Clear Sky Science · de
Überprüfung der Authentizität urdusprachiger Nachrichten mithilfe von Deep Learning mit verketteten BERT- und GloVe-Einbettungen
Warum das Erkennen von Falschnachrichten in Urdu wichtig ist
In Pakistan und weltweit beziehen inzwischen mehr Menschen ihre Nachrichten von Websites und aus sozialen Medien als aus Zeitungen oder dem Fernsehen. Dieser Wandel hat es falschen Geschichten leichter denn je gemacht, sich schnell zu verbreiten — besonders in Landessprachen wie Urdu, in denen digitale Werkzeuge begrenzt sind. Diese Studie behandelt eine einfache, aber drängende Frage: Kann moderne künstliche Intelligenz automatisch echte urdusprachige Nachrichten von gefälschten unterscheiden und so normalen Leserinnen und Lesern, Journalistinnen und Journalisten sowie Plattformen helfen, sich gegen irreführende Informationen zu wappnen?
Die wachsende Herausforderung durch Fehlinformationen online
Die Autorinnen und Autoren beginnen damit, darzulegen, wie erfundene Schlagzeilen und verzerrte Berichte die öffentliche Meinung formen, politische Spannungen anheizen und sogar Gesundheit und finanzielle Lage von Menschen schädigen können. Während viele Faktenprüf-Websites und Forschungsprojekte sich auf Englisch konzentrieren, werden regionale Sprachen wie Urdu oft vernachlässigt. Bestehende Urdu-Ressourcen umfassen nur einige tausend Nachrichtenartikel, viele davon aus dem Englischen übersetzt und auf enge Themen wie Politik beschränkt. Das erschwert es, zuverlässige Computersysteme zu trainieren, die verdächtige Inhalte in der Sprache erkennen, die die meisten Pakistanerinnen und Pakistaner tatsächlich lesen.
Aufbau einer großen Sammlung urdusprachiger Nachrichten
