Clear Sky Science · de
Maschinelles Lernen zur Vorhersage von Behandlungsergebnissen bei Darmkrebs
Warum die Vorhersage von Darmkrebsergebnissen wichtig ist
Darmkrebs gehört zu den weltweit häufigsten Krebserkrankungen, und viele Patientinnen, Patienten und Angehörige möchten eine einfache, dringende Frage beantwortet haben: „Wie stehen meine Chancen und was kann getan werden, um sie zu verbessern?“ Diese Studie aus dem Iran untersucht, wie moderne Computerverfahren, bekannt als maschinelles Lernen, detaillierte Krankenakten auswerten können, um besser vorherzusagen, welche Patienten nach einer Operation ein erhöhtes Risiko haben. Durch präzisere Vorhersagen könnten Ärztinnen und Ärzte Behandlung und Nachsorge gezielter anpassen und gefährdeten Patienten bessere Chancen auf langfristiges Überleben geben.
Krankenhausdaten in nützliche Muster verwandeln
Die Forschenden nutzten zehn Jahre Daten von 764 Personen, die sich einer Darmkrebsoperation an einem großen Zentrum in Shiraz, Iran, unterzogen hatten. Für jede Person wurden 44 Informationen erhoben, darunter Alter, Blutwerte, Tumorgröße, Krebsstadium, Symptome sowie Einzelheiten zur Operation und zu Behandlungen wie Chemotherapie. Diese Aufzeichnungen wurden sorgfältig bereinigt und überprüft: unmögliche Laborwerte wurden korrigiert, Patienten ohne Nachverfolgbarkeit entfernt und fehlende Angaben durch sinnvolle Schätzungen ergänzt. Das Team teilte die Daten anschließend so auf, dass der größere Teil zur Schulung der Computermodelle diente, während ein separater Anteil zurückbehalten wurde, um zu testen, wie gut die Modelle vorhersagen konnten, wer beim Follow-up lebte oder gestorben war.
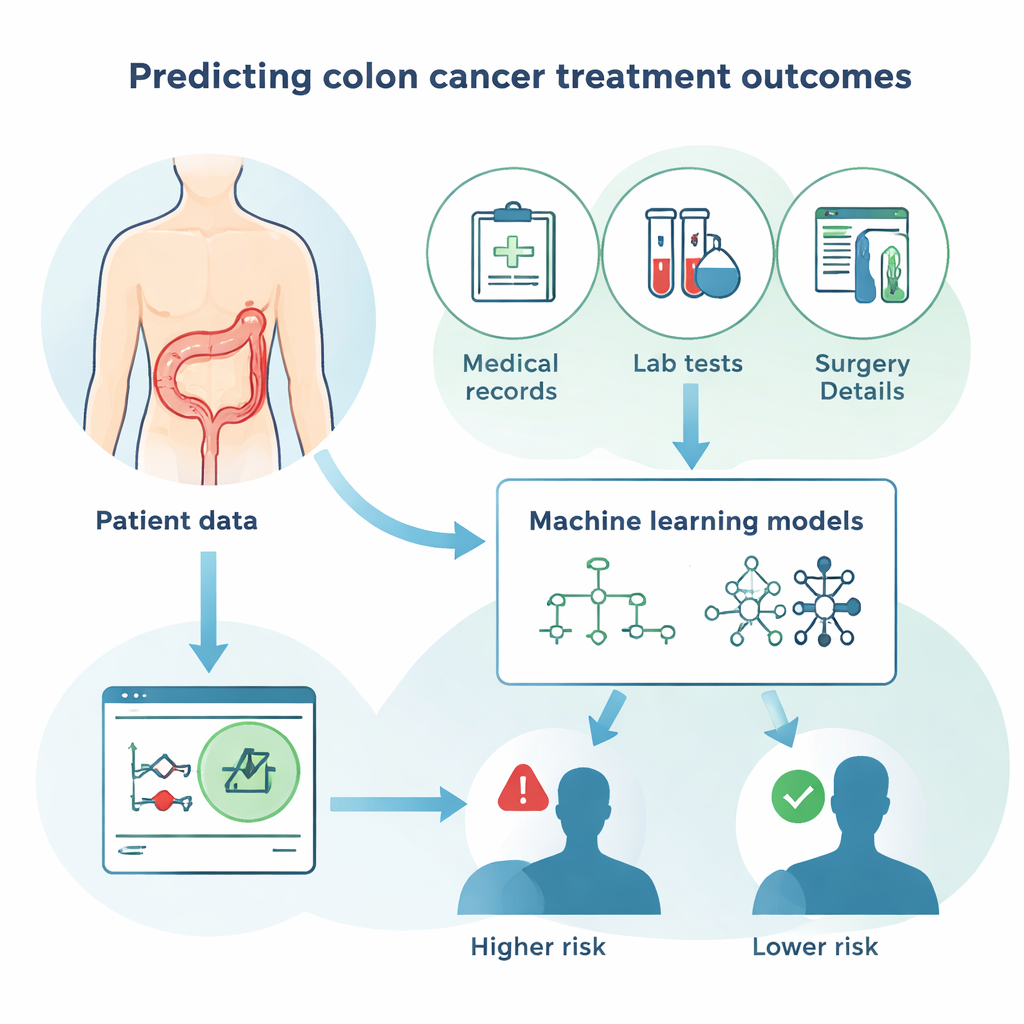
Wie intelligente Algorithmen von Patientendaten lernen
