Clear Sky Science · de
Kernel-Mean-Matching verbessert die Risikoabschätzung bei räumlichen Verteilungsverschiebungen
Warum die Modellrisikoabschätzung bei sich ändernden Karten wichtig ist
Machine-Learning-Modelle werden zunehmend eingesetzt, um vorherzusagen, wo Arten leben werden, wie Tumore im Gewebe organisiert sind oder wie sich Verschmutzung ausbreitet. Die Daten, mit denen diese Modelle trainiert werden, stammen jedoch oft aus sehr spezifischen Orten – dichte Stichproben in der Nähe von Städten, Krankenhäusern oder leicht zugänglichen Feldstellen –, während die Modelle über viel größere, andere Regionen angewendet werden. Diese Diskrepanz zwischen dem Ort, an dem Daten erhoben wurden, und dem Ort, an dem Vorhersagen gemacht werden, kann Modelle sicherer und genauer erscheinen lassen, als sie tatsächlich sind. Die Arbeit „Kernel mean matching enhances risk estimation under spatial distribution shifts“ stellt eine auf den ersten Blick einfache Frage: Wenn die Welt anders aussieht als die Trainingsdaten, wie falsch könnte Ihr Modell liegen, und wie kann man das erkennen?
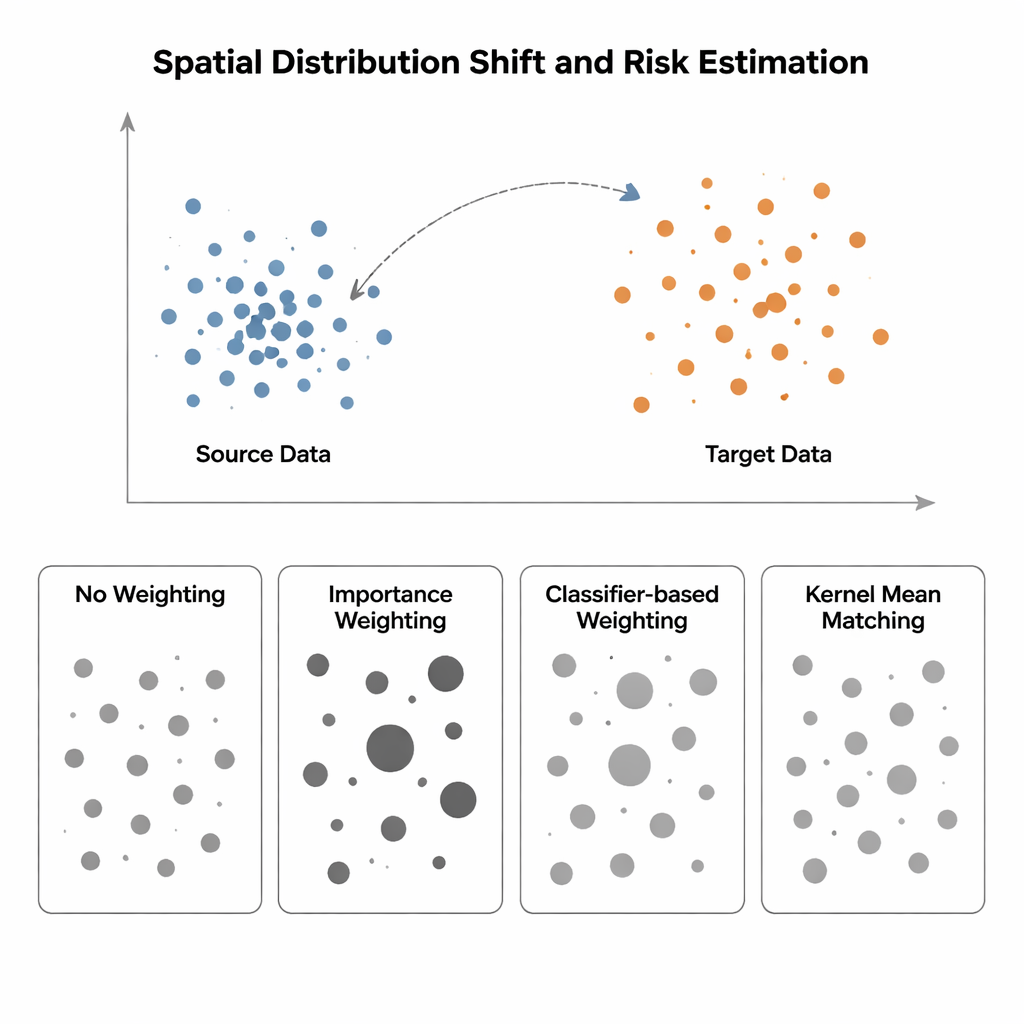
Wenn Training und Test in verschiedenen Welten leben
In der Statistik bezeichnet das "Risiko" eines Modells seinen erwarteten Fehler auf neuen, ungesehenen Daten. Übliche Bewertungsmethoden – wie Kreuzvalidierung oder das Zurückhalten einer zufälligen Testmenge – setzen implizit voraus, dass Trainings- und Testdaten aus derselben Verteilung stammen. Räumliche Daten verletzen diese Annahme. Umweltgradienten, gepoolte Stichproben und sich ändernde Klimata bedeuten, dass die Bedingungen, unter denen ein Modell trainiert wird, deutlich von denen abweichen können, in denen es eingesetzt wird. Beispielsweise sind Artenbeobachtungen oft entlang von Straßen konzentriert, während Schutzmaßnahmen entlegene Gebiete betreffen; Tumorproben können aus einem Bereich des Gewebes stammen, Vorhersagen werden aber anderswo benötigt. In solchen Fällen neigen konventionelle Risikoabschätzungen dazu, zu optimistisch zu sein und zu verschleiern, wie stark ein Modell an neuen Orten versagen könnte.
Alte Werkzeuge haben mit räumlicher Verzerrung Schwierigkeiten
