Clear Sky Science · de
Ermittlung des Mobilitätsfunktionsstatus in elektronischen Gesundheitsakten mit großen Sprachmodellen
Warum die Gehfähigkeit ein starkes Gesundheitszeichen ist
Da Menschen länger leben, richten Ärztinnen und Ärzte ihr Augenmerk nicht mehr nur darauf, wie lange wir leben, sondern auch darauf, wie gut wir uns bewegen, gehen und selbst versorgen können. Schwierigkeiten beim Aufstehen aus einem Stuhl, beim Treppensteigen oder beim Unterwegssein treten oft lange vor einer akuten medizinischen Krise auf. Die detailliertesten Beschreibungen der Alltagsfähigkeiten einer Person stecken jedoch meist in freien Texten von Ärztinnen, Ärzten und Therapeutinnen in den elektronischen Gesundheitsakten und sind für Computer schwer auffindbar. Diese Studie untersucht, ob moderne große Sprachmodelle — dieselbe Art von KI, die vielen Chatbots zugrunde liegt — zuverlässig diese Notizen lesen und Beschreibungen von Bewegung in strukturierte, durchsuchbare Informationen umwandeln können.
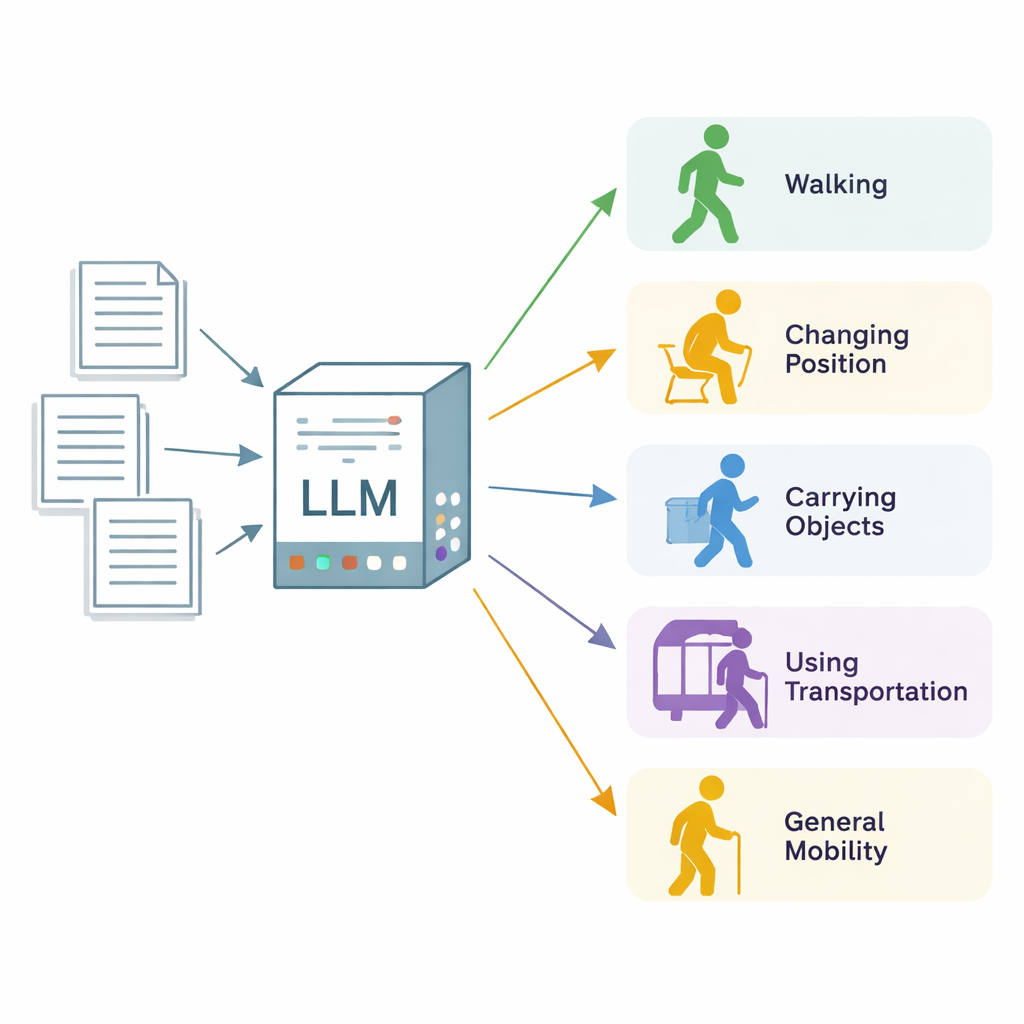
Aus unordentlichen Notizen verwertbare Mobilitätsdaten machen
Die Forschenden konzentrierten sich auf den „Mobilitätsfunktionsstatus“, einen weit gefassten Begriff dafür, wie gut eine Person Körperpositionen verändert, geht, Gegenstände trägt und handhabt, Transportmittel nutzt und sich im Alltag bewegt. Sie nutzten 600 echte klinische Notizen aus drei Gesundheitseinrichtungen in Minnesota und Wisconsin, die meisten aus physio‑ und ergotherapeutischen Sitzungen, zusätzlich zu einer Reihe allgemeinerer Kliniknotizen. Expertinnen und Experten durchsuchten jede Notiz Abschnitt für Abschnitt und markierten jede Passage, die eine der fünf Mobilitätskategorien beschrieb, wobei sie kennzeichneten, ob die Patientin oder der Patient eindeutig eingeschränkt („beeinträchtigt“) oder normal funktionierend („nicht beeinträchtigt“) war. Diese Expertenkennzeichnungen dienten als Goldstandard zur Bewertung des KI‑Systems.