Statt sich nur auf traditionelle Statistik zu stützen, verglich die Studie mehrere moderne Computeransätze direkt miteinander. Dazu gehörten verschiedene „Forest“- und „Boosting“-Methoden, die viele einfache Entscheidungsregeln kombinieren, sowie neuronale Netze, die locker nachbilden, wie Nervenzellen verknüpft sind. Das Ziel war bei allen Methoden dasselbe: mithilfe der Patienteninformationen vorherzusagen, ob jede Person überleben würde, und diese Vorhersagen dann mit dem tatsächlichen Verlauf zu vergleichen. Beurteilt wurden die Modelle danach, wie oft sie insgesamt richtig lagen, wie gut sie Patienten erfassten, die verstarben, und wie selten sie fälschliche Alarmmeldungen bei Überlebenden erzeugten. Die besten Methoden erreichten eine Gesamtgenauigkeit von rund 80 Prozent – ein starkes Ergebnis angesichts der Komplexität von Krebsergebnissen.
Welche Modelle und Faktoren am wichtigsten waren
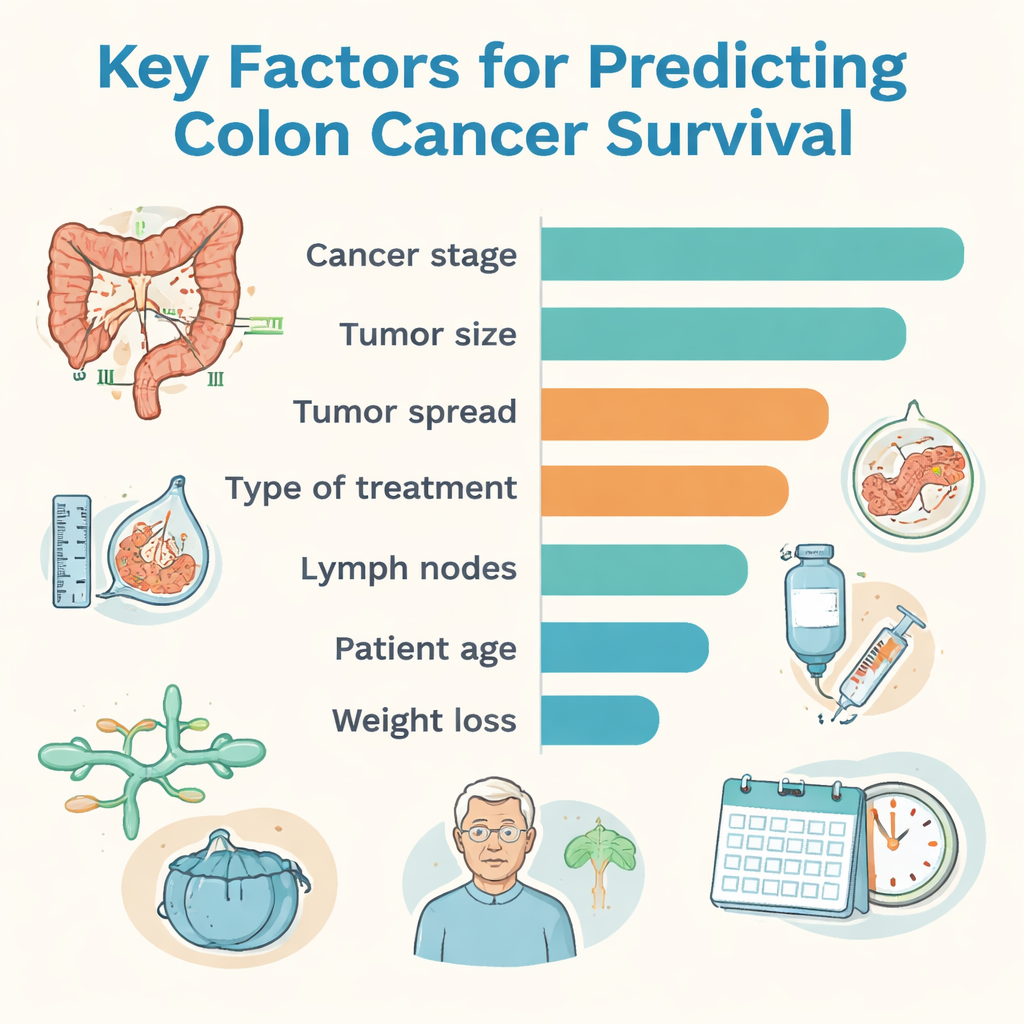
Unter den getesteten Ansätzen erzielte eine Methode namens CatBoost die höchste Gesamtgenauigkeit, während ein Random-Forest-Modell das beste Gleichgewicht zwischen dem Erkennen von Hochrisikopatienten und der Vermeidung von Überdiagnosen bei gut verlaufenden Fällen zeigte. Um die Ergebnisse für Ärztinnen und Ärzte verständlicher zu machen, nutzte das Team ein Erklärungswerkzeug, das aufzeigt, welche Informationen die Entscheidungen des Computers am stärksten beeinflussten. Das Krebsstadium – eine Zusammenfassung darüber, wie groß der Tumor ist, ob Lymphknoten betroffen sind und ob Fernmetastasen vorliegen – war der stärkste einzelne Faktor. Auch Tumorgröße, Tumorinfiltrationstiefe in die Darmwand, das Vorhandensein von Fernmetastasen, Art der Behandlung, Tumorgrad (wie abnorm die Zellen erscheinen), Befall von Lymph- und Blutgefäßen, Alter der Patientin/des Patienten sowie Gewichtsverlust spielten wichtige Rollen bei der Gestaltung der Überlebensvorhersagen.
Von Zahlen zu Entscheidungen am Krankenbett
