Clear Sky Science · de
Diagnose und Stadieneinteilung der steatotischen Leberkrankheit mittels klinischer und laborchemischer Daten mithilfe von Machine Learning
Warum Fettlebererkrankung für alle wichtig ist
Die Fettlebererkrankung hat sich stillschweigend zu einem der häufigsten chronischen Leberprobleme weltweit entwickelt und betrifft rund ein Drittel der Erwachsenen – sogar viele Menschen, die sich vollkommen gesund fühlen. Lagert sich zu viel Fett in der Leber ab und wird dies nicht frühzeitig erkannt, kann sich daraus über die Zeit eine Vernarbung, Leberversagen und in Einzelfällen Leberkrebs entwickeln. Die besten verfügbaren Tests sind jedoch entweder invasiv, wie eine Nadelbiopsie, oder sie beruhen auf teuren Geräten, die viele Praxen nicht haben. Diese Studie untersucht, ob einfache, routinemäßige Blutwerte und Körpermessungen kombiniert mit modernen Computermethoden einen leichteren Weg bieten, um zu erkennen, wer eine Fettleber hat und wie weit die Erkrankung fortgeschritten ist.
Eine stille Krankheit, die ernst werden kann
Die steatotische Lebererkrankung – oft kurz Fettleber genannt – beginnt, wenn sich Fett in den Leberzellen einlagert. Zunächst verursacht diese Ansammlung (einfache Steatose) meist keine Beschwerden und wird oft zufällig entdeckt. Mit der Zeit kann das Fett jedoch Entzündungen und Schäden in der Leber auslösen, die zu Vernarbung (Fibrose), Verhärtung des Gewebes und im schlimmsten Fall zu Zirrhose und Leberversagen führen. Weil die frühen Stadien still verlaufen, aber noch umkehrbar sind, ist es entscheidend, die Erkrankung vor der Entwicklung schwerer Vernarbung zu erkennen. Das Problem ist, dass viele weit verbreitete Werkzeuge zur Einstufung von Leberschäden – etwa spezielle Ultraschallgeräte oder blutbasierte Scores – entweder zu teuer, nicht flächendeckend verfügbar oder bei Menschen mit Adipositas, die besonders gefährdet sind, weniger zuverlässig sind.
Routinemäßige Untersuchungen als Lebergesundheitstest nutzen
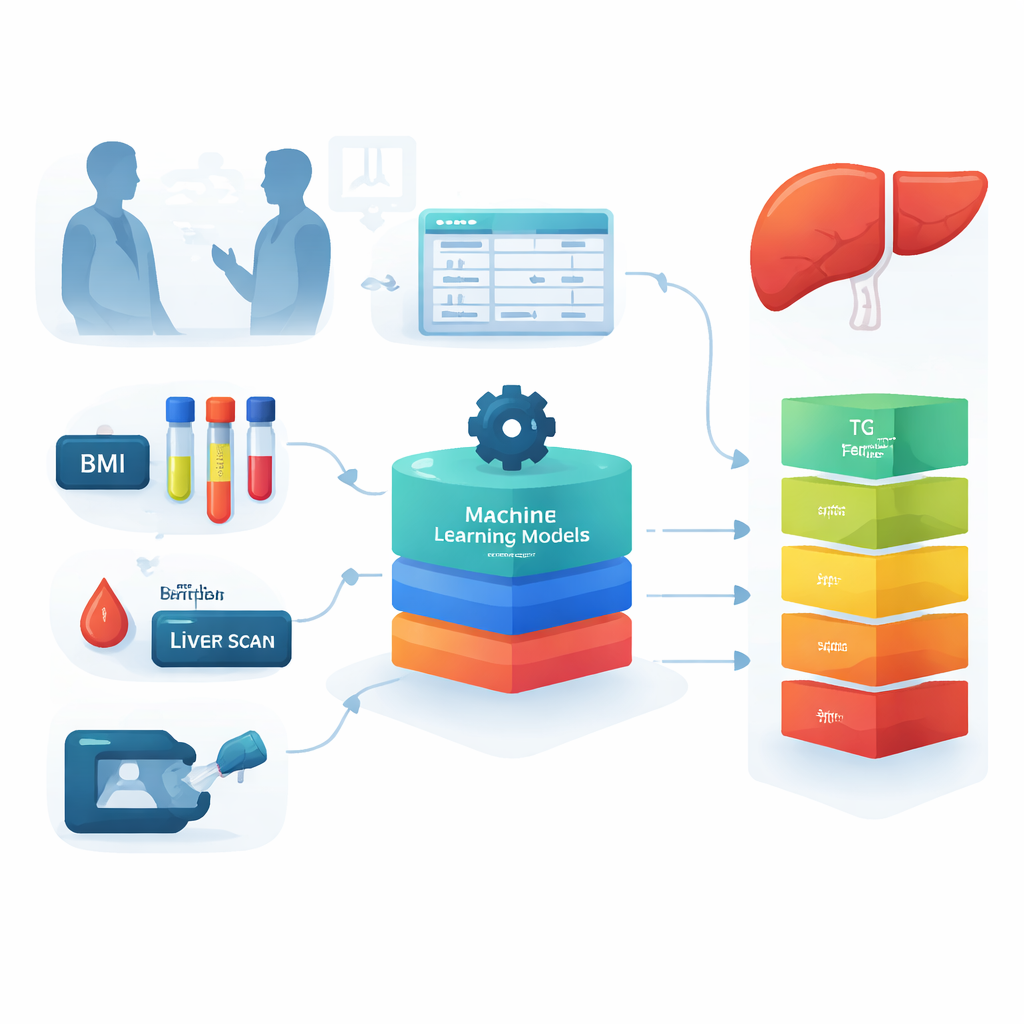
