Clear Sky Science · de
Ein leichtgewichtiges YOLO11n-Seg‑Framework für die Echtzeit‑Erkennung und Segmentierung von Oberflächenrissen
Warum kleine Risse wichtig sind
Versteckte Risse in Straßen, Brücken und Gebäuden wirken oft harmlos, sind aber häufig die ersten Warnzeichen dafür, dass eine Struktur verschleißt. Werden diese Linien früh entdeckt, lassen sich kostspielige Reparaturen oder gar katastrophale Ausfälle vermeiden. Trotzdem erfolgen die meisten Inspektionen noch manuell, indem Personen langsam über Flächen gehen oder fahren und handschriftlich Notizen machen. Diese Studie untersucht, wie ein kompakter KI‑Ansatz Risse in Echtzeit erkennen und konturieren kann — schnell genug, um auf Drohnen, kleinen Robotern und energiearmen Sensoren zu laufen, nicht nur in leistungsstarken Rechenzentren.
Von manuellen Kontrollen zu maschinellem Sehen
Ingenieure haben lange versucht, Risserkennung mit klassischen Bildverarbeitungsmethoden wie Kantenerkennung und Schwellenwertverfahren zu automatisieren. Diese Methoden funktionieren in sauberen Laborumgebungen, versagen jedoch schnell in der Praxis, wo Schatten, Flecken und raue Oberflächen einfache Algorithmen verwirren. Neuerdings hat das Deep Learning die Lage verändert: Neuronale Netze können direkt aus Bildern lernen, wie Risse aussehen. Frühe Versionen konnten sagen, ob ein kleines Bildsegment einen Riss enthielt, hatten aber Schwierigkeiten, genau zu markieren, wo sich der Riss befindet, und waren oft zu langsam für Live‑Inspektionen.
Wie ein schlankes Modell Risse lernt zu sehen
Die Autoren bauen auf der YOLO‑Familie auf, einer in der Computer Vision verbreiteten Gruppe von Modellen, die dafür bekannt sind, Objekte in einem einzigen, schnellen Durchlauf zu erkennen. Sie fokussieren auf eine sehr kleine Variante namens YOLO11n‑seg, die darauf ausgelegt ist, die exakte Form von Rissen nachzuzeichnen und nicht nur grobe Kästen um sie zu ziehen. Das Modell wird mit dem Crack‑Seg‑Datensatz trainiert, der über 11.000 sorgfältig gelabelte Straßenbilder enthält, in denen jedes Risspixel markiert ist. Die Bilder werden auf ein Standardformat skaliert und dem Netzwerk zugeführt, das allmählich lernt, die dünnen, gewundenen Muster echter Schäden von harmlosen Hintergrunddetails wie Textur oder Schmutz zu unterscheiden.
Schlaue Tricks für feine Details
Um haarfeine Brüche in rauem Beton zu erkennen, verwendet das Modell zwei Designkniffe. Erstens wechselt ein spezieller Baustein namens C3k2 automatisch zwischen kleinen und etwas größeren Betrachtungsfenstern, sodass er sowohl sehr feinen als auch längeren Rissen folgen kann. Zweitens bringt ein räumliches Aufmerksamkeitsmodul namens C2PSA dem Modell bei, sich auf wahrscheinliche Rissregionen zu konzentrieren und Ablenkungen wie Öl‑Flecken, Schatten oder gemusterte Oberflächen zu ignorieren. Zusammen helfen diese Ergänzungen dem System, Risse sauberer zu konturieren und die Wahrscheinlichkeit zu reduzieren, Hintergrundfehler fälschlich als strukturelle Schäden zu werten — und das bei gleichzeitig geringer Modellgröße, so dass es auf bescheidener Hardware läuft.
Schnelle Ergebnisse ohne schwere Hardware
In Tests enthält das leichtgewichtige Netzwerk nur etwa 2,8 Millionen Parameter — winzig im Vergleich zu vielen modernen Deep‑Learning‑Systemen — und erreicht dennoch Leistungen auf Augenhöhe mit größeren, langsameren Entwürfen. Auf dem Crack‑Seg‑Benchmark identifiziert es Rissregionen mit einer Präzision von etwa 79 % und erzielt starke Werte dafür, wie gut die vorhergesagten Rissformen mit der Grundwahrheit übereinstimmen. Wichtig ist, dass es jedes Bild in etwa 3,6 Millisekunden auf einer Standard‑GPU verarbeitet, was Hunderten von Bildern pro Sekunde entspricht. Im Vergleich zu weit verbreiteten Modellen wie U‑Net, Mask R‑CNN und einer früheren YOLO‑Variante liefert es eine konkurrierende oder bessere Segmentierungsgenauigkeit bei deutlich höherer Geschwindigkeit, womit es sich für kontinuierliche Videoströme von Drohnen oder Inspektionsfahrzeugen eignet.
