Clear Sky Science · de
Taxonomische Modellierung und Klassifikation bei der Fehlermeldung von Raumfahrt-Hardware
Muster finden bei Raumflugstörungen
Jede Mission ins All ist darauf angewiesen, dass unzählige Hardwareteile einwandfrei funktionieren — von Schrauben und Kabeln bis zu Lebenserhaltungssystemen. Wenn etwas schiefgeht, erstellen Ingenieurinnen und Ingenieure detaillierte Abweichungsberichte, doch bei NASA gibt es inzwischen mehr als 54.000 dieser Aufzeichnungen — viel zu viele, als dass Menschen sie einzeln lesen könnten. Diese Studie zeigt, wie moderne Sprach- und Machine-Learning-Werkzeuge dieses Textgebirge in organisiertes Wissen verwandeln können, sodass Ingenieurteams Muster von Ausfällen erkennen, Designs verbessern und Astronautinnen und Astronauten besser schützen können.
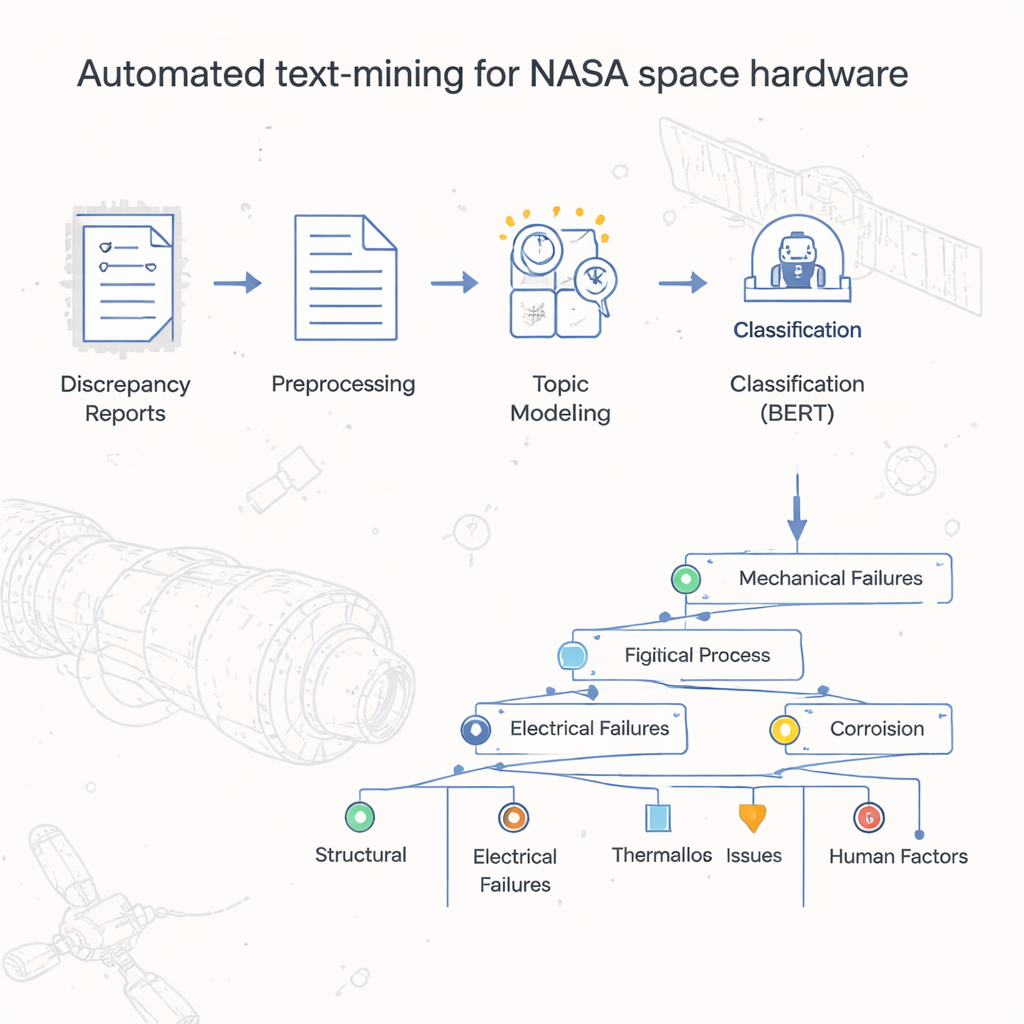
Von Aktenbergen zu organisiertem Erkenntnisgewinn
Jahrzehntelang hat das Johnson Space Center der NASA Berichte über Hardwareausfälle und Abweichungen als digitale Dokumente gespeichert, ähnlich gescannten Versionen alter Papierformulare. Einfache Tabellenauswertungen zeigten, welche offiziellen Fehlercodes am häufigsten vorkamen, doch die eigentliche Geschichte — die konkreten Ursachen, Schritte und Bedingungen, die zu Problemen führten — war in den Freitextfeldern vergraben. Mehr als 54.000 Datensätze manuell zu lesen und zu klassifizieren wäre zeitlich unzumutbar. Die Autorinnen und Autoren entwickelten daher ein automatisiertes Verfahren, um diese Berichte zu klassifizieren und zu gruppieren und so eine Art "Karte" oder Taxonomie zu erstellen, die abbildet, wie Raumfahrthardware im Alltag tatsächlich versagt.
