Clear Sky Science · de
Die Leistungslücke überbrücken: systematische Optimierung lokaler LLMs für die Extraktion japanischer medizinischer PHI
Warum das für die Privatsphäre von Patienten wichtig ist
Krankenhäuser verfügen über riesige Bestände medizinischer Notizen, die Pflege und Forschung verbessern könnten, doch diese Aufzeichnungen enthalten sensible Details wie Namen, Adressen und Daten. Leistungsfähige cloudbasierte KI‑Systeme sind sehr gut darin, diese Informationen zu verbergen, trotzdem dürfen viele Krankenhäuser rohe Patientendaten nicht an externe Server senden. Diese Studie zeigt, dass mit sorgfältigem Tuning kleinere KI‑Modelle, die vollständig vor Ort betrieben werden, überraschend nahe an die Leistung führender Cloud‑Systeme herankommen können — und so eine Möglichkeit bieten, KI zu nutzen, während Patientendaten sicher vor Ort bleiben.
Das Dilemma: Privatsphäre versus Fortschritt
Moderne große Sprachmodelle erkennen und entfernen geschützte Gesundheitsdaten (PHI) in medizinischen Texten zuverlässig und erreichen oft Genauigkeiten von über 90 Prozent. Das Senden unbearbeiteter Patientennotizen an Cloud‑Dienste wirft jedoch rechtliche und ethische Fragen nach Vorschriften wie HIPAA, GDPR und Japans APPI auf. Viele Einrichtungen bestehen auf vollständiger „Datenhoheit“, also darauf, dass Informationen ihre eigenen Rechner nie verlassen. Bisher lagen lokal betreibbare Modelle, die auf hausinterner Hardware laufen, meist deutlich hinterher und übersehen mehr Identifikatoren, sodass Krankenhäuser vor der Wahl standen: starke Analytik in der Cloud oder stärkere Privatsphäre mit schwächeren Werkzeugen. Die Autoren wollten herausfinden, ob diese Lücke so weit geschlossen werden kann, dass ein Einsatz im klinischen Alltag praktikabel wird.
Ein gestuftes Konzept für schlauere lokale KI
