Clear Sky Science · de
Bewertung von drei KI-Chatbots zur Erstellung von Multiple-Choice-Fragen in der klinischen Hämatologie für Medizinstudierende
Intelligentere Prüfungsfragen für die Ärztinnen und Ärzte von morgen
Multiple-Choice-Tests klingen vielleicht nicht aufregend, formen aber still und leise die Fähigkeiten künftiger Ärztinnen und Ärzte. Jede Prüfungsfrage kann beeinflussen, wie Studierende über reale Patientinnen und Patienten denken. Diese Studie stellt eine aktuelle Frage: Können moderne KI-Chatbots beschäftigte medizinische Lehrende dabei unterstützen, gute Prüfungsfragen im Bereich Blutkrankheiten schneller zu erstellen, ohne Qualität oder Sicherheit zu opfern?
Wie KI beim Erstellen von Prüfungsfragen half
Die Forschenden konzentrierten sich auf drei weit verbreitete KI-Chatbots, die alle zur Textgenerierung entwickelt wurden. Sie baten jedes System, 50 Multiple-Choice-Fragen zur Hämatologie zu erstellen, dem Fachgebiet, das Blutkrankheiten wie Anämie und Leukämie untersucht. Die Fragen sollten fünf häufige Themen abdecken, die in Prüfungen und der klinischen Praxis vorkommen: Panzytopenie (niedrige Werte aller Blutzellen), Anämie, Thrombozytopenie (niedrige Thrombozyten) sowie zwei Gruppen von Blutkrebserkrankungen, die myelo- und lymphoproliferative Syndrome genannt werden. Insgesamt erzeugten die Chatbots 150 Fragen in weniger als einer halben Minute pro System — eine enorme Zeitersparnis im Vergleich zur manuellen Erstellung. 
Prüfung der KI-erstellten Fragen unter dem Mikroskop
Geschwindigkeit allein ist bedeutungslos, wenn die Fragen falsch, verwirrend oder unfair sind. Um die Qualität zu prüfen, bewerteten drei erfahrene Hämatologie-Lehrende — die nicht wussten, welcher Chatbot welche Frage erstellt hatte — jeden einzelnen Item mithilfe einer detaillierten Checkliste. Sie bewerteten wissenschaftliche Richtigkeit, klinische Relevanz, Klarheit der Formulierung, Realismus der falschen Antwortoptionen und die Gesamtqualität auf einer fünfstufigen Skala. Außerdem beurteilten sie, ob jede Frage das richtige Schwierigkeitsniveau für Medizinstudierende hatte und ob sie starke von schwächeren Studierenden unterscheiden könnte. Fragen, die mindestens 15 von 25 Punkten erreichten, galten als akzeptabel für den Einsatz; andere benötigten Überarbeitung oder mussten abgelehnt werden.
Welcher Chatbot schnitt am besten ab?
Alle drei Systeme lieferten überwiegend solide Fragen, aber ein Modell stach hervor. In den Expertenbewertungen erzielte dieser Chatbot die höchsten Werte für Richtigkeit, klinische Relevanz und glaubwürdige falsche Antworten. Jede seiner 50 Fragen erfüllte die Annahmeschwelle, und keine musste geändert werden. Die beiden anderen Modelle schnitten ebenfalls gut ab: Mehr als neun von zehn ihrer Fragen waren ausreichend, brauchten aber kleinere Nachbesserungen, oft weil eine falsche Option zu offensichtlich falsch war oder eine Formulierung klarer sein könnte. Insgesamt waren sich die Expertinnen und Experten einig, dass alle drei Werkzeuge schnell Prüfungsinhalte erzeugen können, die sehr nahe an der Einsatzreife für den Unterricht sind. 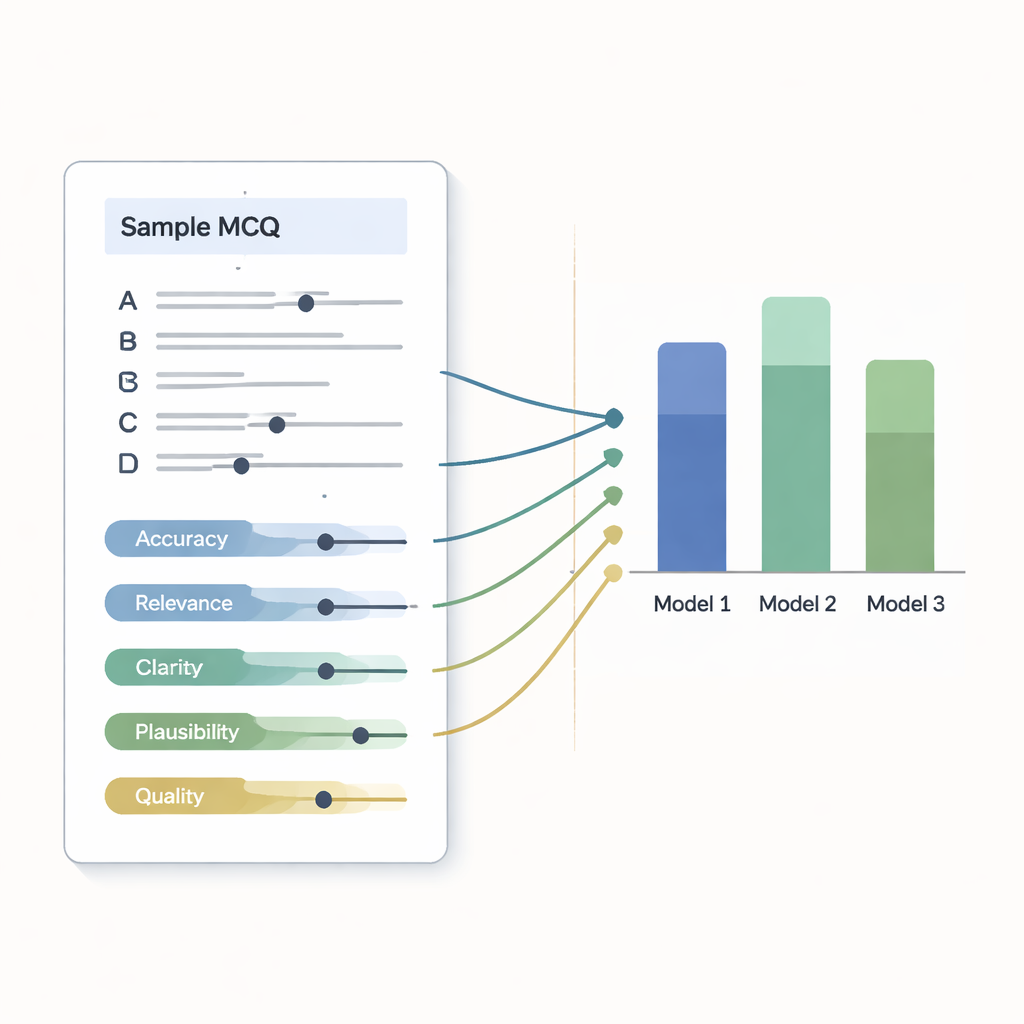
