Clear Sky Science · de
Varianzschätzung auf Basis von Machine Learning bei Zweiphasen-Stichproben unter Verwendung von Gesundheits- und Bildungsdaten
Warum intelligentere Mittelwerte für reale Entscheidungen wichtig sind
Wann immer Ärztinnen und Ärzte Blutdruck untersuchen oder Lehrkräfte die Noten von Schülerinnen und Schülern verfolgen, interessiert sie nicht nur der Durchschnitt; sie müssen wissen, wie stark die Werte um diesen Durchschnitt streuen. Diese Streuung, genannt Variabilität, bestimmt etwa, wie viele Patientinnen und Patienten für eine Studie rekrutiert werden sollten, wie umfangreich ein Förderprogramm sein muss, oder wie verlässlich politische Entscheidungen sind. Die hier zusammengefasste Studie stellt eine neue, statistisch fundierte Methode vor, um diese Variabilität genauer zu messen, indem klassische Stichprobenideen mit modernem Machine Learning kombiniert und an Gesundheits- und Bildungsdaten getestet werden.
Streuung messen, wenn Informationen lückenhaft sind
In einer idealen Welt hätten Forschende vor einer Befragung bereits mehr Details zu jeder Person in der Population: Alter, Lerngewohnheiten, Krankengeschichte und mehr. In Wirklichkeit sind solche Informationen oft lückenhaft oder teuer zu erheben. Die Autorinnen und Autoren arbeiten mit einem Design, das Zweiphasen-Stichprobe genannt wird, um damit umzugehen. In der ersten Phase ziehen sie eine große, relativ preiswerte Stichprobe und erfassen einfache Hintergrundinformationen wie Alter oder Internetzugang. In der zweiten Phase entnehmen sie einer kleineren Untersample eine detailliertere, kosten- oder zeitintensivere Messung, etwa den systolischen Blutdruck oder die Abschlussnote. Die Herausforderung besteht darin, diese beiden Informationsebenen zu nutzen, um zu schätzen, wie stark das Ergebnis in der gesamten Population wirklich variert.
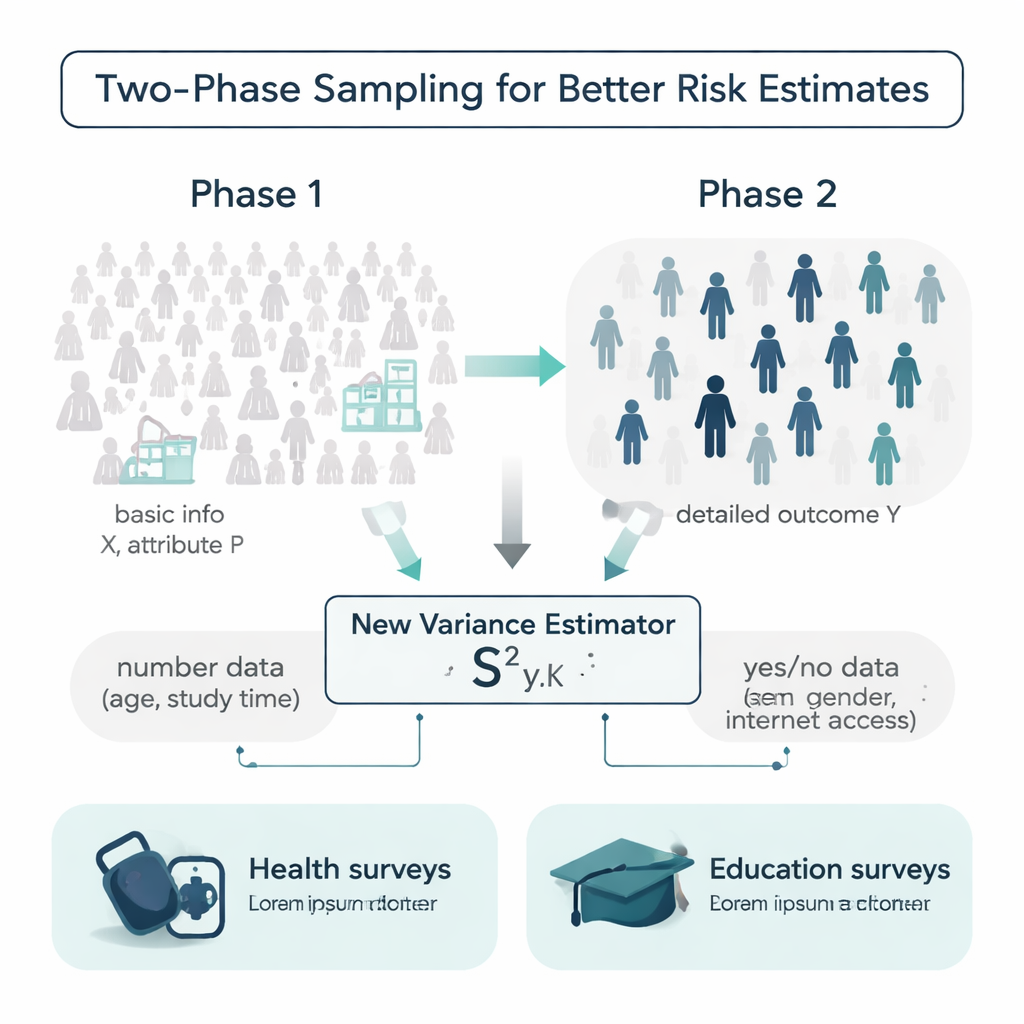
Ein neuer Schätzer, der Zahlen und Ja/Nein-Merkmale zusammen nutzt
Die meisten traditionellen Verfahren zur Messung von Variabilität stützen sich nur auf das Ergebnis selbst oder auf eine einzelne Hilfsvariable und gehen häufig davon aus, dass die Daten bequemen glockenförmigen Verteilungen folgen. Die Autorinnen und Autoren schlagen einen neuen Varianzschätzer vor, der gleichzeitig zwei Arten von Zusatzinformation verwendet: eine