Das Team entwickelte einen fünfstufigen Optimierungsrahmen, um die Leistung lokaler Sprachmodelle bei der PHI‑Entfernung in japanischen Radiologieberichten schrittweise zu verbessern. Sie begannen mit 14 verschiedenen Modellen unterschiedlicher Größe, die alle auf einem isolierten, internetfreien Rechner liefen, um Krankenhaus‑Sicherheitsbedingungen zu simulieren. Mithilfe von 160 sorgfältig gestalteten synthetischen Berichten — realistisch, aber vollständig fiktiv — maßen sie, wie gut jedes Modell acht Arten von Identifikatoren fand und separierte, von Namen und Identifikationsnummern bis hin zu Daten und Abteilungen. Nach einem ersten Basistest erstellten sie allgemein hilfreichere Prompts, passten Anweisungen an die Eigenheiten einzelner Modelle an, ergänzten eine automatisierte „Selbstprüfung und Korrektur“-Schleife und prüften zuletzt die besten Kandidaten an einem reservierten Satz von Berichten. 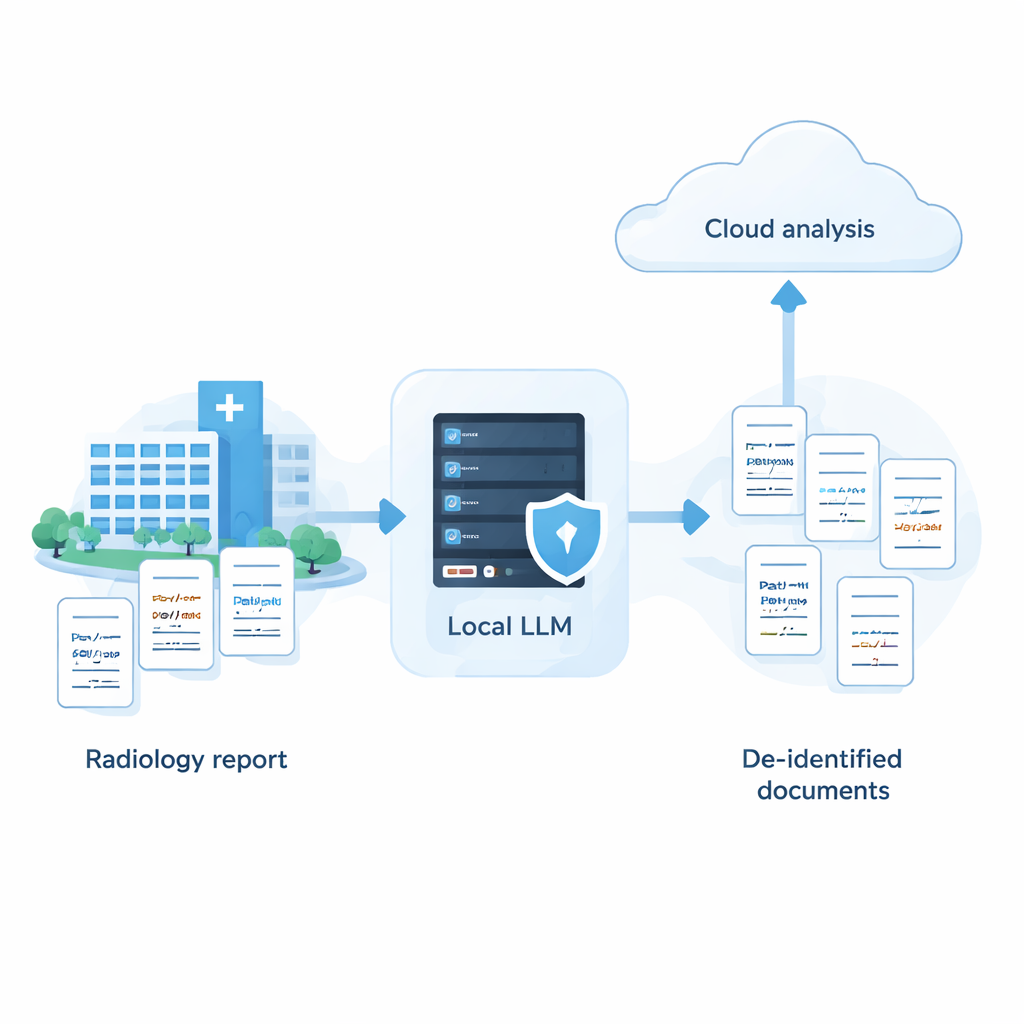
Annäherung an Cloud‑Niveau
Durch diesen gestuften Prozess stellten die Forscher fest, dass die rohe Modellgröße nicht der entscheidende Erfolgsfaktor war; einige sehr große Systeme lieferten weiterhin schwache Ergebnisse. Stattdessen waren die vielversprechendsten Modelle diejenigen, die gut auf sorgfältig gestaltete Anweisungen und Fehleranalyse reagierten. Ein mittelgroßes System, Mistral‑Small‑3.2, wurde nach maßgeschneiderten Prompts und einem Selbstoptimierungsschritt, in dem das Modell seine eigenen Ausgaben überprüfte und selektiv korrigierte, zum klaren Sieger. In den abschließenden 60 Testfällen erzielte diese optimierte lokale Konfiguration 91,54 von 100 Punkten — etwa 97,8 Prozent der 93,56 Punkte des führenden Cloud‑Modells — und hielt dabei Formatierungsregeln perfekt ein. Praktisch gesehen wurde das verbleibende Defizit als klinisch gering eingestuft. Der Hauptnachteil war die Geschwindigkeit: Die lokale Verarbeitung dauerte rund 25 Sekunden pro typischem Bericht, verglichen mit unter 2 Sekunden in der Cloud, was jedoch für routinemäßige, nicht‑dringende Batch‑Aufgaben als akzeptabel angesehen wurde. 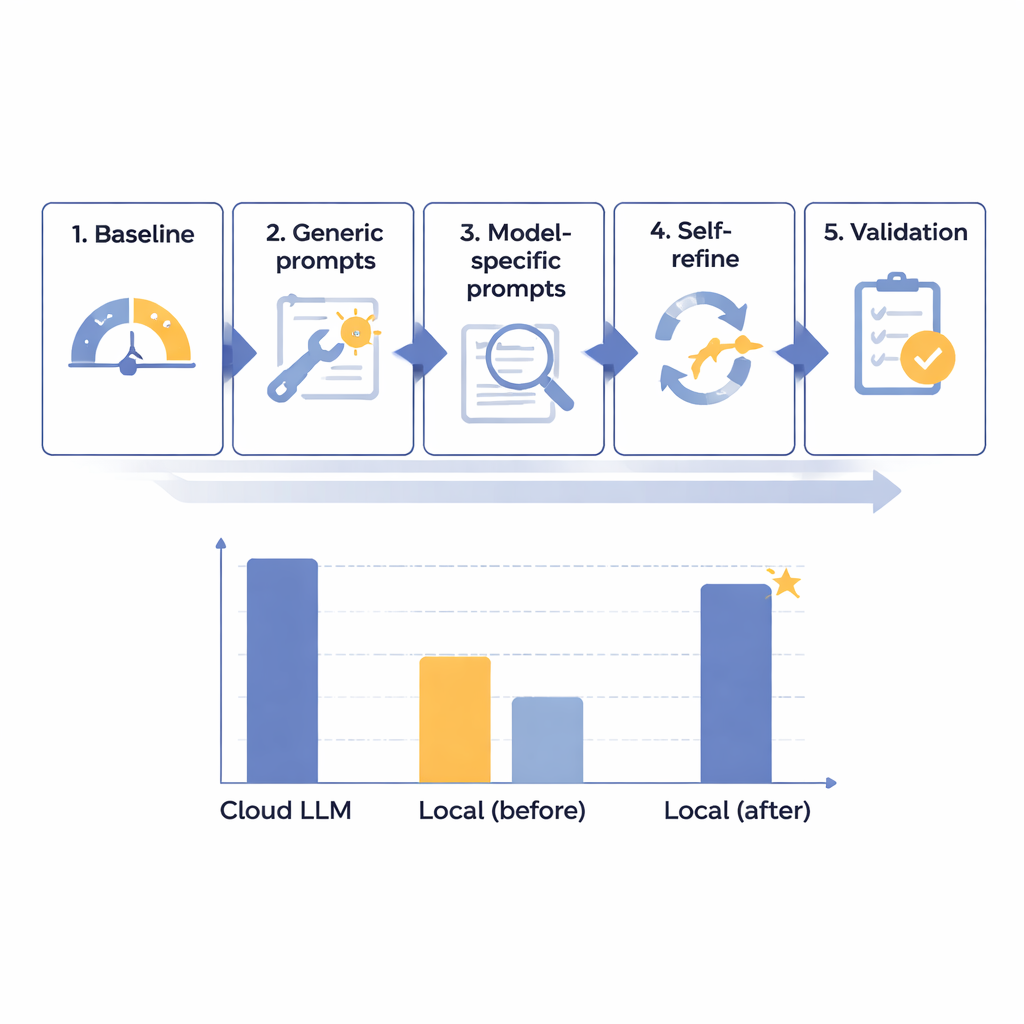
Eine überraschende Schwelle für Selbstkorrektur
