Clear Sky Science · de
Verbesserung der Langstrecken-Tiefenschätzung durch heterogene CNN-Transformer-Codierung und bereichsübergreifende semantische Fusion
Tiefe mit nur einem Auge sehen
Moderne Roboter, selbstfahrende Autos und Drohnen verlassen sich oft auf teure 3D-Sensoren, um Entfernungen zu erfassen. Diese Studie zeigt, wie gewöhnliche Farbkameras, wie sie in Smartphones stecken, deutlich leistungsfähiger genutzt werden können: Die Autorinnen und Autoren entwerfen eine neue Methode, mit der ein Computer aus nur einem Bild Tiefe schätzt, und richten den Fokus auf den schwierigsten Teil der Szene – die große Distanz, in der Hindernisse winzig, verschwommen und leicht falsch einzuschätzen sind.
Warum ferne Objekte so schwer zu beurteilen sind
Tiefe aus einem einzelnen Bild, die sogenannte monokulare Tiefenschätzung, ist eine Art visueller Trick. Nahe Objekte bedecken viele Pixel und weisen scharfe Texturen auf, sodass heutige neuronale Netze in kurzen und mittleren Entfernungen bereits gute Ergebnisse liefern. Weiter entfernt schrumpfen Fahrzeuge jedoch auf wenige Pixel und Fahrbahnmarkierungen verschwimmen im Dunst. Standard-Convolutional-Neural-Networks erfassen feine lokale Details gut, tun sich aber schwer damit, das große Ganze einer gesamten Straße zu erfassen. Neuere Transformer-Modelle erfassen den globalen Kontext gut, sind jedoch weniger empfindlich gegenüber winzigen Kanten und Texturen. Infolgedessen stolpern beide Modellfamilien oft genau dort, wo für sichere Navigation verlässliche Schätzungen am dringendsten gebraucht werden: in großer Entfernung.
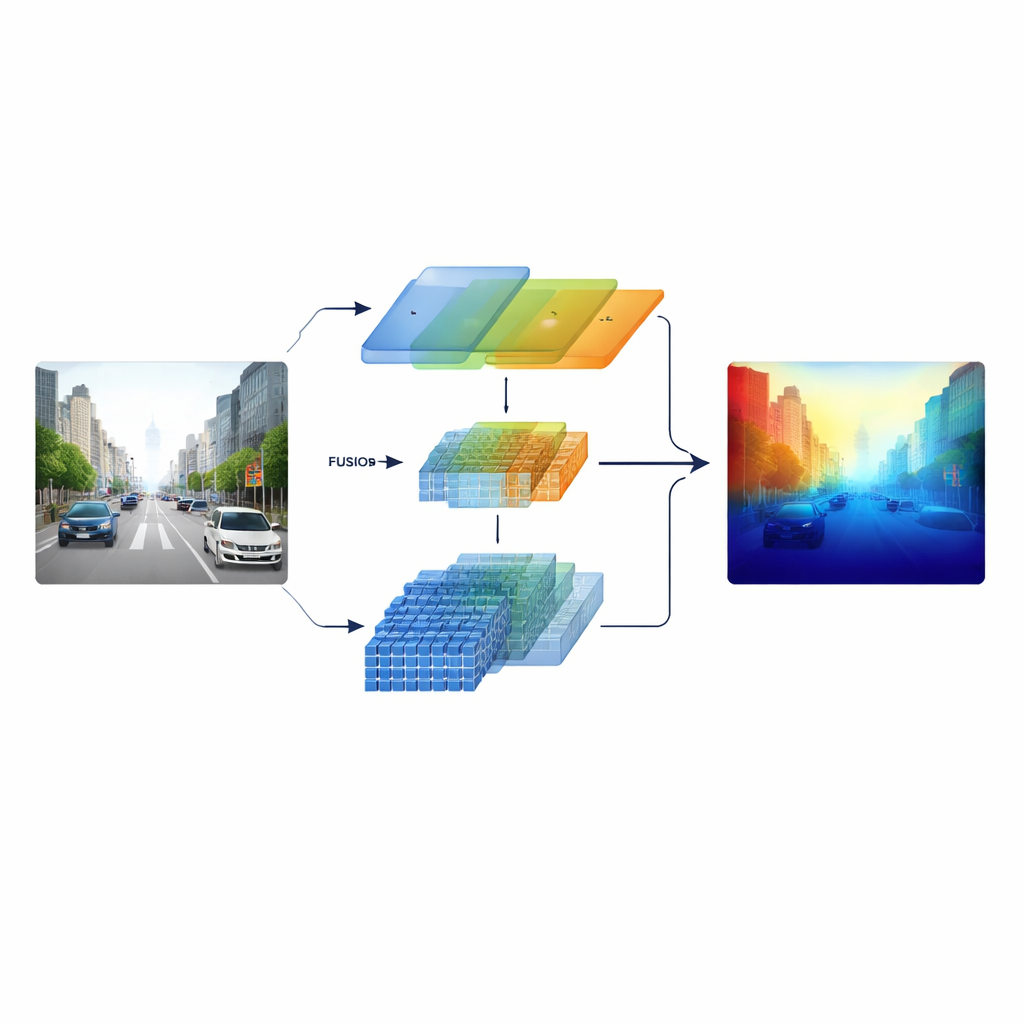
Zwei Sichtweisen verschmelzen
Die Forschenden begegnen diesem Problem, indem sie einen „heterogenen“ Encoder bauen, der zwei verschiedene Arten visueller Verarbeitung parallel laufen lässt. Ein Zweig basiert auf einem klassischen ResNet-ähnlichen Convolutional-Netz, das auf prägnante lokale Muster wie Fahrbahnmarkierungen, Pfosten und Objektkanten spezialisiert ist. Der andere Zweig verwendet einen Swin Transformer, der dafür entwickelt