Um diese Lücke zu schließen, stellten die Forschenden das ihrer Beschreibung nach umfangreichste Urdu-Falschnachrichten-Datenset zusammen, das bisher vorliegt: 14.178 Artikel, gesammelt zwischen 2017 und 2023 von angesehenen pakistanischen Nachrichtenseiten und Online-Plattformen. Die Beiträge decken fünfzehn Lebensbereiche ab, darunter Politik, Gesundheit, Bildung, Wirtschaft, Kriminalität, Sport und Umwelt. Mithilfe von Faktenprüfquellen wie PolitiFact, FactCheck und spezialisierten News-APIs wurde jeder Artikel als echt oder gefälscht etikettiert; teilweise wahre Beiträge wurden mit echten Nachrichten zusammengefasst, um nuanciertere Berichterstattung zu berücksichtigen. Das Team bereinigte den Text, indem Duplikate, Webadressen und überflüssige Satzzeichen entfernt, Sätze in Wörter zerlegt und sehr häufige Füllwörter herausgefiltert wurden.
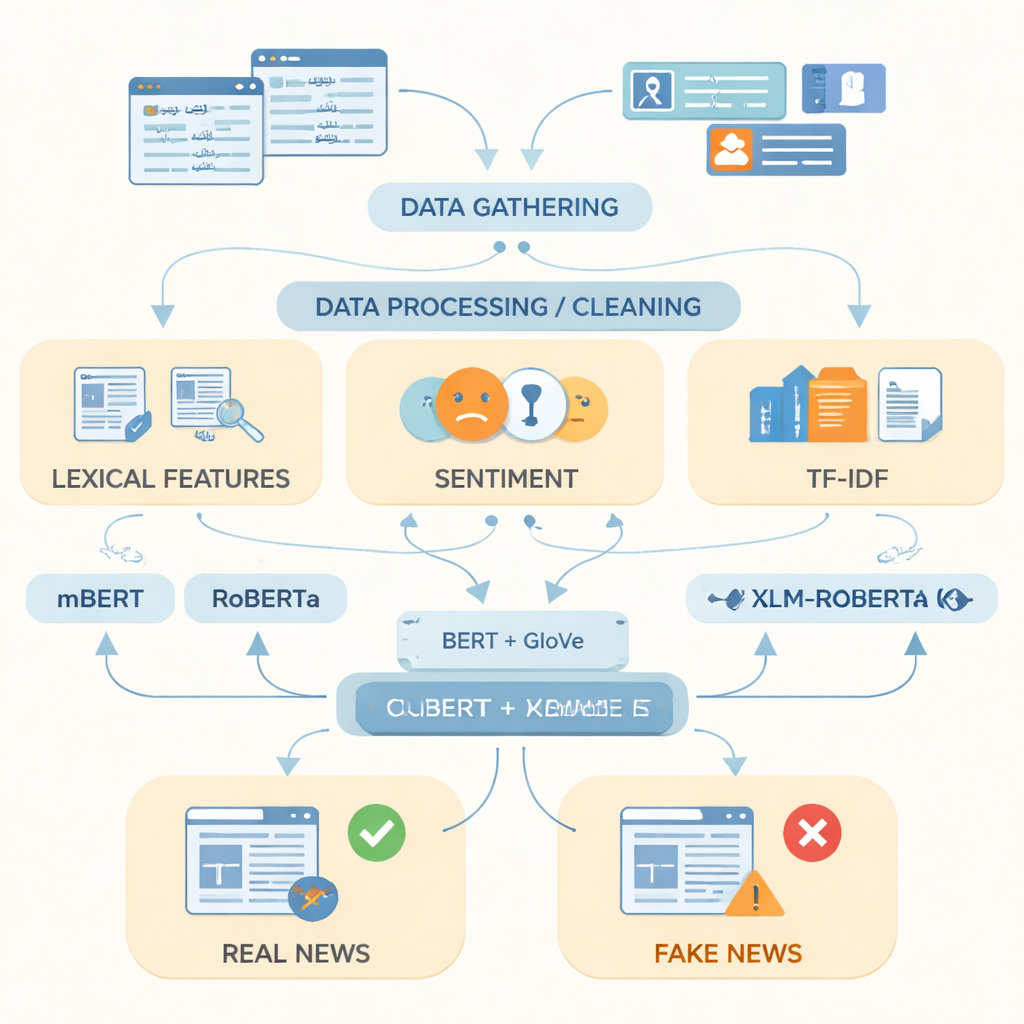
Computern beibringen, wie Falschnachrichten aussehen
Nach der Datenvorbereitung richteten die Autorinnen und Autoren ihren Fokus darauf, wie man Urdu-Text am besten für einen Computer darstellt. Sie kombinierten einfache Indikatoren wie häufig verwendete Wörter, die emotionale Tonalität der Sprache und Termfrequenz-Werte mit zwei leistungsfähigen Wortrepräsentationstechniken. Die eine, GloVe genannt, behandelt jedes Wort als festen numerischen Vektor, basierend darauf, wie oft es zusammen mit anderen Wörtern im gesamten Korpus vorkommt. Die andere, auf BERT-ähnlichen Modellen basierend, betrachtet jedes Wort im Satzkontext und weist ihm eine kontextabhängige Bedeutung zu. Durch das Zusammenführen dieser beiden Sprachansichten zu einer einzigen, reicheren Repräsentation kann das System sowohl Gesamtmuster als auch subtile Wortwahländerungen erfassen, die oft echte von gefälschten Geschichten unterscheiden.
Erprobung fortgeschrittener Sprachmodelle
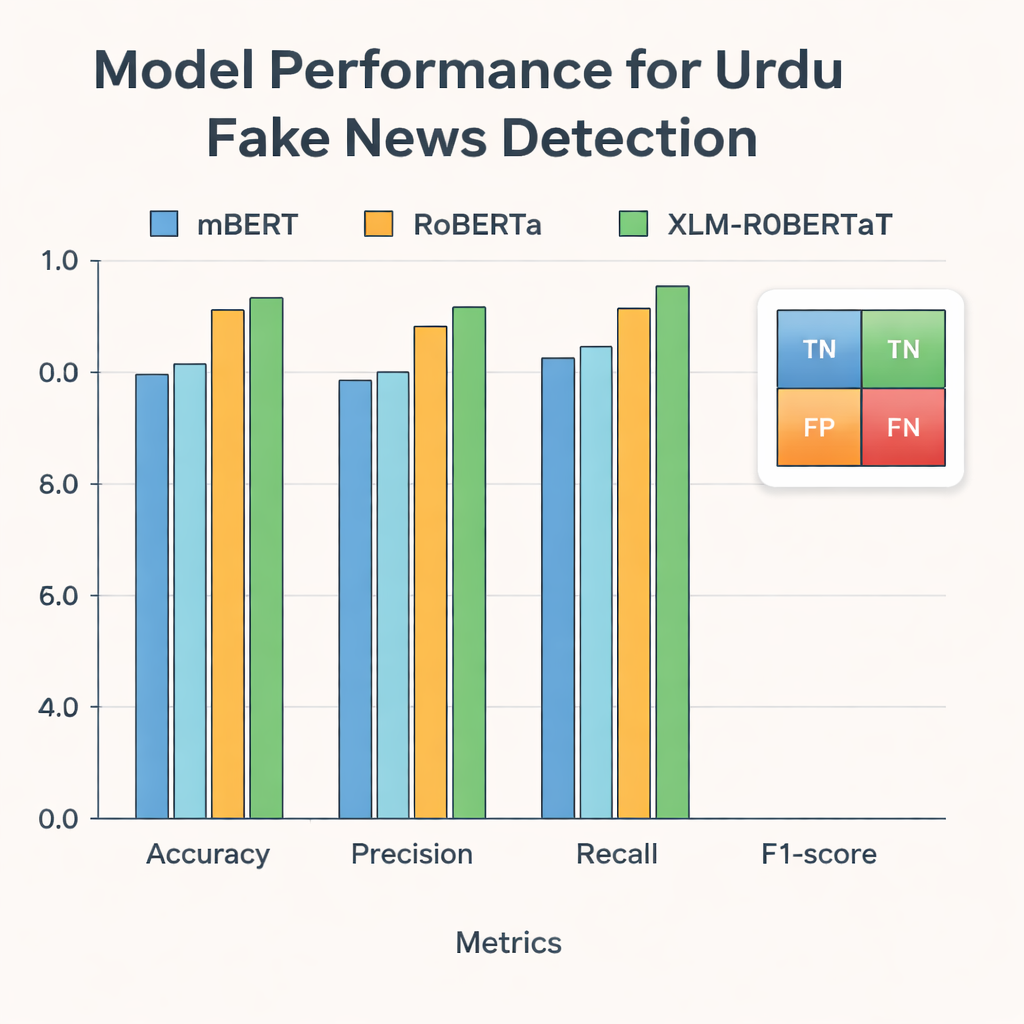
Die Forschenden fütterten diese Repräsentationen anschließend in drei moderne Deep-Learning-Modelle, die auf Texten vieler Sprachen trainiert sind: mBERT, RoBERTa und XLM-RoBERTa. Alle drei wurden auf dem Urdu-Datensatz feinabgestimmt, um vorherzusagen, ob ein Artikel echt oder gefälscht ist. Ihre Leistung wurde mit standardisierten