numerische Hilfsvariable (zum Beispiel Alter oder wöchentliche Lernzeit) und ein binäres Merkmal (wie Geschlecht oder Internetzugang). Sie zeigen mathematisch, wie sich dieser kombinierte „Misch“-Schätzer verhält und leiten Formeln für seinen Bias und den mittleren quadratischen Fehler ab — zwei zentrale Genauigkeitsmaße. Unter vernünftigen Bedingungen ist der Schätzer praktisch unverzerrt, und sein erwarteter Fehler ist kleiner als der etablierter Vergleichsverfahren, was bedeutet, dass er mit derselben Datenmenge schärfere Unsicherheitsabschätzungen liefern sollte.
Leistungstests über viele Datenwelten hinweg
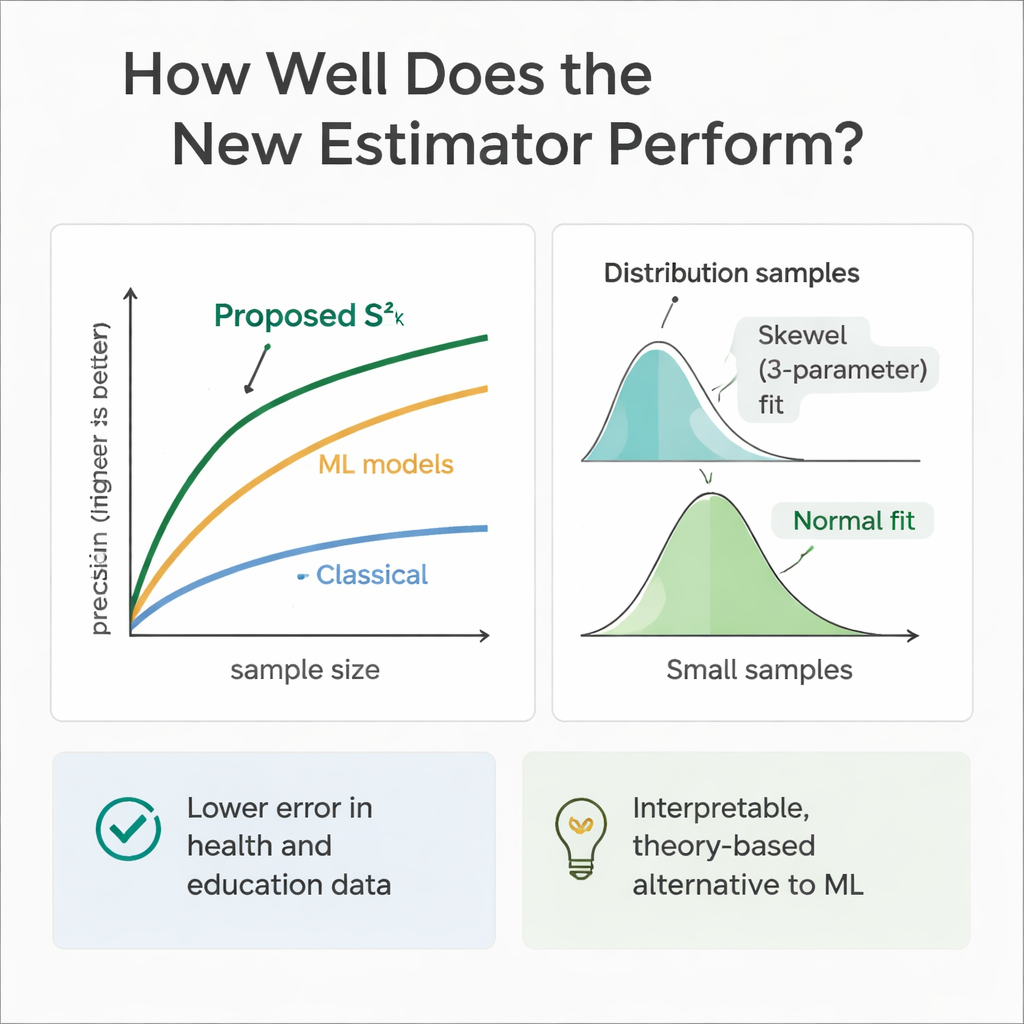
Um zu prüfen, ob Theorie und Praxis übereinstimmen, führten die Forschenden umfangreiche Computersimulationen durch. Sie simulierten Populationen, in denen Hilfsvariablen und Ergebnisverteilungen eine Bandbreite von symmetrischen (Normal- und Gleichverteilung) bis hin zu schiefen Verteilungen (Gamma und Weibull) abbildeten. Durch wiederholte Ziehungen verglichen sie den Fehler des neuen Schätzers mit dem mehrerer etablierter Methoden über verschiedene Stichprobengrößen hinweg. In nahezu allen Szenarien, insbesondere bei größeren Stichproben, zeigte der neue Ansatz eine deutlich höhere relative Effizienz — oft reduzierte sich der Fehler um 30 bis 70 Prozent gegenüber dem klassischen Varianzschätzer. Die Autorinnen und Autoren untersuchten außerdem, wie sich die Stichprobenverteilung des Schätzers selbst verhält und fanden, dass für mäßige Stichprobengrößen eine flexible Drei-Parameter-Weibull-Kurve am besten passt, während sie mit wachsender Stichprobengröße zu einer Normalverteilung tendiert.
Echte Daten aus Kliniken und Klassenzimmern
Die Methode wurde anschließend in zwei realen Fallstudien angewendet. In einem Gesundheitsdatensatz war das Ergebnis der systolische Blutdruck, mit dem Alter als numerischer Hilfsvariable und dem Geschlecht als binärem Merkmal. In einem Bildungsdatensatz war das Ergebnis die Abschlussnote, die Hilfsvariable die wöchentliche Lernzeit und das Merkmal, ob die Schülerin oder der Schüler Internetzugang hatte. In beiden Fällen lieferte der vorgeschlagene Schätzer den geringsten mittleren quadratischen Fehler unter allen getesteten statistischen Konkurrenzverfahren und straffte damit die geschätzte Variabilität um den mittleren Blutdruck bzw. um die durchschnittliche Schülerleistung deutlich. Diese Verbesserung führt zu präziseren Konfidenzintervallen und verlässlicheren Vergleichen zwischen Gruppen oder Interventionen.
