Clear Sky Science · de
Generalisierbarkeit und Übertragbarkeit von Machine‑Learning‑Modellen mit hyperspektralen Reflexionsdaten für Mais‑Merkmale
Warum das Scannen von Pflanzenblättern für unsere Ernährung wichtig ist
Eine wachsende Bevölkerung unter einem sich wandelnden Klima zu ernähren, erfordert Kulturpflanzen, die Hitze, Trockenheit und andere Belastungen aushalten. Züchter möchten wissen, welche Pflanzen die richtige Kombination aus Blattstruktur, Chemie und photosynthetischer Leistung besitzen – doch diese Merkmale direkt an Tausenden von Pflanzen zu messen, ist zeitaufwändig und zerstörerisch. Diese Studie untersucht, ob das bloße Scannen von Maisblättern mit einem hyperspektralen Sensor in Kombination mit Machine Learning zuverlässig für aufwändige Labormessungen einspringen kann, selbst wenn die Pflanzen in verschiedenen Jahren und unter wechselnden Feldbedingungen angebaut werden.
Licht‑Fingerabdrücke von Maisblättern
Jedes Blatt reflektiert Licht in einem Muster, das von seinen Pigmenten, dem Wassergehalt und der inneren Struktur abhängt. Hyperspektrale Sensoren erfassen dieses Muster über Hunderte von Wellenlängen vom sichtbaren bis zum kurzwelligen Infrarot und erzeugen so einen detaillierten „Fingerabdruck“ jedes Blatts. Die Forschenden sammelten solche Fingerabdrücke aus einer vielfältigen Maispopulation, die über drei aufeinanderfolgende Feldsaisons angebaut wurde, sowie 25 Merkmale, die Blattanatomie (wie spezifische Blattfläche und C–N‑Verhältnis), Gaswechsel (wie Blätter CO2 aufnehmen und Wasser verlieren) und Chlorophyll‑Fluoreszenz (ein Einblick in Effizienz und Regulation der Photosynthese) beschreiben. Dieser umfangreiche Datensatz ermöglichte es ihnen, zu prüfen, wie gut verschiedene statistische Modelle Spektren in Merkmalschätzungen umwandeln können.
Maschinen beibringen, Blätter zu lesen
Das Team konzentrierte sich auf zwei weit verbreitete, relativ einfache Machine‑Learning‑Ansätze: partielle kleinste Quadrate Regression (PLSR) und lineare Support‑Vector‑Regression (SVR). Beide Methoden verdichten die hochdetaillierten Spektren in eine kleinere Anzahl informativer Merkmale, bevor sie mit gemessenen Eigenschaften verknüpft werden. Die Wissenschaftler verglichen sorgfältig Möglichkeiten zur Modellabstimmung, insbesondere wie viele Komponenten PLSR verwenden sollte, und wie Überanpassung vermieden werden kann. Sie untersuchten auch, ob es besser ist, den Modellen einzelne Blattmessungen, Mittelwerte aus einem einzelnen Parzellendurchgang oder Mittelwerte aller Pflanzen derselben Genotypen zu füttern. Ein rigoroses, verschachteltes Kreuzvalidierungs‑Framework — im Wesentlichen wiederholte Trainings‑ und Testzyklen — wurde verwendet, um Leistung und Unsicherheit zu prüfen.
Welche Merkmale am leichtesten vorherzusagen sind
Einige Blattmerkmale erwiesen sich als deutlich besser „lesbar“ aus den Lichtspektren als andere. Strukturelle und biochemische Merkmale wie spezifische Blattfläche und Stickstoffgehalt wurden mit hoher Genauigkeit vorhergesagt, insbesondere wenn die Daten auf Genotyp‑Ebene gemittelt wurden, um Messrauschen zu reduzieren. Bestimmte photosynthetische Kapazitätsmerkmale und einige Chlorophyll‑Fluoreszenzindikatoren dafür, wie Photosystem II im Licht reagiert, zeigten ebenfalls moderate Vorhersagbarkeit. Dagegen wurden Merkmale, die mit schnellen, kurzlebigen Prozessen verbunden sind – etwa die Geschwindigkeit, mit der Blätter schützende Energiedissipation hoch‑ oder runtergefahren – nur schlecht erfasst. Für diese ist das spektrale Signal entweder schwach oder wird leicht von umweltbedingter Variation zum Messzeitpunkt überdeckt.
