Clear Sky Science · de
MQADet: ein Plug-and-Play‑Paradigma zur Verbesserung der Open‑Vocabulary‑Objekterkennung durch multimodales Frage‑Antworten
Warum intelligentere Objektsucher wichtig sind
Telefone, Autos, Haushaltsroboter und Suchmaschinen verlassen sich zunehmend auf Software, die Objekte in Bildern finden kann: ein Kind, das die Straße überquert, Ihre verlorenen Schlüssel auf dem Tisch oder ein bestimmtes Produkt im Regal. Die meisten heutigen Systeme verstehen jedoch nur kurze, einfache Bezeichnungen wie „Hund“ oder „Auto“. Wenn Sie nach „dem kleinen Hund mit rotem Halsband, der hinter dem Sofakissen liegt“ fragen, geraten sie oft durcheinander. Dieses Papier stellt MQADet vor, einen Ansatz, mit dem bestehende Objektsuchsysteme aufgerüstet werden können, damit sie solche reichen, detaillierten Beschreibungen verstehen, ohne die zugrundeliegenden Modelle neu zu trainieren.
Von festen Listen zu offener Verständigung
Traditionelle Objektdetektoren werden auf festen Kategorienlisten trainiert, etwa den 80 Alltagsobjekten des verbreiteten COCO‑Datensatzes. Sie funktionieren gut, solange das Objekt zu einer dieser Kategorien gehört und die Anfrage kurz und eindeutig ist. Die reale Welt ist jedoch unordentlich. Menschen beziehen sich auf Dinge mit langen Phrasen, feinen Attributen und Relationen wie „der Mann in der gelben Weste, der hinter dem Lkw steht“. Neuere „Open‑Vocabulary“‑Detektoren versuchen, sich von festen Listen zu lösen, indem sie Bilder mit Text verknüpfen, haben aber nach wie vor Probleme mit komplexer Formulierung und seltenen, sogenannten Long‑Tail‑Kategorien, die nur selten in Trainingsdaten vorkommen. Zudem benötigen sie viel Rechenaufwand und Daten, um besser zu werden.
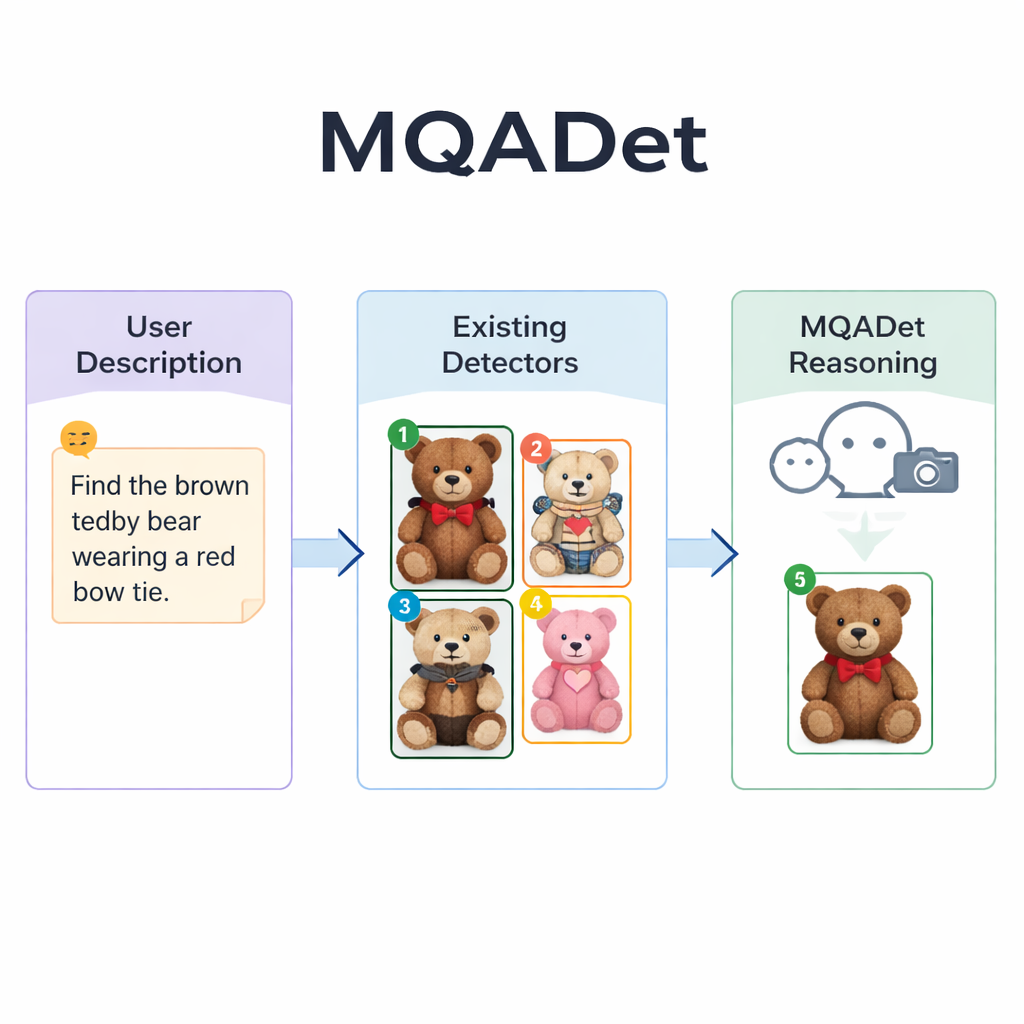
Sprachmodelle die Suche leiten lassen
MQADet begegnet diesen Problemen, indem ein multimodales großes Sprachmodell — ein System, das Bilder betrachten und Text lesen kann — über bestehende Detektoren in einem dreistufigen Frage‑Antwort‑Prozess gesetzt wird. Zuerst liest eine Stufe namens Text‑Aware Subject Extraction den gesamten Satz der Nutzerin oder des Nutzers und extrahiert die tatsächlichen Zielobjekte, etwa „Regenschirm“ und „Fußgänger“ aus einer langen Beschreibung. Das ähnelt dem, wie eine Person schnell die Hauptnomen eines Satzes identifiziert, bevor sie eine Szene absucht. Entscheidend ist, dass diese Stufe die starke Sprachverarbeitung des Modells nutzt und daher lange, beschreibende Phrasen statt nur einzelner Wörter verarbeiten kann.
Kandidaten im Bild markieren
