Clear Sky Science · de
Objekterkennung auf Low-Compute-Edge-SoCs: ein reproduzierbares Benchmark und Einsatzrichtlinien
Warum winzige Chips für intelligente Kameras wichtig sind
Viele der „intelligenten“ Geräte um uns herum – Sicherheitskameras, Drohnen, Fabriksensoren und Türklingeln – müssen Personen und Objekte in Echtzeit erkennen, nutzen dafür aber sehr kleine, energiesparende Chips statt stromhungriger Rechenzentren. Unternehmen wählen häufig populäre YOLO-Objekterkennungsmodelle, doch die in Datenblättern angegebenen Geschwindigkeiten sagen wenig darüber aus, wie gut die Systeme im Feld wirklich laufen. Dieses Paper nimmt neun moderne YOLO-Varianten experimentell unter die Lupe und testet sie auf drei weit verbreiteten, kostengünstigen Rockchip-Prozessoren, um zu zeigen, was tatsächlich Geschwindigkeit, Energieverbrauch und Zuverlässigkeit bestimmt, wenn Intelligenz an den Rand verlagert wird.
Drei alltägliche Chips unter dem Mikroskop
Die Autor:innen konzentrieren sich auf drei kommerzielle System-on-Chips (SoCs), die viele eingebettete Bildverarbeitungssysteme unauffällig antreiben: den kleinen RV1106, den mittelklassigen RK3568 und den leistungsfähigeren RK3588. Jeder kombiniert gewöhnliche Prozessorkerne mit einer dedizierten Neural Processing Unit (NPU) und externem Speicher. Auf diesen Plattformen setzen die Forschenden neun YOLO-Modelle ein – drei Generationen (YOLOv5, YOLOv8, YOLO11) in drei Größen (Nano, Small, Medium) – alle auf dem gleichen Benchmark-Datensatz trainiert. Sie wandeln die Modelle sorgfältig in ein gemeinsames Format um, quantisieren sie auf 8-Bit-Arithmetik, kompilieren mit Rockchips Tools und führen Hunderte zeitlich gemessener Tests durch, um stabile Messwerte für Latenz, Leistung und Energie pro verarbeiteter Bildframe zu erhalten.
Geschwindigkeit ist nicht das, was das Datenblatt vermuten lässt
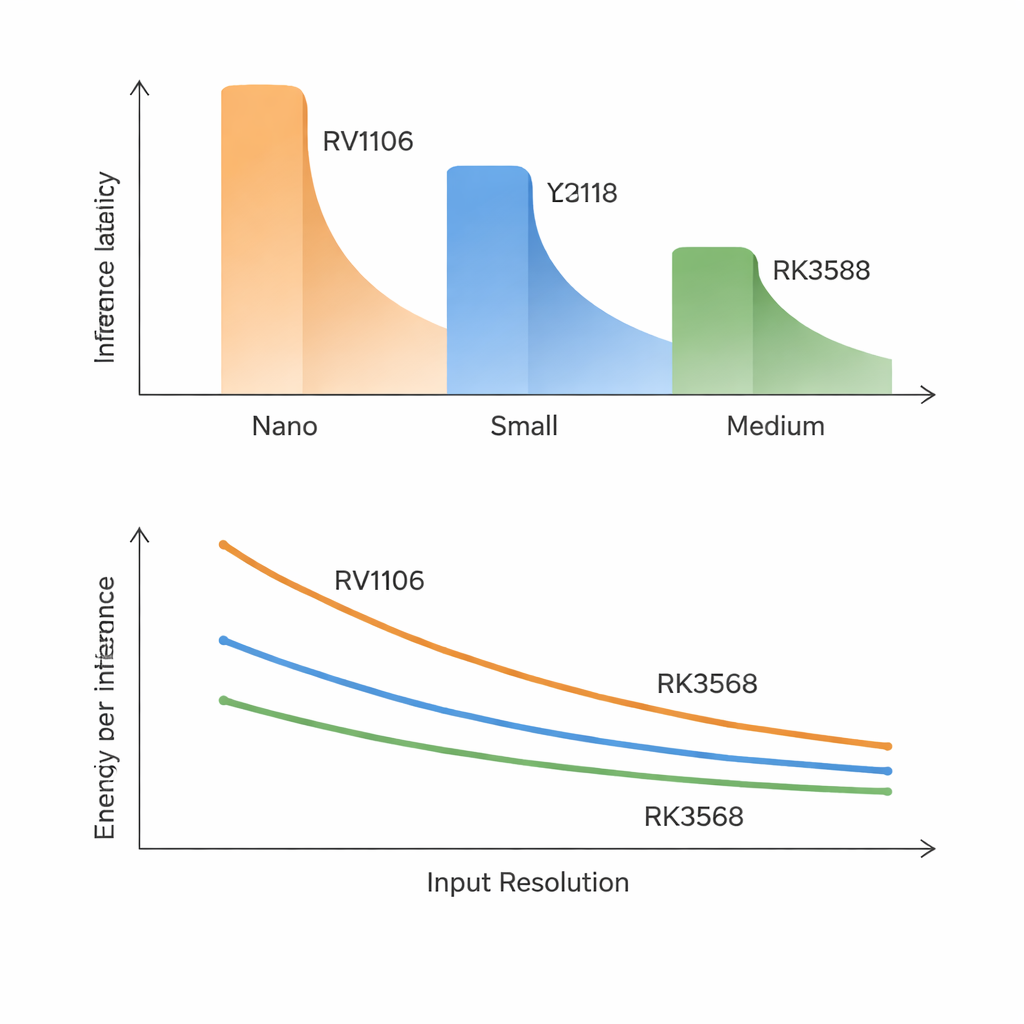
Eines der klarsten Ergebnisse ist, dass traditionelle Modell- und Chipkennzahlen schlechte Prädiktoren für die reale Geschwindigkeit sind. Auf dem langsamsten Chip brauchen selbst die kleinsten Modelle etwa 70–100 Millisekunden pro Frame, und mittelgroße Modelle sind für Echtzeitanwendungen praktisch zu langsam. Der schnellste Chip kann Nano- und viele Small-Modelle in die Nähe von 30 Bildern pro Sekunde bringen, größere Modelle erreichen aber weiterhin keine sehr hohen Bildraten. Überraschenderweise korreliert die Latenz stärker mit der Genauigkeit eines Modells als mit der Anzahl der Rechenoperationen oder Parameter. Neuere, genauere YOLO-Designs fügen interne Bausteine hinzu, die zwar die Genauigkeit verbessern, für diese NPUs jedoch schwer auszuführen sind – „intelligenter“ bedeutet auf dieser Hardware oft „merklich langsamer”.
