Clear Sky Science · de
Verbessertes Bayes’sches Netzwerk mit Graph Attention und Prior-Algorithmus zur Ursachenanalyse von Flugzeugtriebwerksfehlern
Warum versteckte Triebwerksprobleme wichtig sind
Jeder kommerzielle Flug hängt von Strahltriebwerken ab, die tausende Stunden unter extremer Hitze und Druck laufen. Wenn etwas schiefgeht, können Fluggesellschaften durch Verspätungen, annullierte Flüge und ungeplante Reparaturen Millionen verlieren. Die tiefsten Ursachen schwerer Triebwerksausfälle beginnen oft als winzige Risse oder chemische Schäden in Metallteilen — Dinge, die Sensoren nicht direkt erfassen können. Dieses Papier stellt eine neue Methode vor, um Fehler bis zu diesen verborgenen Ursprüngen zurückzuverfolgen, selbst wenn die Daten knapp sind und zugunsten kleiner alltäglicher Störungen verzerrt sind.
Die Herausforderung, den wirklichen Übeltäter zu erkennen
Moderne Triebwerke sind so zuverlässig, dass schwere Ausfälle selten sind. Das ist gut für die Sicherheit, führt aber zu einem Datenproblem: Wartungsdatenbanken sind voller Einträge zu häufigen, wenig gravierenden Problemen, während wirklich gefährliche Ursachen nur sehr selten auftreten. Hinzu kommt, dass Sensoren meist höherstufige Symptome erfassen — etwa Schubverlust oder ungewöhnliche Vibrationen — und nicht mikroskopische Schäden wie Korrosion an Korngrenzen oder winzige Risse. Traditionelle statistische Methoden und klassische Bayessche Netzwerke, die Ursache–Wirkungs-Beziehungen hauptsächlich aus gemeinsamen Auftretenshäufigkeiten lernen, neigen dazu, sich auf diese häufigen, aber weniger schweren Ereignisse zu konzentrieren. Dadurch übersehen sie oft die seltenen, tiefsitzenden Fehler, die tatsächlich ein Triebwerk außer Betrieb setzen.
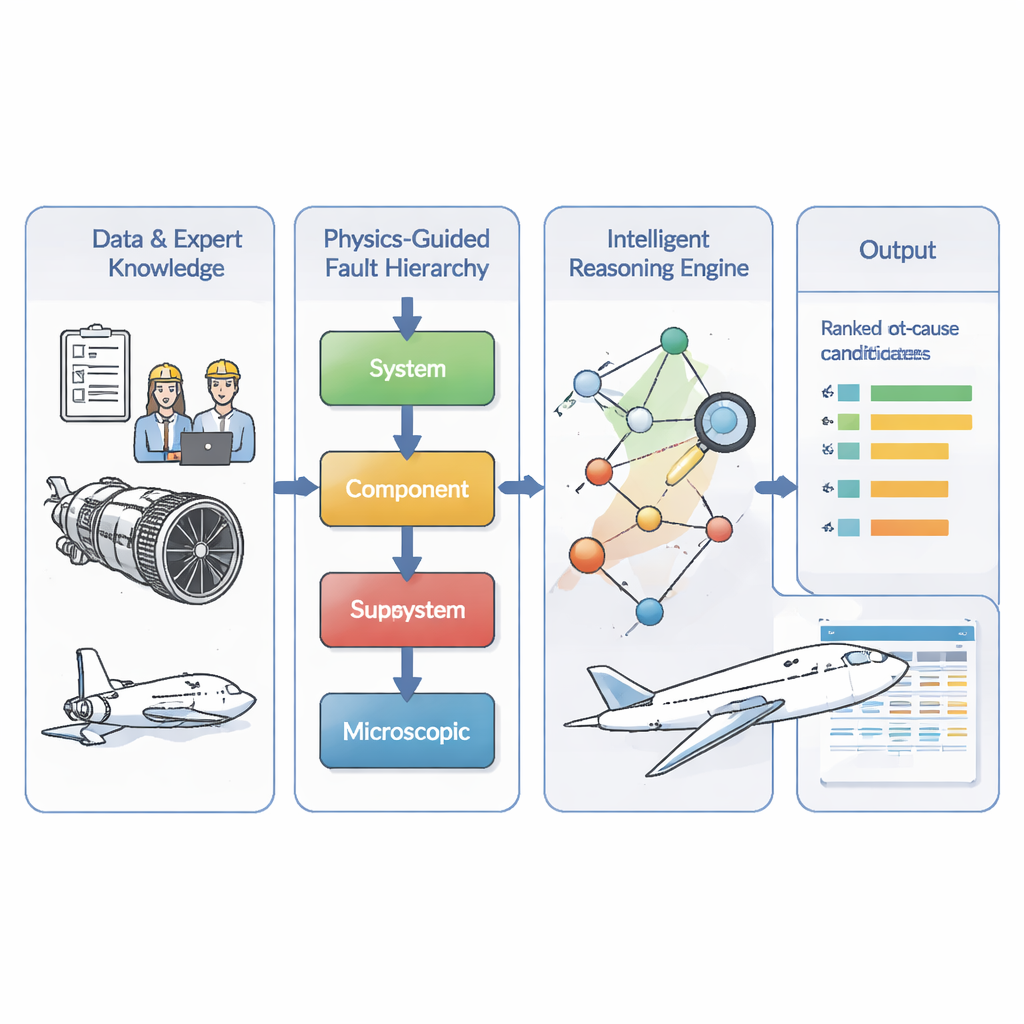
Eine geschichtete Karte, wie sich Fehler ausbreiten
Die Autoren begegnen diesem Problem, indem sie zunächst das ingenieurwissenschaftliche Verständnis darüber kodieren, wie Triebwerksprobleme verlaufen. Sie teilen Fehler in vier Ebenen ein: mikroskopische Materialschäden, Ausfall eines konkreten Bauteils, Fehlfunktionen eines Teilssystems wie Kraftstoff- oder Schmierungssystem und schließlich systemweite Folgen wie eine Abschaltung im Flug. Ihr Modell erzwingt eine einfache Regel: Ursachen müssen von tieferen zu höheren Ebenen fließen — von Mikroschäden über Bauteilausfall zu Teilsystemproblemen bis hin zu allgemeinen