Clear Sky Science · de
Ein Benchmark zur Bewertung der Effizienz diagnostischer Fragestellungen von LLMs in Patientengesprächen
Warum klügere medizinische Fragen wichtig sind
Wenn Sie einen Arzt aufsuchen, stammt die erste Diagnose selten aus einem einzigen erwähnten Symptom. Stattdessen stellen Ärzte eine Reihe von Anschlussfragen – zu Zeitpunkt, Intensität, Begleiterscheinungen – um schrittweise einzugrenzen, was falsch sein könnte. So leistungsfähig die heutigen KI‑Systeme auch sind, werden die meisten immer noch so getestet, als würden sie Multiple‑Choice‑Prüfungen ablegen, statt mit echten Menschen zu sprechen. Dieses Paper stellt Q4Dx vor, ein neues Verfahren, um zu beurteilen, wie gut große Sprachmodelle (LLMs) die Rolle des „neugierigen Arztes“ übernehmen können: die richtigen Fragen in der richtigen Reihenfolge zu wählen, um effizient zur richtigen Diagnose zu gelangen.
Von Prüfungsfragen zu echten Gesprächen
Die meisten bestehenden Tests für medizinische KI geben den Modellen saubere, vollständig spezifizierte Fälle – wie eine Lehrbuchaufgabe – und fordern sie auf, eine Diagnose zu wählen. Das zeigt, was das System „weiß“, aber nicht, wie es sich in einem unordentlichen, realen Gespräch mit einer Patientin oder einem Patienten verhalten würde, die Details vergisst oder Symptome in Alltagssprache beschreibt. Die Autoren argumentieren, dass dies eine schwere Schwachstelle ist. In der Klinik kommen Informationen langsam und oft ungenau zutage; die Kompetenz guter Kliniker liegt ebenso sehr im Fragenstellen wie im bereits vorhandenen Wissen. Q4Dx soll diese Lücke schließen, indem der Fokus von statischen Fragen‑Antworten auf die Strategie des zeitlichen Fragens verlagert wird.
Lebensechte Patientengeschichten erstellen
Um dieses neue Testbett zu entwickeln, starten die Forscher mit einer kuratierten medizinischen Ressource, die bestimmte Krankheiten mit charakteristischen Symptomkombinationen verknüpft. Sie wählen zufällig 100 solche Krankheits‑Symptom‑Paare aus und nutzen dann ein KI‑Modell, um sterile Symptomlisten in natürlich klingende Selbstbeschreibungen von Patientinnen und Patienten zu verwandeln – Geschichten, wie sie in einer Praxis tatsächlich erzählt werden könnten. Aus jedem vollständigen Fall generieren sie kürzere Versionen, in denen nur etwa 80 Prozent bzw. 50 Prozent der Schlüsselsymptome genannt werden. Dieses kontrollierte „Verstecken“ von Informationen erlaubt es, zu untersuchen, wie gut verschiedene Modelle sich anpassen, wenn wichtige Hinweise fehlen oder nur angedeutet werden. Überprüfungen der Symptomüberlappung bestätigen, dass die kürzeren Versionen tatsächlich weniger verwertbare Informationen enthalten und nicht nur weniger Wörter.
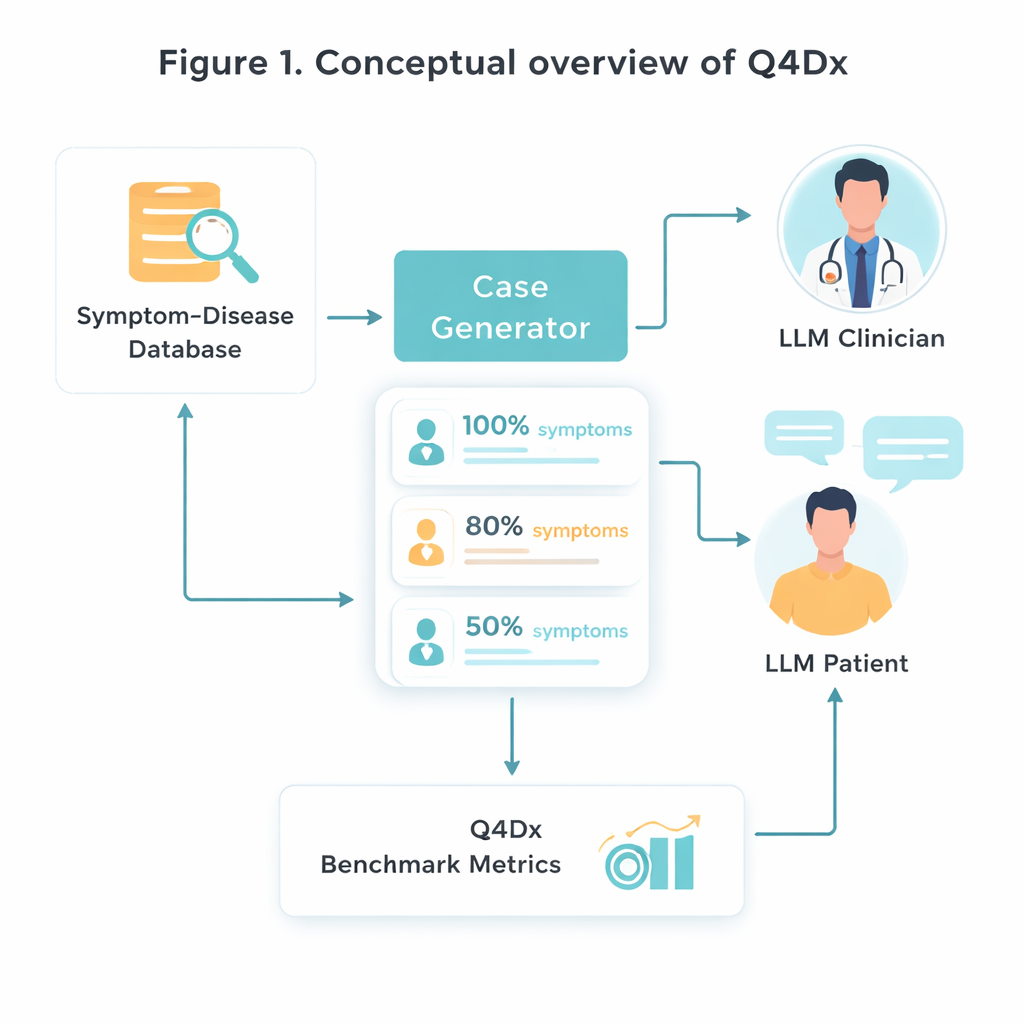
Simulierte Arzt‑Patient‑Dialoge
