basieren aber oft weiter auf allgemeinen Vorlagen, die ignorieren, wie Ihr Körper tatsächlich funktioniert. Dieses Papier stellt LLM-SPTRec vor, ein neues System, das die gleiche Art großer Sprachmodelle nutzt, die modernen Chatbots zugrunde liegen, kombiniert mit geprüfter Sportwissenschaft und Daten von Wearables, um sicherere und wirkungsvollere Trainingspläne zu erstellen. Für alle, die sich schon gefragt haben, warum ihre App immer die falschen Übungen vorschlägt — oder sich Sorgen gemacht haben, ob KI-basierte Gesundheitsberatung wirklich sicher ist — zeigt diese Arbeit, wie digitales Coaching persönlicher und wissenschaftlich fundierter werden kann.
Warum herkömmliche Fitness-Apps versagen
Konventionelle Empfehlungssysteme, wie diejenigen für Filme oder Produkte, stoßen bei Anwendung auf Training an Grenzen. Sie kopieren häufig Standardvorlagen, tun sich schwer mit begrenzten Daten neuer Nutzer und betrachten selten, wie sich Ihr Körper von Tag zu Tag verändert. Schlimmer noch: Sie sind nicht für Entscheidungen mit hohem Risiko konzipiert, bei denen Sicherheit wichtig ist. Allgemeine Sprachmodelle sind gut darin, über Workouts zu sprechen, können aber — da sie auf breit gestreuten Internettexten trainiert wurden — riskante Ratschläge „halluzinieren“ oder wichtige Ruhetage auslassen. Die Autoren argumentieren, dass für Trainingsplanung — wo schlechte Anleitung zu Verletzungen oder Übertraining führen kann — KI in verifizierter Sportwissenschaft verankert sein und den sich ändernden Zustand einer Person über die Zeit verfolgen muss.
Ein umfassendes Bild der einzelnen Person erstellen
Im Kern von LLM-SPTRec steht ein Modul, das eine detaillierte Momentaufnahme jedes Nutzers erstellt. Anstatt nur Alter, Geschlecht oder Erfahrungslevel zu speichern, verschmilzt das System drei Informationsarten: statische Merkmale (wie Trainingshistorie), dynamische Signale (z. B. Herzfrequenz, Herzfrequenzvariabilität, Schlaf-Score und frühere Workouts aus Wearables und Protokollen) und frei formulierte Ziele, die vom Nutzer geschrieben wurden. Ein transformerbasiertes Modell — verwandt mit der Technik moderner Sprachmodelle — lernt Muster in diesen Zeitreihendaten, etwa wie ein intensives Training gestern die heutige Bereitschaft beeinflussen kann. Ein Aufmerksamkeitsmechanismus gewichtet dann, welche Signale im jeweiligen Moment am wichtigsten sind, und kombiniert sie zu einer einzigen numerischen Darstellung des aktuellen Zustands des Nutzers.