Triebwerkssymptomen. Das erzeugt eine gerichtete „Fehlerkarte“, die die physikalische Realität widerspiegelt und unmögliche Abkürzungen oder Rückkopplungen ausschließt, die durch begrenzte Daten fälschlich nahegelegt werden könnten. Aufbauend auf Wartungsaufzeichnungen von 634 realen Triebwerksereignissen nutzt das Team ein Standard-Suchverfahren, um wahrscheinliche Verknüpfungen innerhalb dieser geschichteten Struktur zu füllen, und lässt das resultierende Netzwerk anschließend von Experten prüfen und korrigieren.
Dem Modell beibringen, was die Daten nicht zeigen
Weil die gefährlichsten Fehler selten sind, fügt das Team zwei Arten zusätzlicher Intelligenz hinzu. Zuerst durchforsten sie den gesamten Datensatz nach Assoziationsregeln — Mustern wie „Wenn dieses Lager ausfällt, wird häufig niedriger Öldruck beobachtet“ — mithilfe eines klassischen Markt-Korb-ähnlichen Algorithmus. Diese Regeln werden als Vorwissen darüber behandelt, wie wahrscheinlich es ist, dass ein Problem ein anderes nach sich zieht. Ein leichtgewichtiges Attention-Mechanismus lernt dann, wie stark diesen Priors auf jeder Ebene der Hierarchie vertraut werden soll. Zum Beispiel stützt sich das Modell bei der Schätzung von Wahrscheinlichkeiten für mikroskopische Ursachen mit sehr wenigen Beispielen automatisch stärker auf globale Muster und weniger auf unsichere lokale Statistiken. Dieses adaptive Zusammenführen hilft, die Unterschätzung tiefer Fehler zu korrigieren, die allein aus Rohzählungen entstünde.
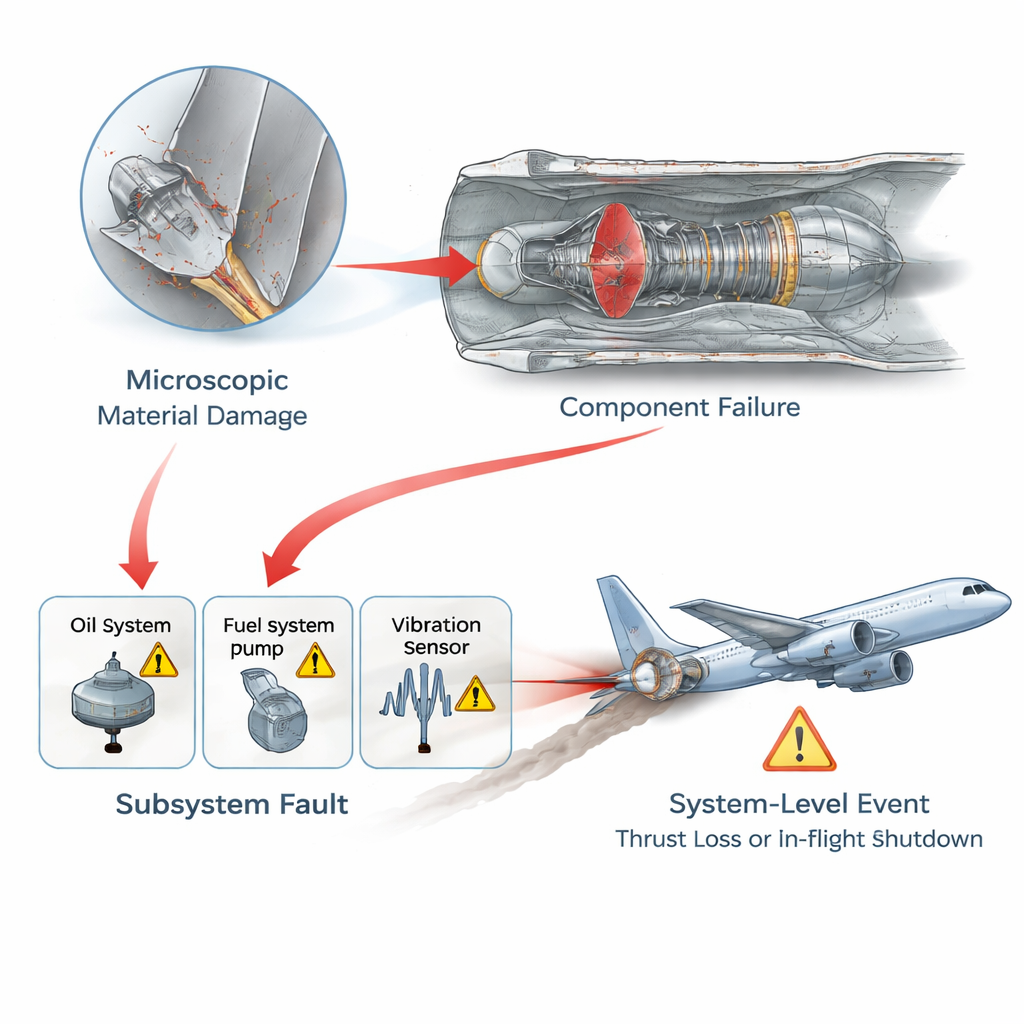
Dem Netzwerk erlauben, die wirklich kritischen Fehler hervorzuheben
Als zweite Ergänzung integrieren die Autoren ein Graph-Attention-Modul, das die Struktur des Fehlernetzwerks selbst betrachtet. Jeder Knoten — der einen spezifischen Fehler oder ein Symptom darstellt — lernt einen kompakten numerischen Fingerabdruck basierend auf seinen Nachbarn und darauf, wie Informationen durch den Graphen fließen. Damit weist das Modell jedem Knoten einen „Kritikalitäts‑Score“ zu, der widerspiegelt, wie zentral er für ernsthafte Fehlerketten ist, nicht nur wie häufig er auftritt. Es erzeugt außerdem eine separate, strukturbezogene Schätzung dafür, wie stark ein Knoten wahrscheinlich einen anderen verursacht. Die endgültige Wahrscheinlichkeit für eine beliebige Fehlerverbindung ist dann eine gewichtete Mischung aus der datenbasierten Schätzung und diesem neuronalen Prior, wobei das Gewicht von der Kritikalität des Knotens abhängt. Einfach ausgedrückt werden häufige, aber unbedeutende Warnsignale leiser gewichtet, während seltene, strukturell entscheidende Ursachen zusätzliche Aufmerksamkeit erhalten.