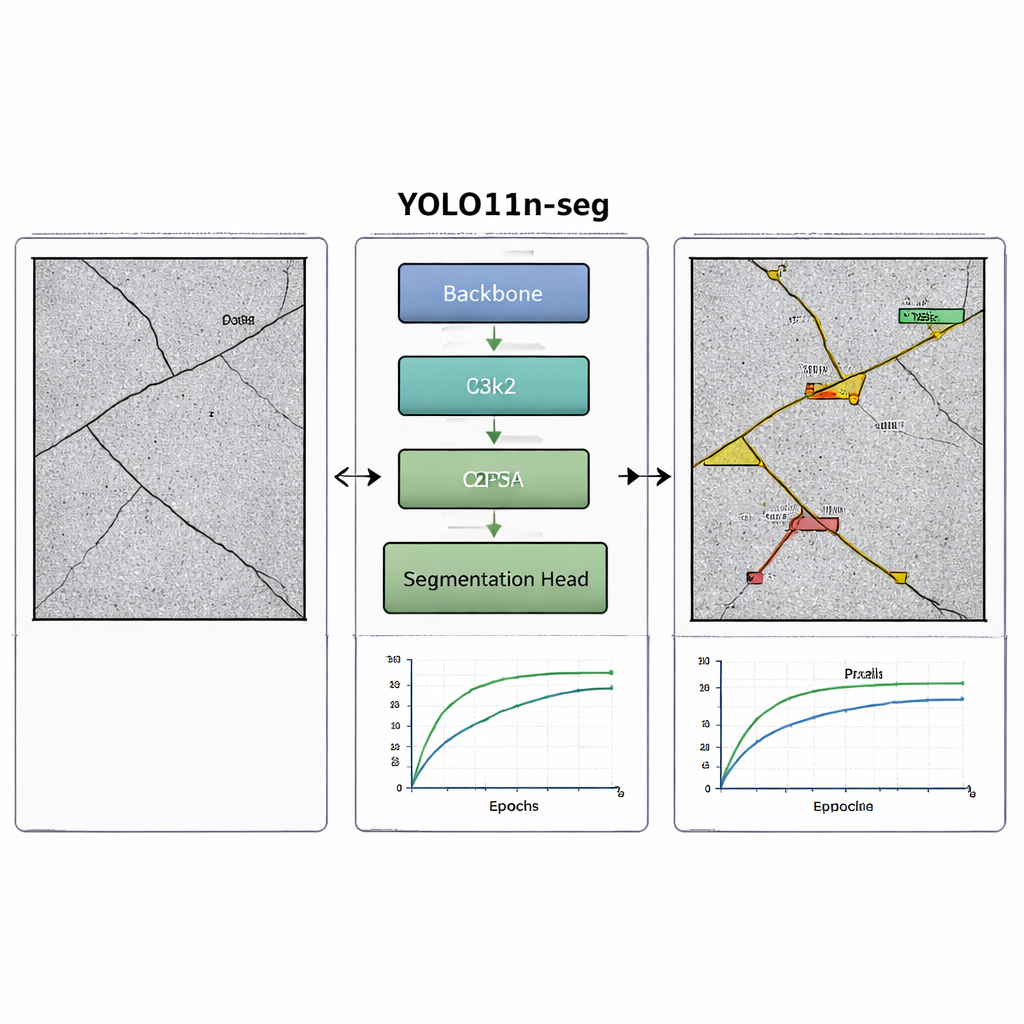
Hin zu automatischen Strukturchecks
Für Nicht‑Expertinnen und Nicht‑Experten ist die Kernbotschaft: Diese Arbeit zeigt, dass es inzwischen möglich ist, kleine, effiziente KI‑Werkzeuge zu bauen, die nicht nur Risse finden, sondern auch deren exakte Form und Größe schnell genug für Echtzeit‑Überwachung nachzeichnen. Sehr feine Risse bei schlechter Beleuchtung oder widrigen Witterungsbedingungen bleiben zwar herausfordernd, doch das vorgeschlagene YOLO11n‑seg‑System bietet ein vielversprechendes Gleichgewicht aus Geschwindigkeit und Zuverlässigkeit. Mit weiteren Verbesserungen und Integration in Feldgeräte könnten solche Modelle Städten und Behörden helfen, Schäden früher zu erkennen, Reparaturen zu priorisieren und lebenswichtige Infrastruktur mit weniger manueller Arbeit sicherer zu halten.
Zitation: Tiwari, S., Gola, K.K., Kanauzia, R. et al. A lightweight YOLO11n seg framework for real time surface crack detection with segmentation. Sci Rep 16, 6566 (2026). https://doi.org/10.1038/s41598-026-37073-1
Schlüsselwörter: Infrastrukturrisse, Computer Vision, Tiefes Lernen, Echtzeit‑Inspektion, YOLO‑Segmentierung