Clear Sky Science · de
Die Entwicklung der Objekterkennung: von CNNs zu Transformern und multimodaler Fusion
Computern beibringen, Alltagsobjekte zu sehen
Jedes Mal, wenn Ihr Telefon Freunde in einem Foto markiert, ein Auto einen Fußgänger erkennt oder ein Diagnosewerkzeug einen Tumor in einer Aufnahme hervorhebt, arbeitet eine unscheinbar mächtige Technologie im Hintergrund: Objekterkennung. Dieser Übersichtsartikel erklärt, wie sich die Objekterkennung in den letzten zehn Jahren rasant entwickelt hat — von frühen bildverarbeitenden Tricks zu den heutigen, auf Transformern und mehreren Sensoren basierenden Systemen — und warum diese Fortschritte für sicherere Straßen, intelligentere Roboter und präzisere medizinische Diagnosen wichtig sind.
Von Pixeln zu erkennbaren Dingen
Objekterkennung ist die Aufgabe, in Bildern oder Videos bestimmte Gegenstände zu finden und zu kennzeichnen — Autos, Radfahrende, Tiere, medizinische Strukturen und mehr. Der Artikel beginnt mit einer Kartierung der weiten Einsatzgebiete: autonomes Fahren, Überwachung, medizinische Bildgebung und Robotik. Frühe Systeme stützten sich auf handgestrickte Regeln, um Formen und Texturen zu erkennen; moderne Ansätze lernen direkt aus Daten mittels Deep Learning. Zwei große Familien dominieren heute: Convolutional Neural Networks (CNNs), die sehr gut darin sind, lokale Muster wie Kanten und Ecken zu erkennen, und Transformer, die besonders gut darin sind, die gesamte Szene und Beziehungen zwischen weit entfernten Objekten zu verstehen. Zusammen bestimmen sie, wie Maschinen die Welt heute „sehen“.
Wie klassische Vision-Engines funktionieren
CNN-basierte Methoden treiben noch viele Echtzeitanwendungen an. Sie scannen Bilder mit kleinen Filtern, um immer reichhaltigere Merkmalskarten aufzubauen, und geben diese an Erkennungs-Module weiter, die Begrenzungsrahmen zeichnen und Labels zuweisen. Die Übersicht erklärt zwei Hauptstrategien. Zwei-Stufen-Systeme wie Faster R-CNN schlagen zunächst wahrscheinliche Objektregionen vor und verfeinern diese dann, wobei sie oft hohe Genauigkeit auf Kosten höherer Rechenlast erreichen. Ein-Stufen-Systeme wie die YOLO-Familie überspringen den Vorschlagschritt und sagen Boxen und Labels in einem einzigen Durchgang vorher — ein Kompromiss: etwas Genauigkeit