Clear Sky Science · de
Interpretationsdrift bei erklärbarer KI bei Label-Rauschen
Warum KI-Erklärungen heimlich schiefgehen können
Viele Menschen verlassen sich heute bei Entscheidungen nicht nur auf die Antworten der Künstlichen Intelligenz, sondern auch auf die Begründungen: Warum wurde ein Kredit abgelehnt? Warum stufte ein System einen Patienten als hohes Risiko ein? Diese Studie zeigt, dass selbst wenn die Genauigkeit eines KI‑Modells auf den ersten Blick stabil wirkt, die Erklärung dafür, warum es eine Entscheidung traf, sich dramatisch verschieben kann, wenn die Trainingsdaten Fehler enthalten. Diese verborgene Verschiebung der Erklärungen — die Autoren nennen sie „Interpretationsdrift“ — kann Fachkräfte in die Irre führen, die sich auf KI stützen, um wichtige Entscheidungen zu begründen.
Wenn saubere Daten auf unordentliche Labels treffen
Die meisten modernen KI‑Systeme sind „Black Boxes“ und liefern Vorhersagen ohne klare Begründung. Um KI transparenter zu machen, setzen viele Anwendungen auf regelbasierte Modelle, die menschlichem Wenn‑Dann‑Denken ähneln: etwa „wenn Blutdruck hoch und Alter über 60, dann hohes Risiko.“ Solche Regelmengen sind besonders attraktiv in sensiblen Bereichen wie Gesundheitswesen, Rechtswesen und Finanzwesen, wo Nutzer die Logik prüfen und ihr vertrauen müssen. In der realen Welt sind Daten jedoch selten perfekt. Ein verbreitetes Problem ist Label‑Rauschen — Fälle, in denen die vermeintlich „richtige Antwort“ in den Trainingsdaten falsch ist, etwa eine falsch erfasste Diagnose oder ein falsch gekennzeichnetes Kundenergebnis. Während bekannt ist, dass Label‑Rauschen die Vorhersagequalität beeinträchtigt, war sein Einfluss auf die Stabilität von KI‑Erklärungen bisher nicht systematisch untersucht worden.
Prüfung, wie Erklärungen unter Rauschen standhalten
Die Autoren untersuchten, wie robust regelbasierte Erklärungen bleiben, wenn Labels schrittweise korrumpiert werden. Sie nutzten vier verschiedene Datensätze aus Gesundheitswesen, Banking, Lebererkrankungen und sogar Zahlentheorie, jeweils als Ja‑Nein‑Vorhersageaufgaben. Verglichen wurden drei Regellernverfahren: zwei populäre, schnelle Algorithmen (IREP und RIPPER) und ein rechnerisch aufwendigerer Ansatz namens Human Knowledge Models (HKM), der explizit darauf abzielt, sehr einfache, menschenähnliche Regelmengen zu erzeugen. Für jede Methode trainierten die Forschenden wiederholt Modelle, während sie zufällig einen wachsenden Anteil der Trainingslabels umdrehten — von nahezu fehlerfreien Daten bis hin zu nahezu vollständigem Unsinn. Parallel verfolgten sie zwei Dinge: wie gut die Modelle auf einem sauberen Testset weiterhin vorhersagten und wie stark sich die gelernten Regeln im Vergleich zu denen aus rauschfreien Daten veränderten.
Genauigkeit stabil, Logik im Fluss
Auf den ersten Blick könnten die Ergebnisse Nutzer in falscher Sicherheit wiegen. Bei moderaten Rauschpegeln, insbesondere mit der HKM‑Methode, erschien die Vorhersageleistung nach gängigem F1‑Maß relativ stabil. Ein genauerer Blick auf die Regelmengen erzählte jedoch eine andere Geschichte. Mit einer Ähnlichkeitsmetrik, die Regelkollektionen vergleicht, stellten die Autoren fest, dass bereits mäßige Mengen an Label‑Rauschen die Übereinstimmung zwischen den ursprünglichen und den verrauschten Erklärungen rasch auflösten. Anders gesagt: Das Modell kann in vielen Fällen weiterhin richtig liegen, aber aus zunehmend anderen Gründen. Komplexere Regelmengen waren dabei besonders anfällig: Mit zunehmender Anzahl von Bedingungen in einer Regel führten kleine Änderungen in den Daten eher dazu, dass diese Regeln zerbrachen oder ersetzt wurden, was den Verlust an Interpretationsstabilität beschleunigte.