wurde, langreichweitige Zusammenhänge im Bild zu erfassen, etwa die Gliederung eines Straßenkorridors oder die Skyline ferner Gebäude. Anstatt diese beiden Sichtweisen erst am Ende zu kombinieren, bewahrt das System multiskalige Merkmale beider Zweige und führt sie in einer sorgfältig gestalteten Fusionsstufe zusammen, sodass feine Strukturen und breiter Kontext sich über die gesamte Verarbeitung hinweg gegenseitig informieren.
Kanäle, Raum und Skala überbrücken
Im Zentrum des Modells steht ein Cross-dimensional Semantic Fusion-Modul, das wie ein intelligenter Besprechungsraum für die beiden Informationsströme wirkt. Zunächst entscheidet es, welche Kanäle – verschiedene Typen gelernter visueller Muster – mehr Aufmerksamkeit verdienen und balanciert Signale aus detailreichen Texturen und hochrangigen szenischen Hinweisen aus. Danach betrachtet es separat horizontale und vertikale Richtungen, die in Szenen mit Straßen, Gebäuden und Bäumen besonders aussagekräftig sind, um wichtige Strukturen hervorzuheben, die sich über das Bild erstrecken. Schließlich mischt es flache, detailreiche Merkmale mit tieferen, abstrakteren über mehrere Skalen hinweg. Ein lernbarer Gewichtungsschritt ermöglicht dem Netzwerk zu entscheiden, wie sehr jedem Zweig in jeder Region vertraut wird, sodass kleine, ferne Objekte nicht von nahen Szenen überdeckt werden.
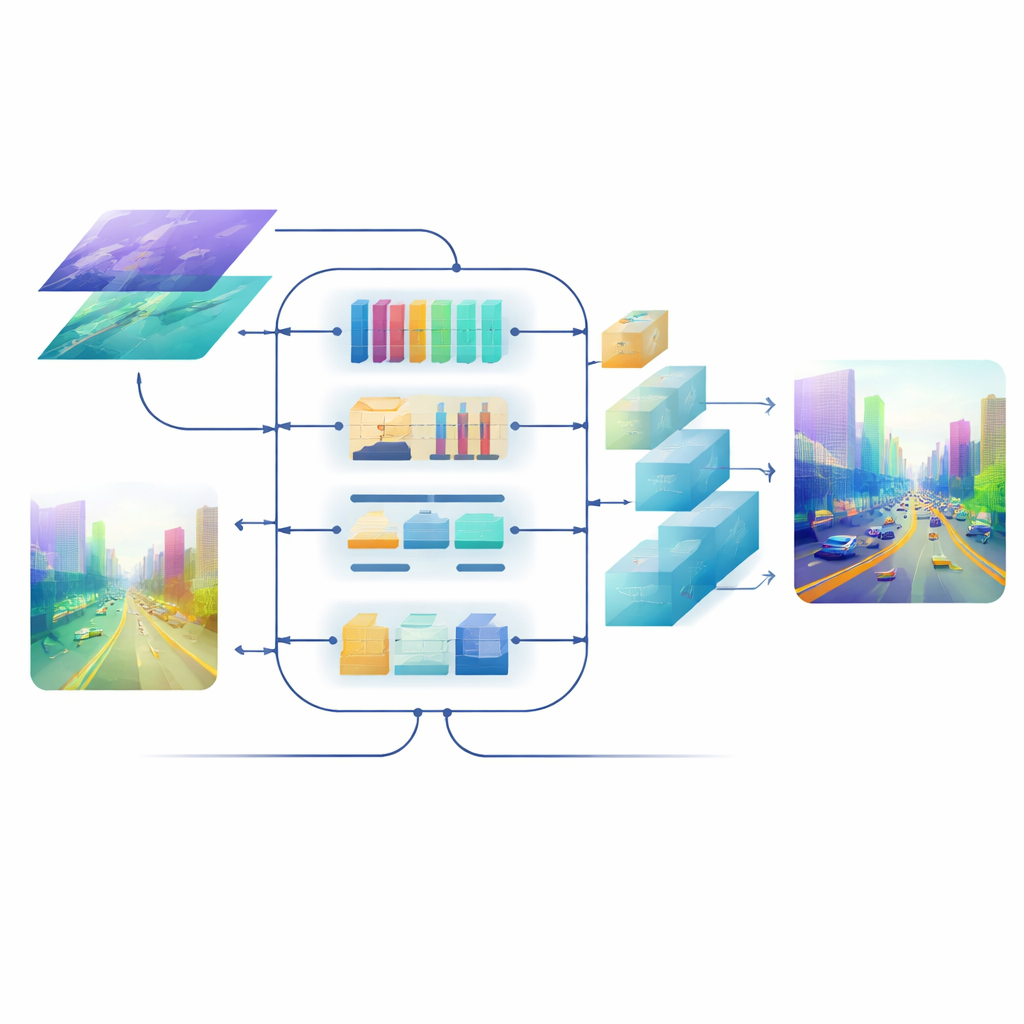
Das finale Bild schärfen
Selbst mit gut fusionierten Merkmalen kann die Rückwandlung in eine voll aufgelöste Tiefenkarte Kanten verwischen und dünne Strukturen auswaschen. Um das zu verhindern, entwirft das Team einen auf Aufmerksamkeit basierenden Decoder. Seine Upsampling-Blöcke nutzen leichte, depth-wise Faltungen, um die Karte zu vergrößern, ohne Kontext zu verlieren, und ein multiskaliges Self-Attention-Mechanismus gruppiert Feature-Kanäle, sodass Aufmerksamkeit effizient berechnet werden kann. Dieser Schritt verfeinert Tiefenvorhersagen auf jeder Skala und hält zugleich den Rechenaufwand im Rahmen. Das Ergebnis ist ein glattes, kohärentes Tiefenfeld, in dem Objektgrenzen – etwa die Silhouette eines fernen Radfahrers oder die Sprossen eines Etagenbetts – scharf bleiben.