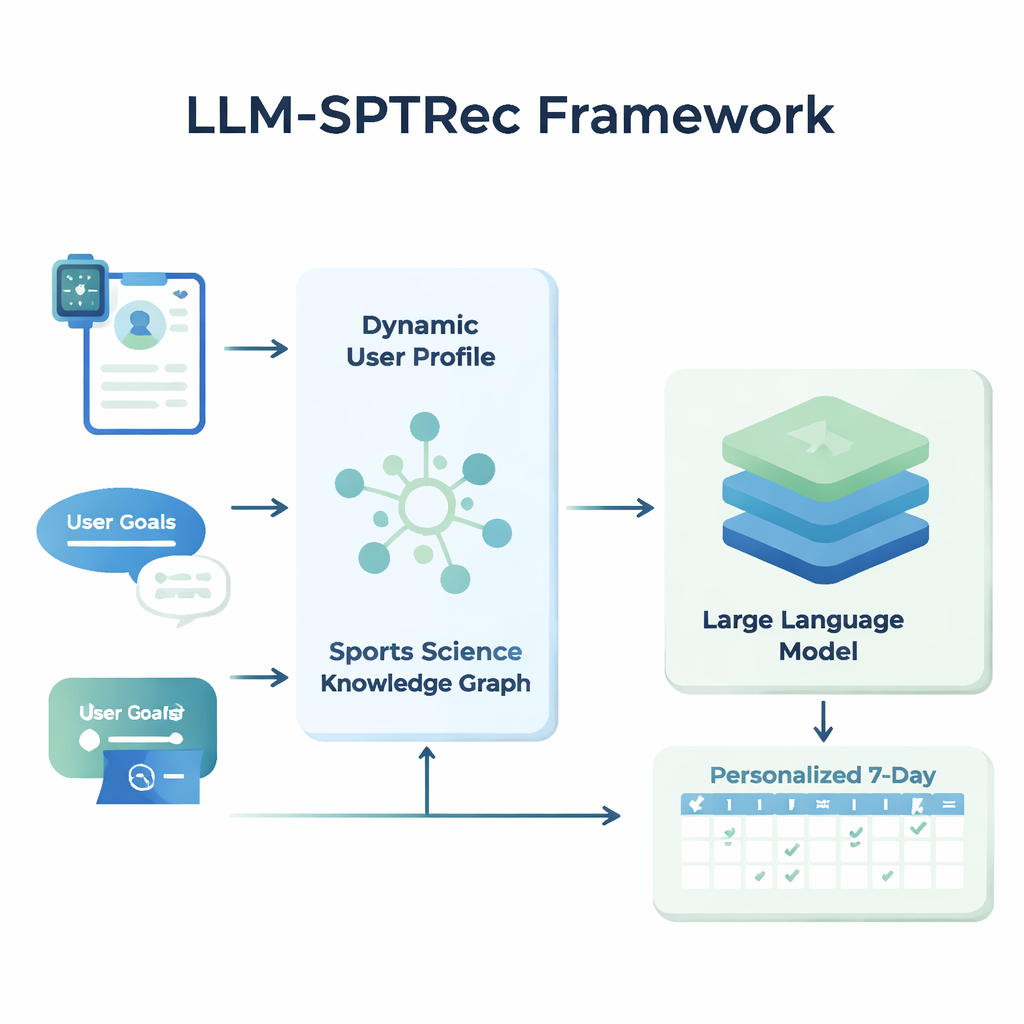
Der KI echte Sportwissenschaft beibringen
Um unsichere oder unwissenschaftliche Empfehlungen zu verhindern, haben die Forschenden einen Sports-Science-Wissensgraphen aufgebaut — im Wesentlichen eine strukturierte Karte fachlich geprüfter Fakten. Er enthält Tausende Einträge, die Übungen mit Muskeln, Bewegungsarten, Ausrüstung, typischen Verletzungen und Trainingsprinzipien wie progressive Überlastung und Spezifität verknüpfen. Für jeden Nutzer zieht das System die relevantesten Teile dieses Graphen — etwa welche Muskeln beim Bankdrücken angesprochen werden und welche Bewegungen bei Schulterproblemen problematisch sind — und wandelt sie in lesbaren Text um, der zusammen mit dem Nutzerprofil in das Sprachmodell eingespeist wird. Dem Sprachmodell wird dann mithilfe eines sorgfältig gestalteten Prompts aufgetragen, einen mehrtägigen Trainingsplan in einem strukturierten Format zu erzeugen und Regeln zu befolgen, wie das Rotieren von Muskelgruppen zwischen den Tagen und das Vermeiden bekannter Kontraindikationen.
Pläne strukturiert, sicher und mit der Zeit besser machen
LLM-SPTRec erzeugt nicht nur Text. Ein Validierungsmodul prüft jeden Plan gegen harte Regeln, etwa keine Überlastung derselben primären Muskelgruppen an aufeinanderfolgenden Tagen, und markiert Konflikte mit Verletzungsrisiken, die im Wissensgraphen gespeichert sind. Falls ein Plan diese Prüfungen nicht besteht, fordert das System das Modell erneut auf, wobei es explizit aufzeigt, was schiefgelaufen ist, bis ein sicherer Plan vorliegt. Das Training des Systems erfolgt ebenfalls in zwei Phasen. Zuerst lernt es aus einer großen Sammlung fachlich entworfener Pläne. Anschließend wird es mithilfe von Feedback verfeinert, wobei simulierte oder reale Nutzerbewertungen Pläne belohnen, die kohärent sind, den Zielen entsprechen und sich gut umsetzen lassen, während unsichere Vorschläge stark bestraft werden. Diese Rückkopplungsschleife lenkt das Modell hin zu Empfehlungen, die in der Praxis besser funktionieren.