Wenn größere Bilder und geteilter Speicher zurückschlagen
Die Studie zeigt, dass größere Eingabebilder nicht einfach eine gleichmäßige Zunahme der Arbeit bedeuten. Theoretisch sollte eine Verdopplung von Breite und Höhe die Kosten vervierfachen, doch auf Chips mit geringer Bandbreite kann die Kostensteigerung sogar schneller verlaufen. Mit wachsender Bildgröße passen Zwischendaten nicht mehr bequem in den lokalen Speicher und müssen wiederholt zum externen Speicher geschoben werden. Auf den kleinsten und mittelklassigen SoCs gerät das zu einem Verkehrsstau: mittelgroße Modelle verlangsamen sich weit mehr als erwartet, und intensive Hintergrundspeichernutzung durch andere Aufgaben kann die Latenz um 50–270 % erhöhen. Im Gegensatz dazu bewältigt der RK3588 mit deutlich höherer Speicherbandbreite Auflösungssteigerungen gelassen und zeigt unter zusätzlicher CPU- oder Speichernutzung kaum Reaktion, was verdeutlicht, dass Speichergeschwindigkeit – nicht reine Rechenleistung – oft der eigentliche Engpass ist.
Mehr Kerne und mehr Leistung garantieren keine Effizienz
Rockchips schnellster Chip verfügt über eine dreikernige NPU, aber das Aufteilen von YOLO über mehrere Kerne bringt nur mäßige Vorteile. Für die meisten Modelle reduziert das Verteilen auf zwei oder drei Kerne die Latenz um weniger als 10 %, und manchmal verschlechtert sich die Leistung sogar. Der Overhead zur Koordination der Kerne und das Teilen desselben Speicherpools macht einen Großteil des theoretischen Nutzens zunichte. Die Leistungsaufnahmen fügen eine weitere Nuance hinzu: Alle drei SoCs ziehen beim Betrieb nur wenige Watt, doch die Energie pro verarbeitetem Frame kann um den Faktor drei variieren. Das höherwertige RK3588 verbraucht in jedem Moment mehr Leistung, beendet die Arbeit aber so schnell, dass es oft die energieeffizienteste Wahl ist, besonders für mittelgroße Modelle und höhere Auflösungen.
Praktische Erkenntnisse für Geräte in der realen Welt
Für Leser:innen, die über smarte Kameras, Roboter oder IoT-Geräte nachdenken, ist die Botschaft klar. Auf den kleinsten Chips sind nur die winzigsten YOLO-Modelle bei moderaten Bildgrößen praktikabel, und selbst dann ist Echtzeitvideo nur eingeschränkt möglich. Mittelklasse-Chips können Small-Modelle und gelegentlich Medium-Modelle unterstützen, wenn Bildraten oder Batterielaufzeit gelockert werden können. Der High-End-RK3588 macht es schließlich realistisch, genauere, mittelgroße YOLO-Varianten auszuführen und dabei die Energie pro Frame im Griff zu behalten. Insgesamt plädiert das Paper dafür, Modelle mit Blick auf die Zielhardware auszuwählen, der Speicherbandbreite besondere Aufmerksamkeit zu schenken und speichersparende Tricks größeren Netzwerken vorzuziehen. Entscheidend ist nicht die beworbene Tera-Operationen-pro-Sekunde-Zahl, sondern ob das Gesamtsystem in der unordentlichen Realität schnell, stabil und energieeffizient Objekterkennung liefern kann.
Zitation: Kong, C., Li, F., Yan, X. et al. Object detection on low-compute edge SoCs: a reproducible benchmark and deployment guidelines. Sci Rep 16, 5875 (2026). https://doi.org/10.1038/s41598-026-36862-y
Schlüsselwörter: Edge-AI, Objekterkennung, eingebettete Bildverarbeitung, YOLO-Modelle, stromsparendes SoC