Denkskills statt nur Auswendiglernen
Das Team untersuchte außerdem, welche Art von Denken diese KI-erstellten Fragen von Studierenden verlangten. Anhand der Bloom’schen Taxonomie — einem Rahmen, mit dem Lehrende geistige Fertigkeiten klassifizieren — ordneten sie Fragen einfachen Wissens- und Verständnisaufgaben gegenüber höheren Kompetenzen wie Anwenden von Fakten, Analysieren von Situationen und Bewerten von Optionen zu. Überraschenderweise erzeugten die Chatbots überwiegend höherwertige Fragen. Bei einem Modell verlangten über 90 % der Items von den Studierenden, klinische Szenarien durchzudenken, statt nur Fakten abzurufen. Basisabfragemöglichkeiten waren bei allen drei Systemen relativ selten. Dieses Muster legt nahe, dass große Sprachmodelle, die auf riesigen Mengen vernetzter Texte trainiert wurden, von Natur aus zu kontextreichen, problemlösenden Szenarien neigen statt zu einfachen Karteikarten-ähnlichen Aufgaben.
Versprechen, Grenzen und die Notwendigkeit menschlicher Partner
Trotz dieser Stärken deckte die Studie wichtige Lücken auf. Kein Chatbot schlug von sich aus bildbasierte Fragen vor, die in der Hämatologie entscheidend sind, wenn Ärztinnen und Ärzte Mikroskoppräparate und Laborgraphiken interpretieren müssen. Auf direkte Nachfrage nach bildbasierten Items gaben zwei Systeme zu, dass sie diese nicht liefern könnten, und eines lieferte einen qualitativ schlechten Versuch. Die Studie stützte sich außerdem auf Expertenmeinungen statt auf echte Prüfungsdaten von Studierenden, sodass sie nicht vollständig belegen kann, wie gut diese Fragen in Live-Prüfungen funktionieren würden. Die Autorinnen und Autoren betonen, dass Lehrende weiterhin Fakten prüfen, Formulierungen verfeinern und sicherstellen müssen, dass grundlegende Konzepte ausreichend abgedeckt sind.
Was das für die künftige medizinische Ausbildung bedeutet
Für die interessierte Öffentlichkeit lautet die Quintessenz: KI ersetzt nicht die medizinischen Lehrenden, sie wird aber zu einer mächtigen Unterstützung. In dieser Studie generierten Chatbots schnell überwiegend genaue, klinisch realistische Fragen, die Studierenden beim Training der Entscheidungsfindung bei Blutkrankheiten helfen. Ein Modell stellte dabei besonders hochwertige Fragen bereit, die Expertinnen und Experten mit nur wenig oder gar keiner Änderung verwenden würden. Dennoch übersahen die Maschinen einfachere Wissensabfragen und konnten visuelles Material nicht eigenständig bewältigen. Die Autorinnen und Autoren kommen zu dem Schluss, dass die beste Vorgehensweise eine Partnerschaft ist: Die KI übernimmt die schwere Arbeit des Entwerfens vielfältiger Fragen, während menschliche Expertinnen und Experten die Eingaben steuern, fehlende Grundlagen ergänzen, Inhalte verifizieren und mit sich ändernden medizinischen Leitlinien Schritt halten.
Zitation: Boufrikha, W., Sallem, A., Laabidi, B. et al. Evaluation of three artificial intelligence chatbots for generating clinical hematology multiple choice questions for medical students. Sci Rep 16, 5802 (2026). https://doi.org/10.1038/s41598-026-36839-x
Schlüsselwörter: medizinische Ausbildung, künstliche Intelligenz, hämatologie, Multiple-Choice-Fragen, Chatbots