Eines der interessantesten Ergebnisse war ein Art Kipppunkt um 87–88 Punkte auf der 100‑Punkte‑Skala der Autoren. Modelle, die in der Baseline unterhalb dieses Niveaus lagen — wie Mistral‑Small‑3.2 — profitierten stark von der Selbstoptimierungsschleife und gewannen nahezu sieben Punkte, indem sie einen kleinen Bruchteil ihrer eigenen Fehler korrigierten. Modelle, die bereits über dieser Schwelle starteten, zeigten kaum Verbesserungen und verschwendeten manchmal Aufwand darauf, korrekte Antworten zu „korrigieren“. Das legt nahe, dass fortgeschrittene Optimierungsmaßnahmen eher für Modelle reserviert werden sollten, die gut, aber noch nicht exzellent sind — so können Krankenhäuser Rechenleistung und Personalzeit dort konzentrieren, wo der größte Nutzen zu erwarten ist. Die Autoren warnen, dass diese Schwelle auf nur zwei Modellen basiert und bestätigt werden muss, liefern damit aber eine frühe Faustregel für die Einsatzplanung.
Was das für Krankenhäuser und Patienten bedeutet
Die Studie argumentiert, dass Krankenhäuser nicht zwischen starker Privatsphäre und leistungsfähiger KI wählen müssen. Mit einem systematischen Vorgehen — Auswahl vieler Modelle, Abstimmung von Prompts auf deren Stärken und Schwächen sowie Hinzufügen eines intelligenten Selbstüberprüfungs‑Schritts — ist es möglich, dass ein vollständig lokales System die Genauigkeit führender Cloud‑Dienste beim Entfernen sensibler Informationen aus medizinischem Text annähert. In der Praxis eröffnet das die Tür zu einer hybriden Strategie: PHI wird sicher auf krankenhausinternen Rechnern entfernt, und nur anonymisierte Berichte mit entfernten Namen und anderen Identifikatoren werden für weitergehende Analysen in die Cloud geschickt. Obwohl die bisherige Arbeit auf synthetischen japanischen Radiologieberichten basiert und an realen Daten sowie in anderen Sprachen getestet werden muss, bietet sie einen umsetzbaren Fahrplan für Einrichtungen, die KI nutzen wollen und dabei Vertrauen und Privatsphäre der Patienten in den Mittelpunkt stellen.
Zitation: Wada, A., Nishizawa, M., Yamamoto, A. et al. Bridging the performance gap: systematic optimization of local LLMs for Japanese medical PHI extraction. Sci Rep 16, 5910 (2026). https://doi.org/10.1038/s41598-026-36904-5
Schlüsselwörter: medizinische De‑Identifizierung, Patientenprivatsphäre, lokale Sprachmodelle, KI im Gesundheitswesen, Radiologieberichte