In der zweiten Stufe, Text‑Guided Multimodal Object Positioning, übergibt MQADet die extrahierten Subjekte zusammen mit dem Bild an einen bestehenden Open‑Vocabulary‑Detektor — etwa Grounding DINO, YOLO‑World oder OmDet‑Turbo. Der Detektor schlägt mehrere mögliche Positionen im Bild vor, an denen jedes Subjekt liegen könnte, zieht um jede Kandidatenregion einen Kasten und setzt eine einfache Nummer in den Kasten. Das Ergebnis ist ein „markiertes Bild“, das alle plausiblen Optionen zeigt. Wichtig ist, dass MQADet diese Detektoren nicht neu trainiert; es verwendet sie unverändert. Dadurch ist der Ansatz plug‑and‑play: Sobald ein besserer Detektor verfügbar ist, kann er ohne zusätzliche Daten oder Feinabstimmung in die Pipeline eingebaut werden.

Durch Schlussfolgern zur besten Übereinstimmung
Die dritte Stufe, MLLMs‑Driven Optimal Object Selection, verwandelt die finale Auswahl in eine Multiple‑Choice‑Frage für das Sprachmodell: Angesichts der ursprünglichen Beschreibung und des markierten Bildes mit nummerierten Kästchen — welche Nummer passt am besten zum Text? Da das Modell sowohl die detaillierte Formulierung als auch die visuelle Anordnung sieht, kann es feinere Hinweise abwägen — Muster, Farben, räumliche Relationen wie „links“ und Interaktionen zwischen Objekten. Die Autorinnen und Autoren zeigen, dass das Weglassen dieses Schlussfolgerungsschritts die Genauigkeit stark verringert, was seine Bedeutung unterstreicht. Mit diesem dreistufigen Design verbesserte MQADet die Genauigkeit in vier anspruchsvollen Benchmarks mit langen, natürlichen Sätzen und steigerte oft die Leistung bestehender Detektoren um 10–40 Prozentpunkte, ohne deren interne Gewichte zu verändern.
Was das für alltägliche Technik bedeutet
Für Nicht‑Spezialisten ist die Kernbotschaft, dass wir Objektdetektoren nicht neu entwickeln müssen, um sie intelligenter zu machen. MQADet wirkt wie ein intelligenter Assistent, der auf bestehenden Systemen sitzt, ihnen hilft, reichhaltige menschliche Beschreibungen zu interpretieren, und das richtige Objekt in komplexen Szenen auszuwählen. Das kann visuelle Suche, Assistenzwerkzeuge und autonome Geräte zuverlässiger machen, wenn sie mit der natürlichen, detailreichen und kontextreichen Sprache der Menschen umgehen müssen — und ebnet den Weg für intuitivere, sprachgesteuerte Interaktion mit der visuellen Welt.
Zitation: Li, C., Zhao, X., Zhang, J. et al. MQADet: a plug-and-play paradigm for enhancing open-vocabulary object detection via multimodal question answering. Sci Rep 16, 6286 (2026). https://doi.org/10.1038/s41598-026-36936-x
Schlüsselwörter: Open‑Vocabulary‑Objekterkennung, multimodale große Sprachmodelle, visuelle Fragebeantwortung, Computer Vision, Bildverständnis