Wie sich das gegen Machine Learning behauptet
Da Machine-Learning-Modelle bei Vorhersagen oft sehr gut abschneiden, trainierten die Autorinnen und Autoren zusätzlich Regressionsbäume, Random Forests und Support Vector Regression auf den gleichen simulierten Gesundheits- und Bildungsszenarien. Diese Modelle, gespeist mit denselben Hilfsvariablen, erreichten häufig vergleichbare oder leicht bessere reine Vorhersagegenauigkeit als der neue Schätzer. Allerdings verhalten sie sich wie Black Boxes: Es ist schwer nachzuvollziehen, wie genau sie Informationen kombinieren, und ihnen fehlen die klaren Formeln, die für klassische Stichprobeninferenz nötig sind. Der vorgeschlagene Schätzer hingegen ist transparent und in der Stichprobentheorie verankert, was seine Anwendung in regulatorischen, klinischen oder politischen Kontexten erleichtert, in denen Erklärbarkeit genauso wichtig ist wie rohe Leistung.
Was das praktisch für Umfragen bedeutet
Kurz gesagt zeigt diese Arbeit, dass Forschende zuverlässigere Maße der Streuung erhalten können, ohne die Stichprobengrößen drastisch zu erhöhen, indem sie diszipliniert selbst minimale Zusatzinformationen nutzen, die sie ohnehin erheben. Durch die Kombination eines numerischen Faktors (wie Alter oder Lernzeit) mit einem einfachen Ja/Nein-Merkmal (wie Geschlecht oder Internetzugang) in einem zweistufigen Stichprobenplan liefert der neue Schätzer schärfere, stabilere Varianzschätzungen als lang etablierte Verfahren. Während fortgeschrittene Machine-Learning-Werkzeuge weiterhin nützliche Vergleichsmaßstäbe bleiben, bietet dieser Ansatz eine praktische und interpretierbare Zwischenlösung, die Gesundheits- und Bildungsanalytikerinnen und -analytikern hilft, aus begrenzten Daten stärkere Schlussfolgerungen zu ziehen.
Zitation: Al-Marzouki, S., Nafisah, I.A., Dalam, M.E.E. et al. Machine learning based variance estimation under two phase sampling using health and education sector data. Sci Rep 16, 7760 (2026). https://doi.org/10.1038/s41598-026-36844-0
Schlüsselwörter: Stichprobenverfahren, Varianzschätzung, Machine Learning, Gesundheitsdaten, Bildungsforschung