gegen deutlich höhere Geschwindigkeit. Neuere Versionen wie YOLOv5 und YOLOv8 wurden stark optimiert — mit intelligenteren Feature-Pyramiden für kleine Objekte, leichten Bausteinen für Edge-Geräte und verbesserten Verlustfunktionen — und erreichen so Hunderte von Bildern pro Sekunde, während sie auf anspruchsvollen Benchmarks konkurrenzfähig bleiben.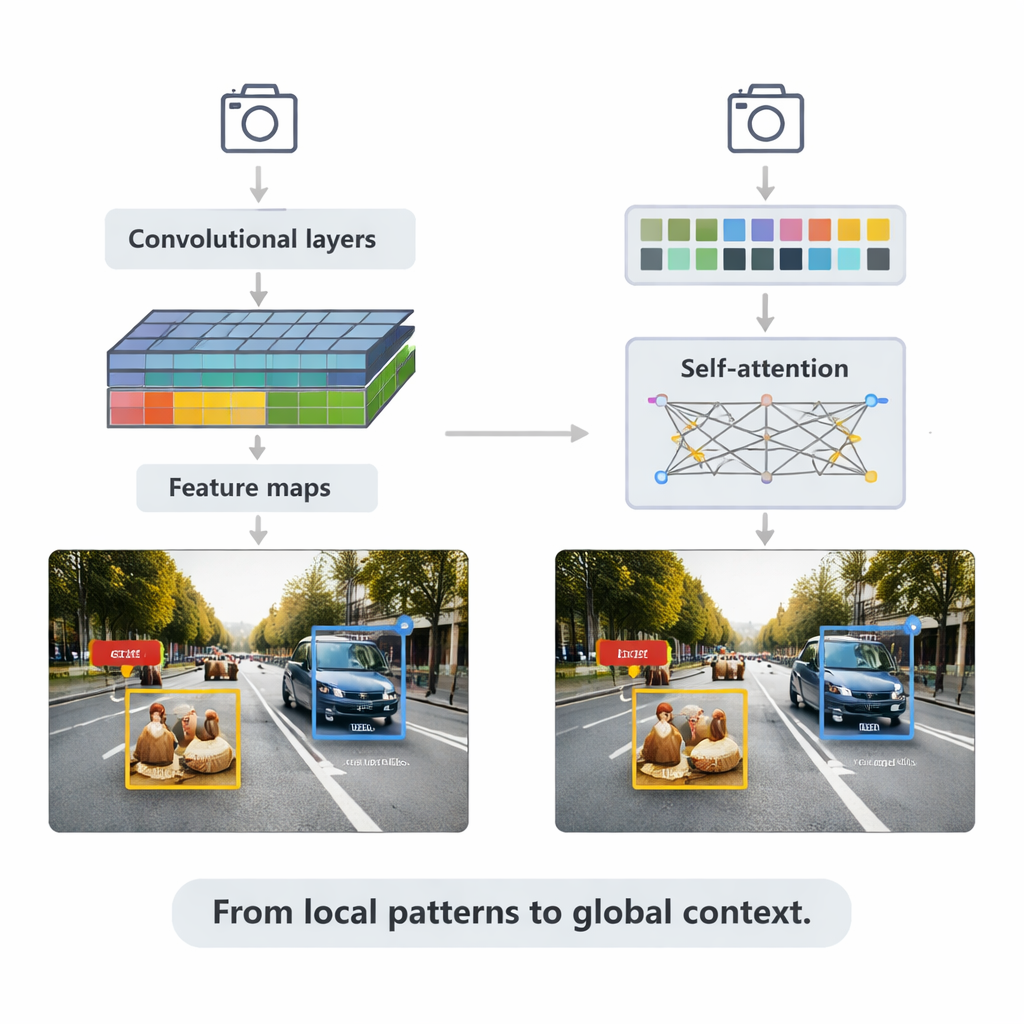
Transformer und die Kraft des Kontexts
Der Artikel wendet sich dann den Transformern zu, einer neueren Architektur, die aus Sprachmodellen übernommen wurde. Statt sich nur auf lokale Nachbarschaften zu konzentrieren, verwenden Transformer „Self-Attention“, um jeden Bildausschnitt mit jedem anderen zu vergleichen und zu lernen, welche Regionen für eine Entscheidung am relevantesten sind. Detection Transformer (DETR) und seine Nachfolger entfernen viele handgefertigte Tricks und zielen auf sauberere End-to-End-Pipelines. Varianten wie Deformable DETR und RT-DETR verringern den Rechenaufwand und verbessern die Trainingsgeschwindigkeit, sodass Transformer in Echtzeit laufen können und gleichzeitig einige der höchsten Genauigkeitswerte auf dem weit verbreiteten COCO-Benchmark erreichen. Diese Modelle zeigen ihre Stärke besonders in komplexen Szenen mit überlappenden Objekten und verwirrendem Hintergrund, wo globaler Kontext hilft, etwa einen teilweise hinter einem Auto verborgenen Fußgänger zu unterscheiden.
Kameras, Laser und Sprache verschmelzen
Reale Bedingungen — Nebel, Dunkelheit, Blendung, Unordnung — setzen Einzel-Sensor-Systeme oft außer Gefecht. Ein wichtiger Schwerpunkt der Übersicht ist die multimodale Fusion: die Kombination von Daten aus herkömmlichen Kameras (RGB), Tiefensensoren wie LiDAR, Wärmebildkameras und sogar Textbeschreibungen. Die Autoren stellen eine klare Taxonomie vor, wie diese Verschmelzung stattfinden kann: Early Fusion mischt Rohdaten von Anfang an, Middle Fusion verbindet gelernte Merkmale innerhalb des Netzes und Late Fusion kombiniert die Ausgaben separater Detektoren am Ende. Moderne „Fusion-Transformer“ nutzen Aufmerksamkeitsmechanismen, um diese Ströme auszurichten, sodass präzise Abstandsmaße von LiDAR, reichhaltige Erscheinungsinformationen aus RGB-Bildern und semantische Hinweise aus Sprache sich gegenseitig verstärken. Dieser Ansatz verbessert die Erkennung im autonomen Fahren, in der medizinischen Bildgebung, beim Videoverstehen und in textreichen Szenen.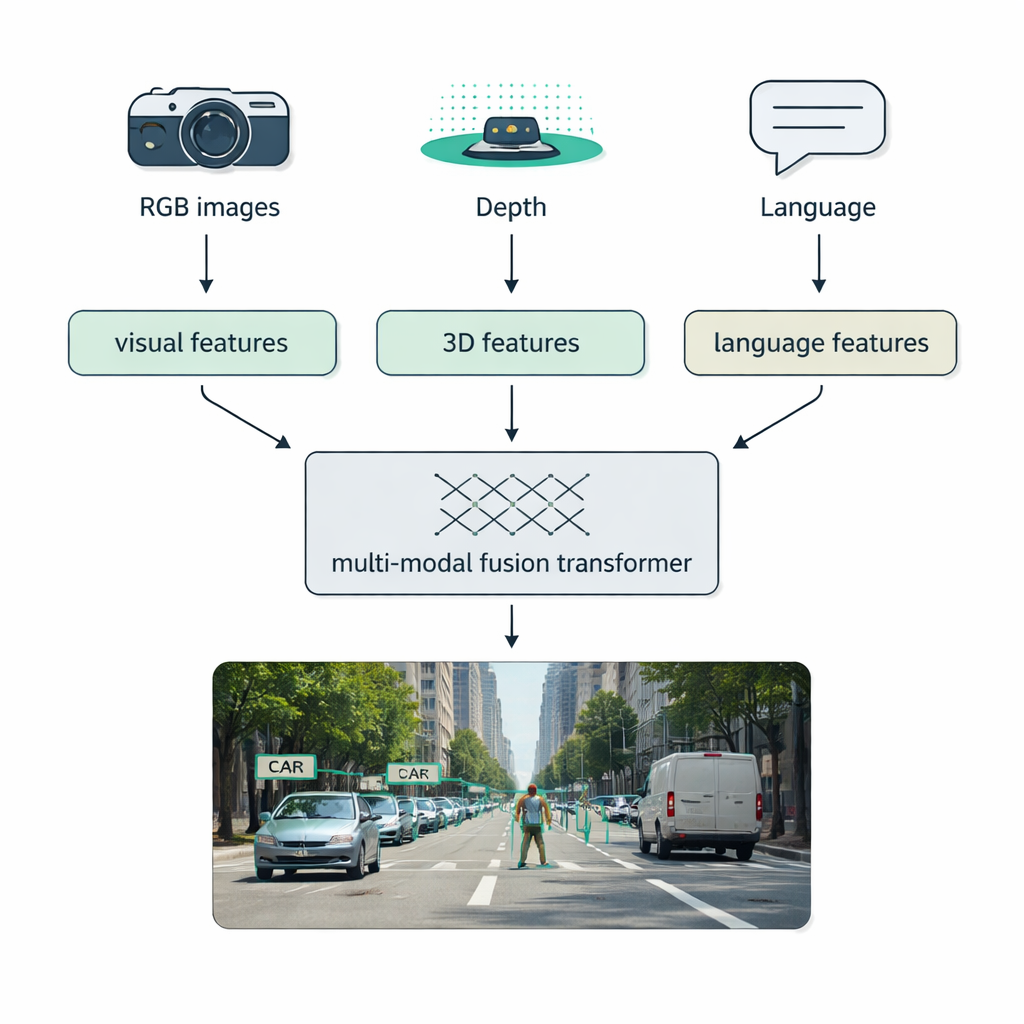