Wie gut es in der Praxis funktioniert
Die Methode wurde auf mehreren Standard-Datensätzen getestet. Auf KITTI, einer großen Sammlung von Fahrszenen, erreicht das Modell auf den meisten gebräuchlichen Metriken den Stand der Technik und erzielt entscheidend die geringsten Fehler in ausgewiesenen Langstreckenregionen. Es liefert außerdem sauberere Tiefengrenzen um Objekte als konkurrierende Systeme. Auf NYU Depth V2, das Innenraumszenen enthält, und auf dem SUN RGB-D-Benchmark generalisiert dasselbe Modell erfolgreich und rekonstruiert Möbel und Raumlayouts in überzeugenden 3D-Punktwolken. Ablationsstudien – systematische Tests, die Komponenten entfernen oder austauschen – zeigen, dass jedes vorgeschlagene Bauteil, vom hybriden Encoder über das Fusionsmodul bis hin zum Attention-Block des Decoders, die Leistung spürbar verbessert, insbesondere in entfernten, texturarmeren Bereichen.
Was das für Alltagstechnologie bedeutet
Einfach gesagt lehrt diese Arbeit ein neuronales Netzwerk, gleichzeitig eine Lupe und ein Weitwinkelobjektiv zu benutzen und die Informationen klug zu kombinieren. Durch ein besseres Ausbalancieren von lokalen Details und globalem Szenenverständnis verbessert das vorgeschlagene Framework erheblich, wie gut eine einzelne Kamera Entfernungen weit voraus auf der Straße oder quer durch einen Raum einschätzt. Das macht es praktischer, Roboter, Fahrzeuge und Drohnen mit günstigeren Sensoren auszustatten und ihnen dennoch ein reiches 3D-Bild der Welt zu geben – ein wichtiger Schritt hin zu sichereren, leistungsfähigeren und kostengünstigeren autonomen Systemen.
Zitation: Chen, Y., Yin, Q., Zhao, L. et al. Enhancing long-range depth estimation via heterogeneous CNN-transformer encoding and cross-dimensional semantic fusion. Sci Rep 16, 9396 (2026). https://doi.org/10.1038/s41598-026-36755-0
Schlüsselwörter: monokulare Tiefenschätzung, Computer Vision, Fusion von Transformer und CNN, autonomes Fahren, 3D-Szenenrekonstruktion