Die Forschenden fragten, ob alltägliche klinische Informationen in ein leistungsfähiges Screening-Instrument überführt werden können. Sie nutzten Akten von 210 erwachsenen Patienten einer gastroenterologischen Klinik in Teheran, Iran. Bei jeder Person wurden Basismaße wie Größe und Gewicht sowie Standard-Bluttests erhoben, etwa Cholesterin, Triglyceride, Nüchternblutzucker, Leberenzyme und eisenbezogene Marker. Das Ausmaß der Fettablagerung und Vernarbung war bereits mit einem spezialisierten Gerät namens FibroScan gemessen worden, wodurch die Teilnehmenden in fünf Gruppen eingeteilt werden konnten: von gesunden Lebern über leichte, moderate und schwere Fettablagerung bis hin zu fortgeschrittener Vernarbung. Diese Gruppen dienten als „Ground Truth“ zum Trainieren und Testen der Computermodelle.
Datenvermehrung und Training der Modelle
Da 210 Patientendaten für Machine Learning relativ wenig sind, erzeugte das Team zusätzliche „synthetische“ Patientenakten, indem sie kontrollierte zufällige Variationen zu den realen Daten hinzufügten. Sie überprüften, dass diese simulierten Datensätze weiterhin den gleichen Gesamtmustern wie die Originaldaten folgten, und erweiterten so den Datensatz auf 1.500 Proben. Dann testeten sie acht verschiedene Machine-Learning-Ansätze, darunter Entscheidungsbäume, Random Forests, Support Vector Machines und neuronale Netze sowie Kombinationen dieser Methoden. Jedes Modell sollte vorhersagen, zu welcher der fünf Lebergesundheitsgruppen eine Person gehörte, allein auf Basis der klinischen und laborchemischen Daten. Die Leistung wurde nicht nur anhand der Gesammtgenauigkeit beurteilt, sondern auch danach, wie selten ein erkrankter Mensch fälschlich als gesund eingestuft wurde – ein kritischer Aspekt für jedes Screening-Instrument.
Die wenigen wichtigen Messwerte herausfinden
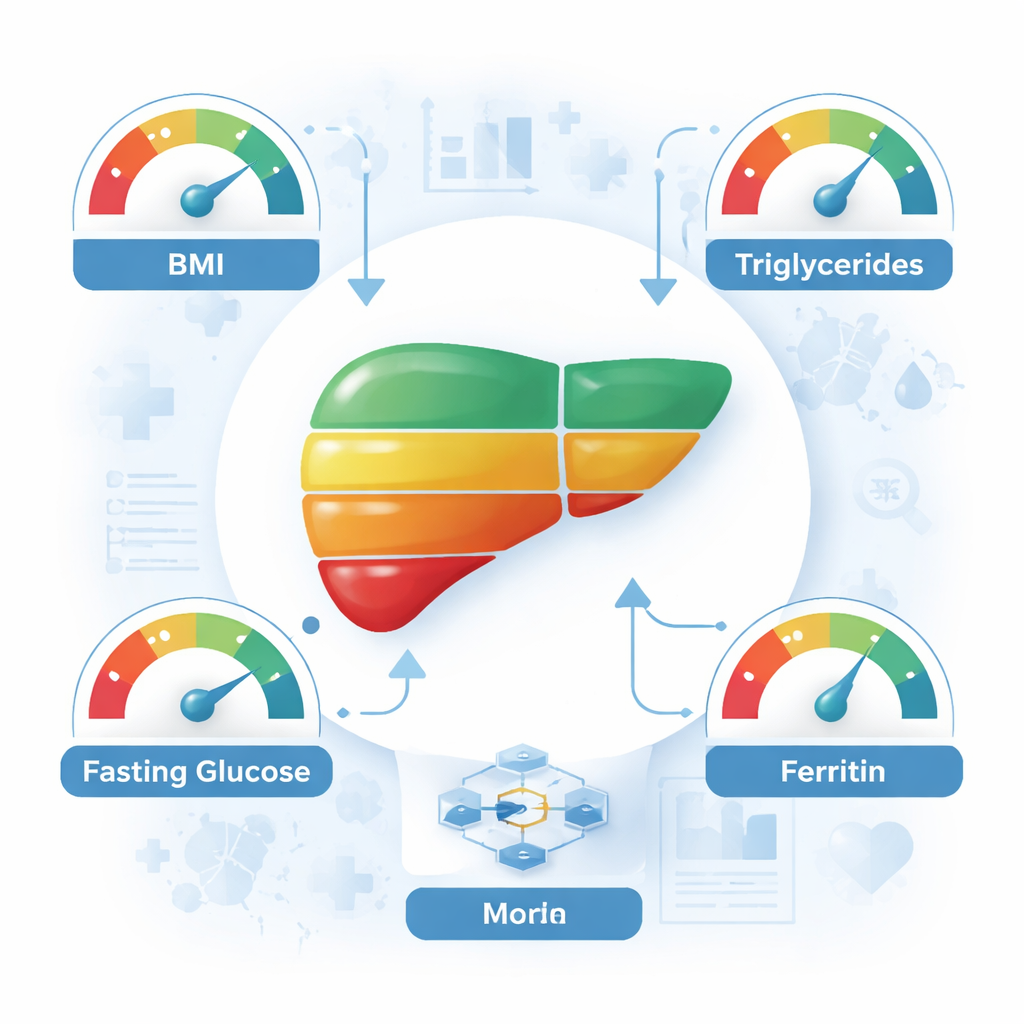
Einige der Modelle, insbesondere ein Hybrid aus Support Vector Machines und einem Boosting-Verfahren (SVM–XGBoost), erreichten bei Nutzung aller 26 verfügbaren Merkmale rund 93 % Genauigkeit. Um das Instrument einfacher und leichter anwendbar zu machen, untersuchten die Forschenden anschließend, welche Messgrößen am stärksten zu den Vorhersagen