Das Herzstück von Q4Dx ist eine große Sammlung simulierter Gespräche zwischen zwei KI‑Agenten. Einer übernimmt die Rolle der Patientin oder des Patienten und hat vollen Zugriff auf die zugrunde liegende Krankheit und deren vollständiges Symptombild. Der andere agiert als Arzt: Er sieht zu Beginn nur eine partielle, möglicherweise vage Fallbeschreibung und muss entscheiden, was er als Nächstes fragt. Nach jeder Patientenantwort stellt der Arztagent eine vorläufige Diagnose, wodurch eine Schritt‑für‑Schritt‑Spur entsteht, wie sich sein Denken entwickelt. Indem alle Fragen, Antworten und Zwischenvermutungen aufgezeichnet werden, erfasst der Benchmark nicht nur, ob das Modell richtig liegt, sondern auch, wie es dahin gelangt. Diese KI‑generierten Fragenfolgen dienen als Referenzstrategien – nicht als perfekte medizinische Wahrheit, sondern als konsistenter Maßstab, an dem zukünftige Modelle und sogar menschliche Lernende gemessen werden können.
Gute Fragen messen, nicht nur richtige Antworten
Zur Leistungsbewertung entwerfen die Autoren drei einfache, aber sich ergänzende Messgrößen. Zero‑Shot Diagnostic Accuracy (ZDA) fragt: Wenn man dem Modell den vollständigen Fall sofort vorlegt, kann es dann sofort die richtige Krankheit nennen? Mean Questions to Correct Diagnosis (MQD) spiegelt die Effizienz wider: Wie viele Patientenfragen benötigt das Modell im Mittel, bis es erstmals die richtige Diagnose stellt, mit einer Obergrenze von fünf? Schließlich betrachtet Interrogation Sequence Efficiency (ISE) die Qualität des Fragestroms selbst – wie ähnlich die vom Modell gewählten Fragen in ihrer Bedeutung der Referenzsequenz sind. Mit diesen Metriken zeigt das Team, dass ein starkes allgemeines Modell (GPT‑4.1) bei vollständigen Informationen etwa die Hälfte der Fälle korrekt diagnostiziert, seine Genauigkeit jedoch sinkt, wenn Symptome verborgen werden. Gleichzeitig gelingen interaktive Sitzungen typischerweise nach nur wenigen gut gewählten Fragen, und die Fragen des Modells stimmen über aufeinanderfolgende Züge zunehmend mit expertenähnlichen Strategien überein.

Was das für die künftige medizinische KI bedeutet
Für Nicht‑Spezialisten ist die Botschaft dieser Arbeit klar: In der Medizin ist kluges Fragenstellen genauso wichtig wie das richtige Antworten, und KI muss in beidem bewertet werden. Q4Dx bietet einen wiederverwendbaren, öffentlich verfügbaren Rahmen, genau das zu tun. Durch realistische Patientengeschichten mit variierenden Anteilen fehlender Informationen, detaillierte Gesprächsprotokolle und klare Messgrößen für Genauigkeit und Effizienz ermöglicht der Benchmark Forschern, verschiedene KI‑Systeme zu vergleichen und sie sogar unter kontrollierten Bedingungen gegen menschliche Kliniker antreten zu lassen. Im Laufe der Zeit könnten Werkzeuge wie Q4Dx helfen, sicherere, zuverlässigere klinische Assistenzsysteme zu trainieren und zu verbessern, wie Ärztinnen, Ärzte und Studierende das diagnostische Gespräch lernen – und damit letztlich die Versorgung realer Patienten unterstützen.
Zitation: Werthaim, M., Kimhi, M., Apartsin, A. et al. A benchmark for evaluating diagnostic questioning efficiency of LLMs in patient conversations. Sci Rep 16, 6121 (2026). https://doi.org/10.1038/s41598-026-37022-y
Schlüsselwörter: medizinische KI, diagnostisches Denken, klinischer Dialog, große Sprachmodelle, Fragestellung Strategie