Computern das Lesen technischer Sprache beibringen
Das Team bereinigte zunächst die Texte in jedem Bericht, damit Computer effektiv damit arbeiten konnten. Sie entfernten störende Symbole und Ziffern, die Rauschen erzeugten, zerlegten Sätze in einzelne Wörter und wandten Lemmatisierung an (beispielsweise wurden „leaked“ und „leaking“ zu „leak“). Häufige Wörter mit wenig Aussagekraft wie „the“ oder „and“ wurden herausgefiltert. Nachdem der Text standardisiert war, wandelten die Forschenden ihn in Zahlen um, mit Techniken, die erfassen, wie oft Wörter auftreten und wie stark sie ein Dokument charakterisieren. Diese Grundlage erlaubte es, leistungsfähige Werkzeuge, die ursprünglich für allgemeine Sprachaufgaben entwickelt wurden, auf die stark spezialisierte Welt der Raumfahrthardware-Berichte anzuwenden.
Ein Baum von Fehlerarten
Im Kern des Projekts steht ein zweistufiges Modell, das die Autorinnen und Autoren LDA-BERT nennen. Im ersten Schritt, Latent Dirichlet Allocation (LDA), werden automatisch Themen — sogenannte Topics — entdeckt, indem nach Wortmustern gesucht wird, die in Tausenden von Berichten häufig gemeinsam auftreten. Ein einzelner Bericht kann mehrere Topics enthalten, was die Realität widerspiegelt, in der ein Hardwareproblem mehrere beitragende Ursachen haben kann. Der zweite Schritt nutzt BERT, ein modernes Sprachmodell, um zu prüfen und zu verfeinern, wie gut diese Topics die Berichte trennen. Indem die LDA-Topics als vorläufige Labels behandelt und BERT darauf trainiert wurde, sie vorherzusagen, konnten die Forschenden die Anzahl und Kombination von Topics identifizieren, die stabile, genaue Klassifikationen liefern. Anschließend teilten sie jedes Topic weiter in Subtopics auf, mithilfe von Clustering und statistischen Prüfungen, um eine verzweigende Taxonomie zu konstruieren, die Fehlermeldungen von allgemeinen Fehlercodes bis hin zu detaillierten prozessbezogenen Labels organisiert.
Taxonomien in nutzbare Trends verwandeln
Sobald die Taxonomie stand, visualisierte das Team sie mit Dashboards und interaktiven Werkzeugen. Jeder Ast und Unterast des Baums konnte mit anderen Informationen aus den Berichten verknüpft werden: wann ein Problem erstmals aufgezeichnet wurde, wie lange es dauerte, bis es geschlossen war, welche Organisation verantwortlich war und welche abschließende Entscheidung getroffen wurde. Zeitreihenplots zeigten, ob bestimmte Problemtypen — etwa Inspektionsfehler oder Toleranzdatenprobleme — im Laufe der Jahre häufiger oder seltener wurden. Wortkarten gaben einen schnellen Eindruck der in jedem Cluster verwendeten Sprache, ohne jeden Bericht lesen zu müssen. Diese Ansichten helfen den Verantwortlichen, sich auf prozessuale Fehler mit hoher Trend- und Auswirkungsstärke zu konzentrieren und gezielte Schulungen, Verfahrensänderungen oder Designanpassungen dort vorzunehmen, wo sie am meisten bewirken.
Grenzen automatischer Ursachenforschung
Die Forschenden untersuchten auch Werkzeuge, die über bloße Kennzeichnung und Trendermittlung hinausgehen und versuchen, direkte Ursache-Wirkungs-Beziehungen aus Texten abzuleiten. Sie testeten Systeme wie INDRA-Eidos und maßgeschneiderte Regelwerke, die mit der spaCy-Sprachbibliothek erstellt wurden. Zwar konnten diese Werkzeuge einige Ursache-Wirkungs-Paare extrahieren und als interaktive Netzwerke visualisieren, viele der vorgeschlagenen Verbindungen waren jedoch zu vage oder verwirrend, um nützlich zu sein. In der Praxis hatten die Modelle Schwierigkeiten, weil die Originalberichte oft keine eindeutigen Ursachen darlegten; Ingenieurinnen und Ingenieure deuteten diese an oder verschoben sie in spätere Untersuchungen. Die Studie kommt zu dem Schluss, dass eine verlässliche Automatisierung der Ursachenfindung sowohl eine reichhaltigere Datenerfassung — etwa explizite Felder für wahrscheinliche Ursachen — als auch teurere, stark angepasste Modelltrainings erfordern würde, die für diese einmalige Analyse nicht gerechtfertigt sind.
Warum das für künftige Missionen wichtig ist
Indem ein großes, unstrukturiertes Archiv von Fehlermeldungen in eine klare, geschichtete Taxonomie überführt wurde, bietet diese Arbeit der NASA ein praktisches Mittel, nachzuvollziehen, wie und warum Hardwareprobleme im Zeitverlauf auftreten. Auch wenn die Methoden menschliches Urteilsvermögen bei tiefgehender Ursachenanalyse noch nicht ersetzen können, sind sie hervorragend darin, große Textmengen zu scannen, um aufzuzeigen, wo Probleme gehäuft auftreten und welche Prozessarten typischerweise beteiligt sind. Solche Frühwarnungen und strukturierten Einsichten helfen Engineering-Teams, ihre Aufmerksamkeit zu fokussieren, Verfahren zu verfeinern und robustere Systeme zu entwerfen — konkrete Schritte zu sichereren, zuverlässigeren Missionen zum Mond, Mars und darüber hinaus.
Zitation: Palacios, D., Hill, T.R. Taxonomical modeling and classification in space hardware failure reporting. Sci Rep 16, 5868 (2026). https://doi.org/10.1038/s41598-026-36813-7
Schlüsselwörter: Ausfälle von Raumfahrt-Hardware, Verarbeitung natürlicher Sprache, Themenmodellierung, ingenieurtechnische Risikoanalyse, NASA-Abweichungsberichte