Wie das KI‑Modell so trainiert wurde, dass es wie ein Kliniker liest
Das Team verwendete Llama 3, ein Open‑Source‑Großes‑Sprachmodell, und ließ es auf sicheren lokalen Servern laufen, damit Patientendaten das Gesundheitswesen nie verlassen. Anstatt das Modell von Grund auf neu zu trainieren, entwarfen sie sorgfältig Prompts — Sets von geschriebenen Anweisungen und Definitionen — um dem Modell beizubringen, worauf es achten soll. Sie testeten „Zero‑Shot“‑Prompts, die nur Anweisungen gaben, und „Few‑Shot“‑Prompts, die auch einige Beispielnotizen enthielten. Anschließend analysierten sie, wo das Modell Fehler machte, und entwickelten einen „fehlerinformierten“ Prompt, der klarlegte, was einzubeziehen ist, was zu ignorieren ist (zum Beispiel zukünftige Behandlungspläne) und wie mit schwierigen Fällen wie Stürzen, Schwindel oder Rollstuhlnutzung umzugehen ist. Die KI wurde gebeten, für jeden Notizabschnitt und jede Mobilitätskategorie anzugeben, ob Mobilität überhaupt erwähnt wurde und, falls ja, ob die Patientin oder der Patient beeinträchtigt war.
Starke Leistung verbessert sich auf Patientenebene
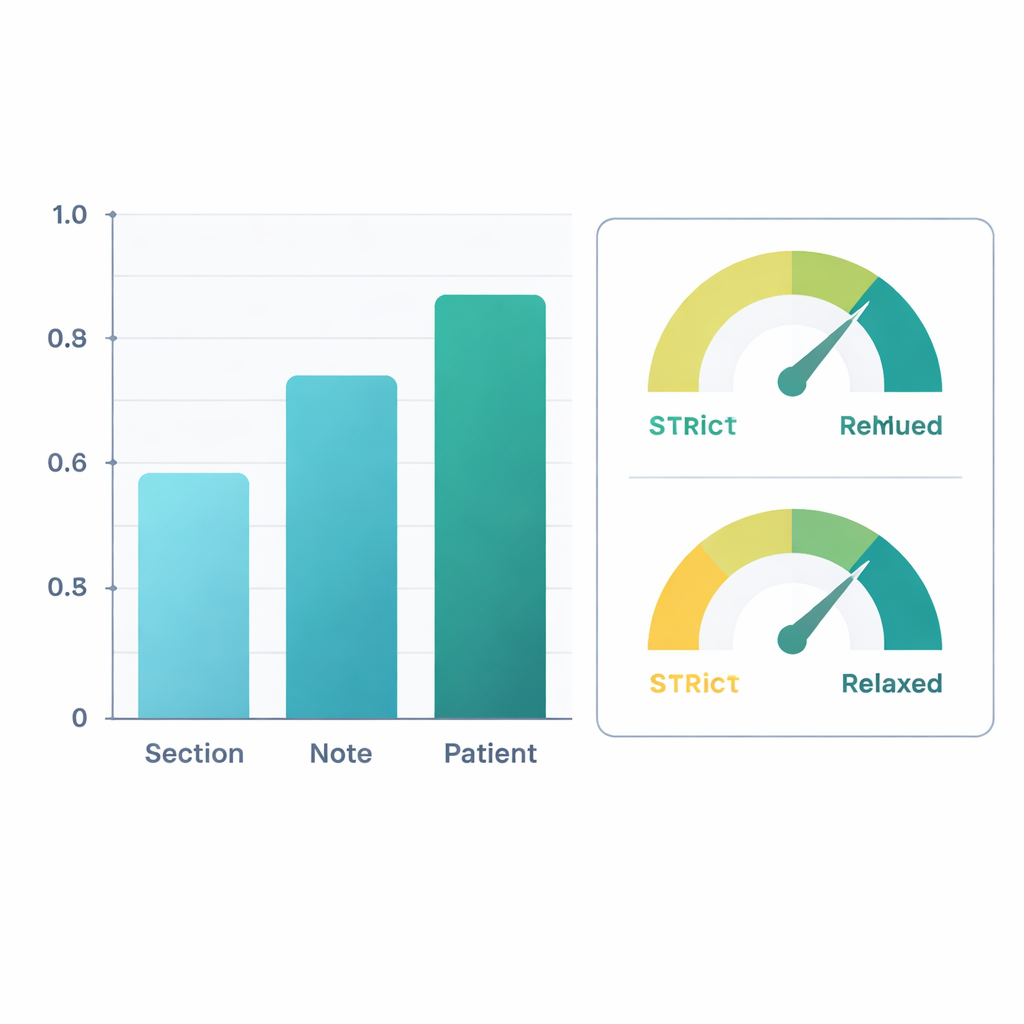
Gegenüber den Expertenkennzeichnungen schnitt das verfeinerte System gut ab. Auf Ebene ganzer Patientinnen und Patienten — indem Informationen aus allen ihren Notizen kombiniert wurden — erreichte die KI einen F1‑Score (ein gängiges Maß für Genauigkeit) von etwa 0,88 für das bloße Auffinden von Mobilitätsinformationen und 0,90 für die Feststellung, ob die Person beeinträchtigt war. Das bedeutet, dass ihre Einschätzungen eng mit denen menschlicher Gutachter übereinstimmten. Die Leistung war etwas niedriger, wenn einzelne Notizabschnitte betrachtet wurden, in denen die Formulierungen knapp oder mehrdeutig sein können, aber die Genauigkeit verbesserte sich, wenn Informationen über ganze Notizen hinweg und dann über alle Notizen einer Patientin oder eines Patienten aggregiert wurden. In einer zweiten Analyse zählten die Forschenden „klinisch vernünftige Schlussfolgerungen“ ebenfalls als korrekt — zum Beispiel die Annahme, dass starke Knieschmerzen beim Gehen wahrscheinlich das Gehen einschränken, auch wenn dies nicht ausdrücklich steht. Unter dieser nachsichtigen Betrachtungsweise stiegen die Patienten‑F1‑Scores auf über 0,96 für die Extraktion und 0,95 für die Klassifikation von Beeinträchtigungen.
