Clear Sky Science · de
Benchmarking von Aktionserkennungsmodellen zur Erkennung von Selbstverletzung in Studio- und Real‑World‑Datensätzen
Patienten mit digitalen Augen überwachen
In psychiatrischen Krankenhäusern arbeiten Pflegende unermüdlich daran, Patienten zu schützen, besonders jene mit Selbstgefährdung. Doch selbst das engagierteste Personal kann nicht jeden Raum jede Sekunde überwachen. Diese Studie untersucht, ob künstliche Intelligenz (KI) unterstützen kann, indem sie Videoaufnahmen von Stationenkameras automatisch nach frühen Anzeichen von Selbstverletzung durchsucht — und damit eine zusätzliche Schutzebene bietet, ohne menschliche Betreuung zu ersetzen.
Warum Selbstverletzung so schwer zu erkennen ist
Selbstverletzung — jede vorsätzliche Verletzung, die sich Menschen zufügen — geschieht häufig in kurzen, versteckten Momenten: ein schneller Kratzer unter einer Decke oder ein kleines Werkzeug, das außer Sichtweite benutzt wird. Psychiatrische Stationen verlassen sich auf regelmäßige Kontrollen und Kameraüberwachung, aber tote Winkel, Ermüdung des Personals sowie eingeschränkte Besetzung nachts oder an Feiertagen machen permanente Wachsamkeit unmöglich. Gleichzeitig wirft das Aufzeichnen und Teilen echter Patientenaufnahmen ernsthafte Datenschutz- und Ethikfragen auf. Folglich hatten Forschende nur sehr wenig realistische Videodaten, um KI‑Systeme zu trainieren, die gefährliches Verhalten in Echtzeit erkennen könnten.
Sicherere Testumgebungen für KI aufbauen
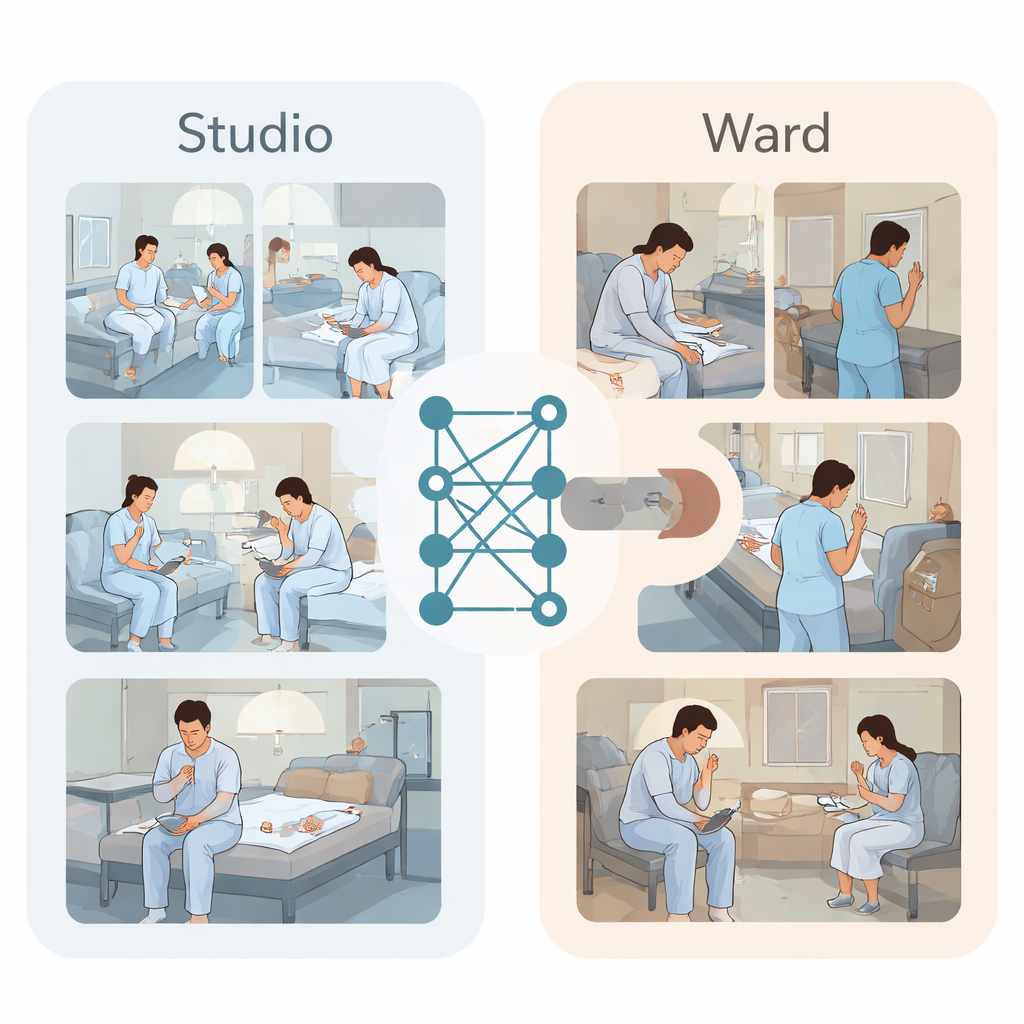
Um diese Pattsituation zu durchbrechen, erstellten die Forschenden zwei Arten von Videodatensätzen. Erstens führten sieben junge Schauspieler in Patientenkitteln in einem Studio, das einem Vierbettzimmer nachempfunden war, sorgfältig geplante Szenen auf. Sie suchten nach Alltagsgegenständen wie Plastikverschlüssen, Lippenpflegestiften oder kleinen Nägeln und spielten dann kurze Sequenzen von sich selbst zugefügten Verletzungsbewegungen am Handgelenk, Unterarm oder Oberschenkel — aufgezeichnet von Deckenkameras aus allen Ecken. Expertinnen und Experten annotierten jedes Videosegment als normales Verhalten oder Selbstverletzung und bauten so eine saubere, ausgeglichene Sammlung von 1120 Clips auf. Zweitens sammelte das Team reale Überwachungsaufnahmen aus gesicherten psychiatrischen Stationen über zehn Monate. Klinikerinnen und Kliniker durchsuchten Patientenakten nach Notizen zu Verhalten wie Kratzen, Picken oder Schneiden und fanden dann die zugehörigen Videos. Nach Verpixeln von Gesichtern und Entfernen identifizierender Details stellten sie 59 Clips mit tatsächlicher Selbstverletzung und 59 normale Clips zum Vergleich zusammen.