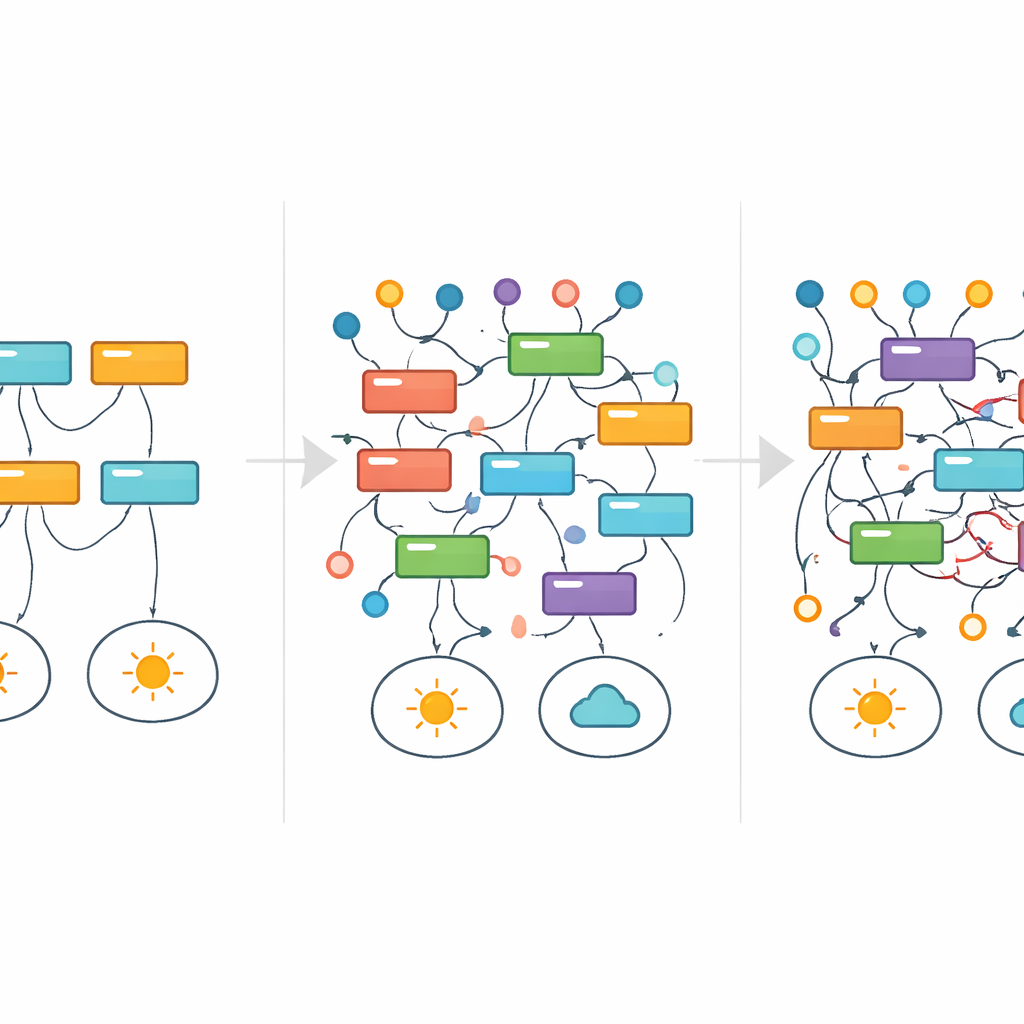
Regeln verfolgen, wie sie erscheinen und verschwinden
Um zu veranschaulichen, wie einzelne Erklärungen mit steigendem Rauschen überleben oder versagen, entlehnten die Forschenden ein Instrument aus der Medizin: die Überlebensanalyse. Anstelle der Verfolgung des Patientenüberlebens über die Zeit verfolgten sie, wie lange eine bestimmte Regel unter den besten Modellen weiterhin auftauchte, während das Label‑Rauschen zunahm. Viele Regeln flackerten eher auf und ab, anstatt sanft zu verblassen — ein Zeichen dafür, dass völlig unterschiedliche Erklärungen bei verschiedenen Rauschpegeln dominieren können, selbst für dieselbe zugrundeliegende Aufgabe. In einem einfachen Datensatz zur Teilbarkeit von Zahlen wurden etwa saubere und mathematisch korrekte Regeln nach und nach durch breitere Annäherungen und schließlich durch verschlungene, scheinbar beliebige Muster ersetzt, die dennoch zu den korrumpierten Labels passten. Während dieses Prozesses signalisierten die gängigen Leistungskennzahlen nur selten eindeutig, dass etwas nicht stimmte.
Was das für Menschen bedeutet, die sich auf KI verlassen
Die zentrale Botschaft lautet, dass „vertrauenswürdige“ KI nicht allein an der Genauigkeit gemessen werden kann. Selbst Modelle, die ihre Logik in menschenlesbaren Regeln darstellen, können ihre Begründung stillschweigend ändern, wenn die Labels, von denen sie lernen, unvollkommen sind — was in den meisten realen Datenbanken genau der Fall ist. Die Autoren plädieren dafür, dass Entwickler und Regulierungsbehörden die Stabilität von Erklärungen als gleichrangiges Kriterium neben Genauigkeit und Fairness behandeln sollten. Neue Metriken, die direkt messen, wie konsistent die Erklärungen eines Modells unter Rauschen bleiben, sowie Werkzeuge, die Nutzer auf Interpretationsdrift aufmerksam machen, werden entscheidend sein, wenn wir KI‑Systeme wollen, deren Darstellungen der Welt ebenso verlässlich sind wie ihre Vorhersagen.
Zitation: Raikovskaia, A., Rakhimzhanov, N. & Pianykh, O.S. Interpretation drift in explainable AI under label noise. Sci Rep 16, 8528 (2026). https://doi.org/10.1038/s41598-026-37070-4
Schlüsselwörter: erklärbare KI, Label-Rauschen, Modellinterpretierbarkeit, regelbasierte Modelle, Interpretationsdrift