Das Verfahren auf die Probe gestellt
Die Forscher vergleichen ihr vollständiges Modell — GAT‑BN genannt — mit einer Reihe von Alternativen, darunter Standard-Bayessche Netzwerke, ein Random-Forest-Klassifikator, ein Graph Convolutional Network und ein traditioneller ingenieurwissenschaftlicher Ansatz, der auf Fehlerbäumen und Fehlermodusanalysen basiert. Mit zwei eingängigen Messgrößen — wie oft die wahre Ursache unter den Top‑1‑ oder Top‑3‑Vorhersagen erscheint und wie nahe die vorhergesagten Wahrscheinlichkeiten an der Realität sind — liegt die neue Methode durchweg vorn. Sie ist besonders stark, wenn Daten knapp sind, einige Aufzeichnungen unvollständig sind und wenn die Ursache ein seltenes mikroskopisches Versagen ist. Während GAT‑BN rechenintensiver ist als einfachere Modelle, argumentieren die Autoren, dass Trainings‑ und Inferenzzeiten für moderne Ingenieursarbeitsstationen praktisch bleiben.
Was das für sicherere Flüge bedeutet
Für Nicht‑Spezialisten ist die Hauptaussage, dass diese Arbeit einen intelligenteren Weg bietet, um unordentliche Wartungsdaten und komplexes Expertenwissen zu durchforsten und den eigentlichen Auslöser von Triebwerksausfällen zu identifizieren. Durch die Kombination einer physikbasierten Fehlerleiter, aus historischen Aufzeichnungen gewonnenen Mustern und eines Netzwerks, das lernt, welche Probleme wirklich zählen, kann das GAT‑BN‑Modell seltener, aber gefährlicher Zustände zuverlässiger melden, bevor sie sich verschlimmern. Obwohl die Studie sich auf eine Triebwerksreihe konzentriert und eine statische Sicht auf Fehler verwendet, deutet der Ansatz einen breiteren Weg an: Zukünftige Diagnosesysteme könnten weniger von riesigen, perfekt ausbalancierten Datensätzen abhängen und mehr auf sorgfältig strukturierte Kenntnisse in Verbindung mit gezieltem maschinellen Lernen setzen.
Zitation: Yuan, L., Han, G. & Dong, P. Improved bayesian network with graph attention and prior algorithm for aircraft engine fault root cause analysis. Sci Rep 16, 5924 (2026). https://doi.org/10.1038/s41598-026-36883-7
Schlüsselwörter: Fehler von Flugzeugtriebwerken, Ursachenanalyse, Bayessche Netzwerke, Graph Attention, vorausschauende Instandhaltung