Kennzahlen bewertet: Genauigkeit (wie oft sie richtig lagen), Präzision (wie oft als falsch gekennzeichnete Artikel tatsächlich falsch waren), Recall (wie viele der gesamten Falschnachrichten sie erfassten) und F1-Score, der Präzision und Recall ausbalanciert. Während alle Modelle starke Ergebnisse zeigten, lag XLM-RoBERTa in Kombination mit der verschmolzenen BERT- und GloVe-Repräsentation vorn: Es klassifizierte etwa 96 Prozent der Testartikel korrekt und erreichte einen F1-Score von 0,956 — besser als frühere urdusprachige Falschnachrichten-Systeme, die mit kleineren Datensätzen oder einfacheren Methoden arbeiteten.
Was das für Alltagsleserinnen und -leser bedeutet
Für Nicht-Fachleute ist die Botschaft klar: Mit ausreichend hochwertigen urdusprachigen Nachrichten und der richtigen Art von KI ist es heute möglich, Werkzeuge zu entwickeln, die wahrscheinlich gefälschte Geschichten automatisch und mit hoher Zuverlässigkeit kennzeichnen. Die Studie zeigt, dass reichere Sprachrepräsentationen und multilinguale Modelle Computern ein deutlich besseres Verständnis dafür geben, wie Urdu in verschiedenen Regionen und Themen tatsächlich geschrieben wird. Obwohl die aktuelle Arbeit sich auf Text beschränkt und noch keine Bilder oder Nutzerverhalten in sozialen Medien analysiert, legt sie eine solide Grundlage für zukünftige Systeme, die über Sprachen und Medientypen hinweg arbeiten könnten. Praktisch gesehen bringt diese Forschung Pakistan einen Schritt näher an Browser-Plugins, Redaktions-Dashboards oder Social-Media-Filter, die Menschen helfen, Fakt von Fiktion in der Sprache zu trennen, die sie täglich benutzen.
Zitation: Feroz, A., Abbasi, W., Babar, M.Z. et al. Verifying Urdu news authenticity using deep learning with concatenated BERT and GloVe embedding. Sci Rep 16, 7352 (2026). https://doi.org/10.1038/s41598-026-36771-0
Schlüsselwörter: Erkennung von Falschnachrichten, Urdu-Sprache, Deep Learning, BERT und GloVe, Fehlinformationen im Netz