Benchmarks, Grenzen und was als Nächstes kommt
Über Standardtests wie MS COCO vergleicht die Übersicht CNN- und Transformer-Detektoren in Bezug auf Genauigkeit und Geschwindigkeit. Klassische Zwei-Stufen-CNNs bleiben stark, sind aber langsamer; YOLO-ähnliche Modelle dominieren auf leichter Hardware; und Transformer-basierte Systeme führen jetzt bei der Genauigkeit, während sie die Lücke in der Geschwindigkeit schließen. Spezialisierte Infrarotmethoden erreichen sehr gute Werte unter schlechten Sichtbedingungen. Dennoch bleiben schwierige Probleme: sehr kleine oder extrem große Objekte, starke Verdeckungen, wechselndes Wetter und Licht sowie die Notwendigkeit, zuverlässig auf winzigen Geräten zu laufen. Ein Blick nach vorn: Die Autoren heben Trends hin zu einheitlichen Wahrnehmungsmodellen hervor, die Erkennung, Segmentierung und Bildbeschriftung gemeinsam bewältigen, sowie „Foundation Models“, die Vision und Sprache verschmelzen, um Objekte zu erkennen, die in den Trainingsdaten nie explizit beschriftet wurden.
Warum das im Alltag wichtig ist
Für Nicht-Spezialisten lautet die Kernbotschaft: Die Objekterkennung bewegt sich von engen, handoptimierten Systemen hin zu flexiblen, universellen Vision-Engines, die sich an neue Aufgaben, Umgebungen und Sensoren anpassen können. CNNs liefern schnelle, effiziente Mustererkennung; Transformer fügen ein globaleres, kontextbewusstes Verständnis hinzu; und multimodale Fusion bindet zusätzliche Hinweise aus Tiefe, Temperatur und Sprache ein. Zusammen versprechen diese Fortschritte Fahrzeuge, die Gefahren besser antizipieren, Werkzeuge, die Ärzte sicherer unterstützen, und Heimgeräte, die sicherer und intelligenter mit ihrer Umgebung interagieren — und bringen maschinelle Wahrnehmung näher an die Vielschichtigkeit menschlichen Sehens.
Zitation: Wang, Z., Chen, Y., Gu, Y. et al. The evolution of object detection from CNNs to transformers and multi-modal fusion. Sci Rep 16, 7517 (2026). https://doi.org/10.1038/s41598-026-37052-6
Schlüsselwörter: Objekterkennung, Computer Vision, Tiefes Lernen, Transformer-Modelle, multimodale Fusion