Die besten heutigen Video‑KI‑Modelle im Test
Mit diesen Datensätzen verglichen die Forschenden führende Aktionserkennungssysteme — Computerprogramme, die verstehen sollen, was Menschen in Videos tun. Einige basierten auf älteren Faltungsnetzwerken, die kurze Bildfolgen analysieren, während neuere, transformer‑basierte Modelle Aufmerksamkeitsmechanismen nutzen, um Muster über Raum und Zeit zu verknüpfen. Alle Modelle wurden ausschließlich mit den Studiovideos trainiert, um zu entscheiden, ob ein Clip Selbstverletzung oder normales Verhalten zeigte. Wichtig war das strikte Testschema: In jeder Runde wurden alle Clips eines Schauspielers vollständig als neue Testdaten zurückgehalten, sodass die Algorithmen nicht einfach einzelne Personen auswendig lernen konnten.
Wenn saubere Studiovideos auf chaotische Realität treffen
Bei den ordentlichen Studiomaterialien stach das fortschrittlichste Transformer‑Modell, VideoMAEv2, hervor. Es balancierte verpasste Fälle und Fehlalarme besser als die anderen und erreichte einen F1‑Score (eine kombinierte Messgröße aus Präzision und Trefferquote) von etwa 0,65, während einfachere Methoden nahe am Zufallsniveau lagen. Visuelle Erklärungen zeigten, dass dieses Modell sich eng auf die Stelle konzentrierte, an der ein Werkzeug die Haut berührte, statt von Hintergrundbewegungen abgelenkt zu werden. Sobald dieselben trainierten Systeme jedoch ohne Nachtraining auf die realen Stationsaufnahmen losgelassen wurden, sank ihre Leistung. VideoMAEv2 lag weiterhin über Zufall mit einem F1‑Score um 0,61, tat sich jedoch besonders mit subtilen Verhaltensweisen wie Picken und Kratzen schwer, die nie in den Simulationen vorkamen, sowie mit kleinen Patienten, weit entfernten oder teilweise verdeckten Personen.
Was das für die Patientensicherheit bedeutet
Zusammenfassend zeigen die Ergebnisse eine deutliche „Simulation‑zu‑Realität“-Lücke. KI‑Systeme, die bei sorgfältig inszenierten Videos vielversprechend erscheinen, können versagen, wenn sie mit dem Durcheinander, ungewöhnlichen Blickwinkeln und der Verhaltensvielfalt des realen Klinikalltags konfrontiert werden. Der wichtigste Beitrag der Studie ist kein fertig ausgereiftes Sicherheitsprodukt, sondern ein Anfang: ein öffentlicher, gut annotierter Studiodatensatz, ein sorgsam gesammelter Real‑World‑Testdatensatz und ein transparenter Benchmark, der zeigt, wo aktuelle Methoden versagen. Für Nicht‑Fachleute ist die Botschaft klar: KI kann bereits helfen, verdächtige Momente in Stationsvideostreams hervorzuheben, aber sie kann noch nicht als alleiniger Wächter vertraut werden. Um diese Lücke zu schließen, sind reichhaltigere, diversere Trainingsdaten und schlauere Modelle nötig, die unter Wahrung von Datenschutz, Fairness und klinischem Urteil entwickelt werden.
Zitation: Lee, K., Lee, D., Ham, HS. et al. Benchmarking action recognition models for self-harm detection in studio and real-world datasets. Sci Rep 16, 6850 (2026). https://doi.org/10.1038/s41598-026-36999-w
Schlüsselwörter: Erkennung von Selbstverletzung, psychiatrische Stationen, Video‑Aktionserkennung, Künstliche Intelligenz im Gesundheitswesen, Patientensicherheit