Was die KI falsch machte — und warum das trotzdem wichtig ist
Die meisten Fehler entstanden dadurch, dass das Modell zwischen den Zeilen las. Es schloss häufig auf Mobilitätsprobleme aufgrund von Schmerzen, Schwindel oder zukünftigen Therapieplänen, selbst wenn in der Notiz nie klar stand, dass die Patientin oder der Patient eingeschränkt war. Andere Fehler spiegelten Grauzonen in den Definitionen wider, etwa ob wiederholte Stürze als Geh‑oder als Gleichgewichtsproblem beim Positionswechsel zu betrachten sind. Die Klasse „Mobilität, nicht spezifiziert“, die alltägliche Aktivitäten und Bewegung erfassen sollte, war besonders schwer zu fassen. Trotz dieser Probleme waren die Fehler in der Regel aus klinischer Sicht plausibel und nicht zufällig oder bizarr. Indem das Modell deterministisch (ohne eingebaute Zufälligkeit) auf abgesicherten lokalen Servern betrieben wurde, stellten die Forschenden außerdem sicher, dass die Ergebnisse reproduzierbar sind und die Privatsphäre der Patientinnen und Patienten gewahrt bleibt.
Wie sich die Versorgung älterer Menschen dadurch ändern könnte
Für Laien lässt sich festhalten: Ein KI‑System kann routinemäßige Arzt‑ und Therapeutennotizen inzwischen gut genug lesen, um zusammenzufassen, wie gut Patientinnen und Patienten sich bewegen und wo sie Schwierigkeiten haben. Das bedeutet, dass Gesundheitssysteme Veränderungen beim Gehen, Gleichgewicht und bei Alltagsaktivitäten im Zeitverlauf verfolgen könnten, ohne neue Fragebögen oder Tests einzuführen, Risikopersonen für Stürze oder Krankenhauseinweisungen identifizieren und diejenigen finden könnten, die von Physiotherapie oder Haus‑Sicherheitsbewertungen profitieren würden. Indem Millionen freier Textnoten in strukturierte Mobilitätsdaten umgewandelt werden, hilft dieser Ansatz Ärztinnen und Ärzten, das größere Bild davon zu sehen, wie Altern und Krankheit das Alltagsleben beeinflussen — und bringt die Gesundheitsversorgung einen Schritt näher zu wirklich personalisierter, funktionszentrierter Medizin.
Zitation: Liu, X., Garg, M., Jia, H. et al. Mobility functional status ascertainment in electronic health records using large language models. Sci Rep 16, 6045 (2026). https://doi.org/10.1038/s41598-026-37025-9
Schlüsselwörter: Mobilität, elektronische Gesundheitsakten, große Sprachmodelle, Funktionsstatus, klinische KI