Die Ergebnisse legen nahe, dass ein sorgfältig trainiertes Computermodell, das mit routinemäßigen klinischen Informationen gefüttert wird, Ärztinnen und Ärzten helfen kann, Patienten zu identifizieren, die nach einer Darmkrebsoperation still ein erhöhtes Risiko tragen. Im Alltag könnte ein solches Tool in die elektronische Patientenakte integriert werden und sofort Details über Tumor und Allgemeinzustand einer Person zu einer einfachen Risikoschätzung zusammenfassen. Diese Zahl würde nicht das Urteil der Ärztin oder des Arztes ersetzen, könnte aber Entscheidungen leiten – zum Beispiel, wie engmaschig eine Nachsorge sein sollte, ob zusätzliche Behandlungen die Nebenwirkungen rechtfertigen, oder wann eine Zweitmeinung sinnvoll ist. Da die vom Computer als wichtig identifizierten Faktoren mit dem übereinstimmen, was Krebsspezialisten bereits als kritisch ansehen, ist das System leichter nachvollziehbar und gegenüber Patientinnen und Patienten erklärbar.
Was das für Patientinnen, Patienten und die Zukunft bedeutet
Für Betroffene und ihre Familien ist die Kernbotschaft, dass Computer jetzt gewöhnliche medizinische Daten nutzen können, um eine personalisiertere Versorgung bei Darmkrebs zu unterstützen. Obwohl die Studie an einem einzigen Zentrum im Iran durchgeführt wurde und noch in anderen Kliniken sowie mit reichhaltigeren Daten wie genetischen und bildgebenden Informationen validiert werden muss, zeigt sie, dass maschinelles Lernen hervorheben kann, wer besondere Aufmerksamkeit benötigt und warum. Mit der Zeit, wenn mehr Daten einfließen und die Modelle weiter verbessert werden, könnten solche Werkzeuge Ärztinnen und Ärzten weltweit helfen, Behandlungen zu liefern, die nicht nur evidenzbasiert, sondern auch fein auf das jeweilige Individuum und dessen Erkrankung zugeschnitten sind.
Zitation: Ghasemi, H., Hosseini, S.V., Rezaianzadeh, A. et al. Machine learning application in colon cancer treatment outcome prediction. Sci Rep 16, 6159 (2026). https://doi.org/10.1038/s41598-026-36917-0
Schlüsselwörter: Darmkrebs, maschinelles Lernen, Behandlungsergebnisse, Risikovorhersage, klinische Daten