beitrugen. Statistische Verfahren hoben zunächst acht besonders wichtige Merkmale hervor, darunter Body-Mass-Index (BMI), Triglyceride, Nüchternblutzucker, Ferritin (ein Eisenspeicherprotein), Thrombozyten, alkalische Phosphatase, Kreatinin und ein Messwert zur Blutgerinnung. Leberfachärzte prüften diese Ergebnisse und wählten vier Messgrößen aus, die sowohl biologisch stark mit der Erkrankung verknüpft als auch im Alltag praktikabel sind: BMI, Triglyceride, Nüchternblutzucker und Ferritin. Bemerkenswerterweise klassifizierten Modelle, die nur mit diesen vier Eingangsgrößen trainiert wurden, die Patientinnen und Patienten weiterhin in etwa 70 % der Fälle korrekt – mit der besten Methode sogar bis zu 76 %.
Was das für Patientinnen, Patienten und Praxen bedeutet
Für Laien ist die wichtigste Botschaft: Eine Handvoll routinemäßiger Werte aus einer Standarduntersuchung – Gewicht und Größe zur Berechnung des BMI sowie einfache Bluttests für Fette, Zucker und Eisenspeicher – kann in Kombination mit gut gestalteten Computermodellen ein überraschend detailliertes Bild der Lebergesundheit liefern. Solche Werkzeuge ersetzen nicht die ärztliche Beurteilung oder spezialisierte Bildgebung, wenn diese verfügbar sind, bieten aber eine vielversprechende Möglichkeit, Menschen mit erhöhtem Risiko zu identifizieren, insbesondere in Einrichtungen mit begrenzten Ressourcen und in Regionen, in denen die Fettlebererkrankung weit verbreitet ist. Eine frühere Erkennung kann Lebensstiländerungen wie Gewichtsreduktion, gesündere Ernährung und mehr körperliche Aktivität anstoßen, die nachweislich die Lebergesundheit verbessern. Diese Studie deutet darauf hin, dass Ihre regulären Laborwerte in naher Zukunft als Frühwarnsystem für eine stille, aber ernste Erkrankung dienen könnten.
Zitation: Sadeghi, B., Zarrinbal, M., Poustchi, H. et al. Diagnosis and grading of steatotic liver disease via clinical and laboratory data using machine learning. Sci Rep 16, 6866 (2026). https://doi.org/10.1038/s41598-026-36834-2
Schlüsselwörter: Fettlebererkrankung, Machine Learning, Bluttests, BMI und Triglyceride, nichtinvasive Diagnose