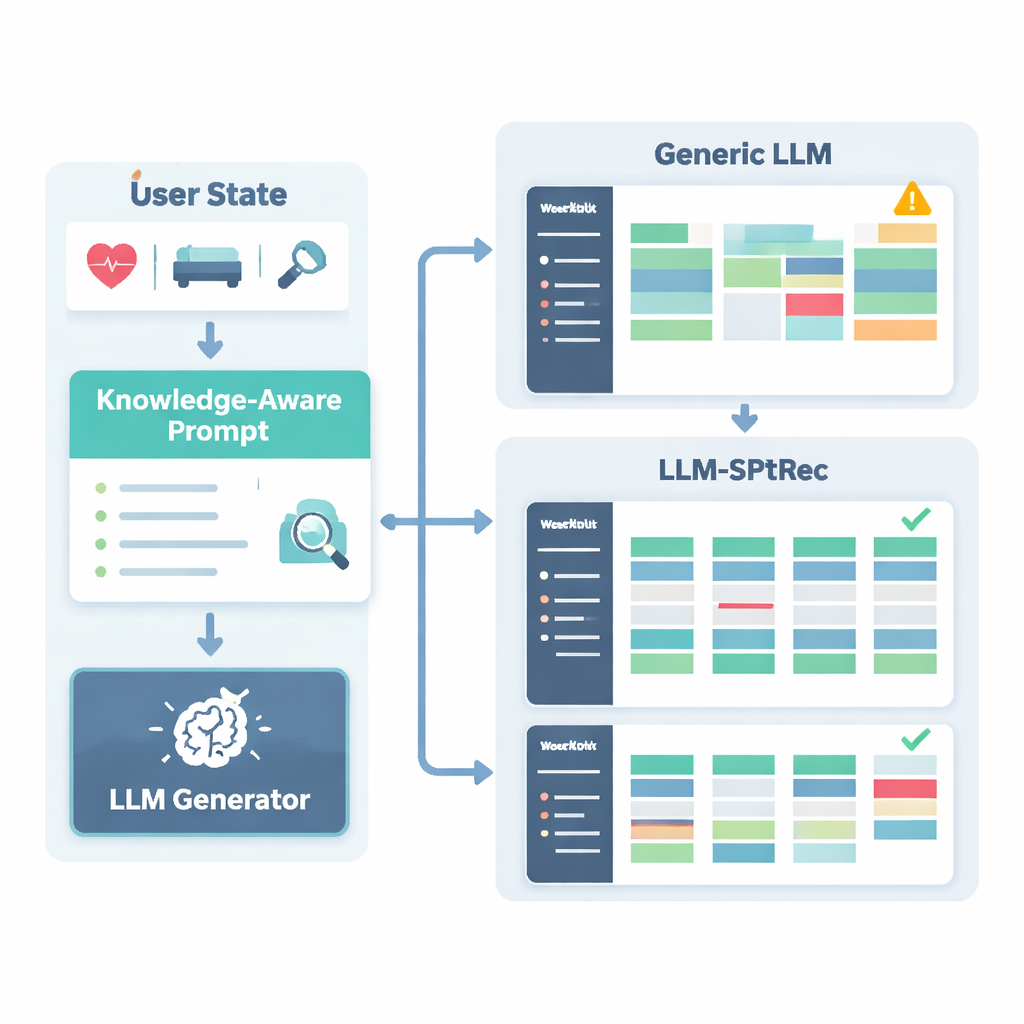
Wie gut das System in der Praxis abschneidet
Die Autoren testeten LLM-SPTRec an einem großen, realen Datensatz namens SportFit-1M, der anonymisierte Daten aus Fitness-Apps und Wearable-Geräten kombiniert und Zehntausende Nutzer sowie Millionen Trainingsprotokolle und physiologischer Aufzeichnungen umfasst. Sie verglichen ihr System mit starken Baselines: klassischem Collaborative Filtering, einem Sequenzmodell, das nur frühere Entscheidungen berücksichtigt, einem modernen Wissensgraph-Recommender und einem allgemeinen Framework auf Basis von Sprachmodellen. LLM-SPTRec übertraf alle nicht nur in der Auswahl geeigneter Übungen, sondern — noch wichtiger — bei der Erstellung vollständiger Pläne, die von Experten als kohärenter und zielgerichteter bewertet wurden. Die prognostizierten Nutzerzufriedenheitswerte waren ebenfalls höher, und eine kleine Studie mit zertifizierten Trainern bewertete seine Sicherheit deutlich besser als die eines allgemeinen Sprachmodells ohne sportwissenschaftliche Verankerung.
Was das für zukünftiges digitales Coaching bedeutet
Für Laien lautet die Botschaft: Intelligenteres, sichereres KI-Coaching ist möglich, wenn drei Zutaten zusammenkommen: reichhaltige Daten von Ihren Geräten, fachliche Sportwissenschaft kodiert als strukturierte Wissensbasis und leistungsfähige Sprachmodelle, deren Kreativität sorgfältig geführt und geprüft wird. LLM-SPTRec zeigt, dass eine solche Kombination adaptive, tageweise Trainingspläne erzeugen kann, die den sich ändernden Zustand Ihres Körpers und Ihre persönlichen Ziele respektieren und gleichzeitig das Risiko schädlicher oder sinnloser Ratschläge verringern. Blickt man nach vorn, könnte dasselbe Konzept über Workouts hinaus auf Ernährung, Reha nach Verletzungen oder sogar psychische Gesundheit ausgeweitet werden und auf eine Zukunft hindeuten, in der KI-Assistenten weniger wie generische Chatbots und mehr wie sachkundige, sicherheitsbewusste digitale Coaches agieren.
Zitation: He, Z., Wang, J., Zhang, B. et al. Knowledge-grounded large language model for personalized sports training plan generation. Sci Rep 16, 6793 (2026). https://doi.org/10.1038/s41598-026-37075-z
Schlüsselwörter: personalisierte Trainings, Sportwissenschaft KI, Fitness-Empfehlung, Wearable-Daten, Wissensgraph