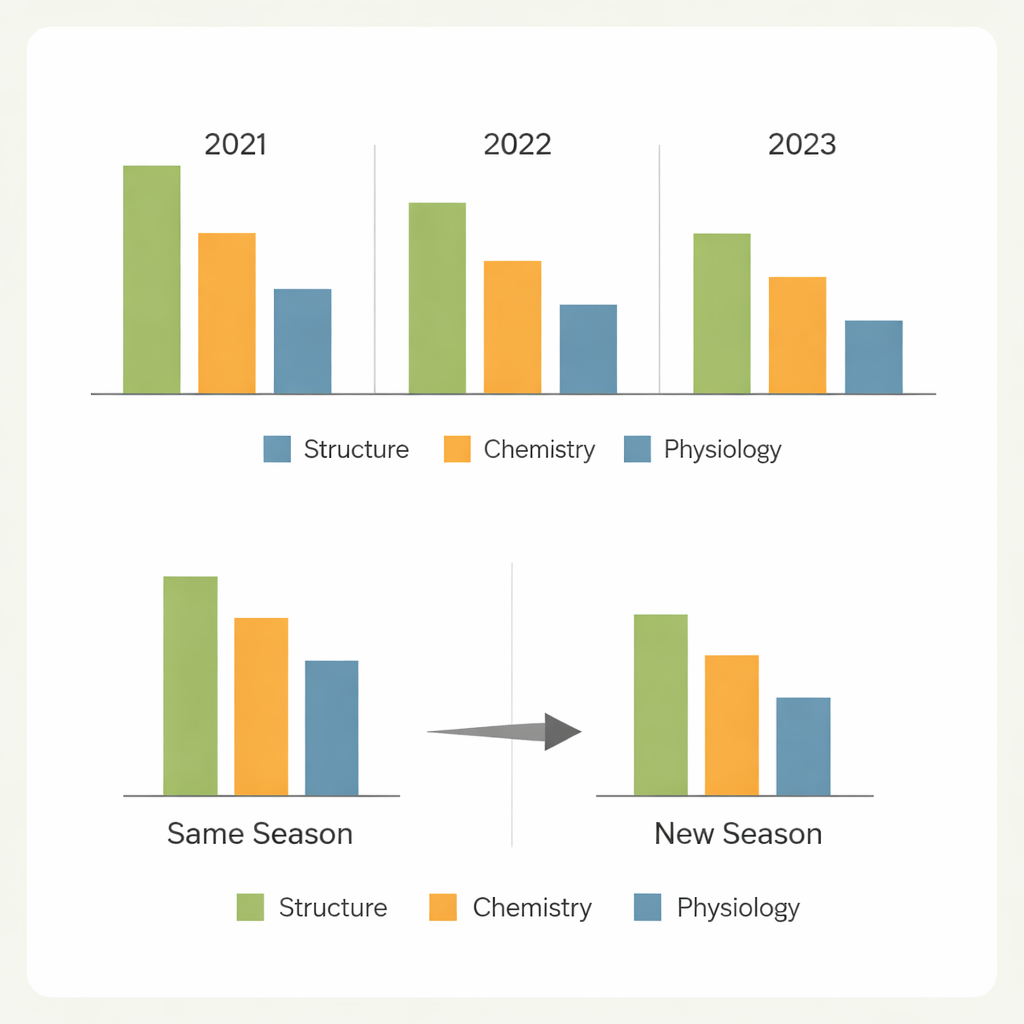
Von einer Saison zur nächsten
Eine zentrale Frage für die praktische Züchtung ist, ob ein in einem Bedingungsset trainiertes Modell in einem anderen vertrauenswürdig ist. Wenn die Modelle zufällige Pflanzen innerhalb derselben Saison vorhersagten, war die Leistung für die leichteren Merkmale allgemein stark. Die Vorhersage völlig neuer Genotypen, die in derselben Saison angebaut wurden, führte nur zu moderaten Einbußen bei strukturellen und stickstoffbezogenen Merkmalen, aber deutlich stärkeren Rückgängen bei Gaswechsel‑Eigenschaften. Die härteste Prüfung — neue Genotypen in einem anderen Jahr vorherzusagen — zeigte große Genauigkeitsverluste, insbesondere für Merkmale, die stark von der Umwelt geprägt werden. Unterschiede im Wetter, in Feldbedingungen und in der Zusammensetzung der Genotypen veränderten die Spektralmuster genug, um die Übertragbarkeit einzuschränken, wobei eine Saison sich als besonders schwierig herausstellte, aus den anderen vorhergesagt zu werden.
Was das für Züchtung und Fernerkundung bedeutet
Für Züchter und Pflanzenwissenschaftler bietet die Studie sowohl Anlass zur Ermutigung als auch zur Vorsicht. Hyperspektrales Scannen in Kombination mit relativ einfachen Machine‑Learning‑Methoden ist bereits ein leistungsfähiges Werkzeug zur hochdurchsatzfähigen Schätzung stabiler, integrativer Merkmale wie Blattstruktur und Stickstoffstatus und kann für diese Zielgrößen über Genotypen und Jahre hinweg einigermaßen generalisieren. Dieselbe Vorgehensweise ist jedoch weitaus weniger zuverlässig für schnelle, umweltabhängige physiologische Merkmale, wenn Modelle außerhalb der Bedingungen angewendet werden, auf denen sie trainiert wurden. Die Autorinnen und Autoren schließen daraus, dass hyperspektrale Methoden bereit sind, groß angelegte Screenings einiger Schlüsselmerkmale bei Mais zu unterstützen, dass aber die Vorhersage dynamischer physiologischer Reaktionen über Umgebungen hinweg reichhaltigere Trainingsdaten, fortgeschrittenere Modellierung und möglicherweise zusätzliche Messungen erfordern wird.
Zitation: Xu, R., Ferguson, J., Breil-Aubert, M. et al. Generalizability and transferability of machine learning models using hyperspectral reflectance data for maize traits. Sci Rep 16, 5865 (2026). https://doi.org/10.1038/s41598-026-36819-1
Schlüsselwörter: hyperspektrale Reflexion, Mais, Machine Learning, Pflanzenphänotypisierung, Photosynthese