Die Studie vergleicht vier Wege zur Abschätzung des Modellrisikos, wenn sich die Eingangsverteilung von einer "Quell"-Region (wo Labels bekannt sind) zu einer "Ziel"-Region (wo Labels knapp oder fehlend sind) verschiebt. Die einfachste Methode, No Weighting, misst einfach den durchschnittlichen Fehler an verfügbaren Daten und nimmt an, Quelle und Ziel seien ähnlich – eine Annahme, die bei räumlicher Verzerrung nicht mehr hält. Importance Weighting versucht, dies zu korrigieren, indem jede Quellprobe anhand ihrer Häufigkeit im Ziel relativ zur Quelle skaliert wird. Theoretisch stellt das das richtige Risiko wieder her, in der Praxis erfordert es jedoch die Schätzung hochdimensionaler Wahrscheinlichkeitsdichten. Wenn Quelldaten stark konzentriert und Zieldaten stärker verteilt sind – eine typische Situation in der räumlichen Ökologie oder medizinischen Bildgebung – werden diese Dichteschätzungen unzuverlässig, und einige Proben erhalten enorme Gewichte, was die Risikoabschätzung extrem instabil macht. Klassifikator-basierte Ansätze, die einen Klassifikator trainieren, um Quelle und Ziel zu unterscheiden und dessen Wahrscheinlichkeiten in Gewichte umwandeln, vermeiden explizite Dichteschätzung, liefern aber oft fehlkalibrierte Risiken, weil sie die Klassifikationsgenauigkeit optimieren, nicht die Verteilungsangleichung.
Ein anderer Weg: Verteilungen direkt anpassen
Die Autorinnen und Autoren empfehlen Kernel Mean Matching (KMM), einen Ansatz, der die Dichteschätzung ganz umgeht. Anstatt zu versuchen, für jeden Punkt die Wahrscheinlichkeit unter Quell- und Zielverteilung zu berechnen, sucht KMM nach Gewichten für Quellproben, sodass deren durchschnittliche "Signatur" in einem flexiblen, durch einen Kernel definierten Merkmalsraum der der Zielproben entspricht. Intuitiv dehnt oder staucht es den Einfluss jeder Quellprobe so, dass die gewichtete Quellwolke zusammen genommen wie die Zielwolke aussieht. Sind diese Gewichte gefunden, wird das Risiko als gewichteter Mittelwert der Quellfehler geschätzt. Ein ergänzendes Werkzeug, die lokale Korrelationsfunktion, quantifiziert, wie stark die Daten räumlich gebündelt sind; sie dient als Diagnose, um zu erkennen, wann Verteilungsverschiebungen stark genug sind, dass ein Reweighting voraussichtlich hilft.
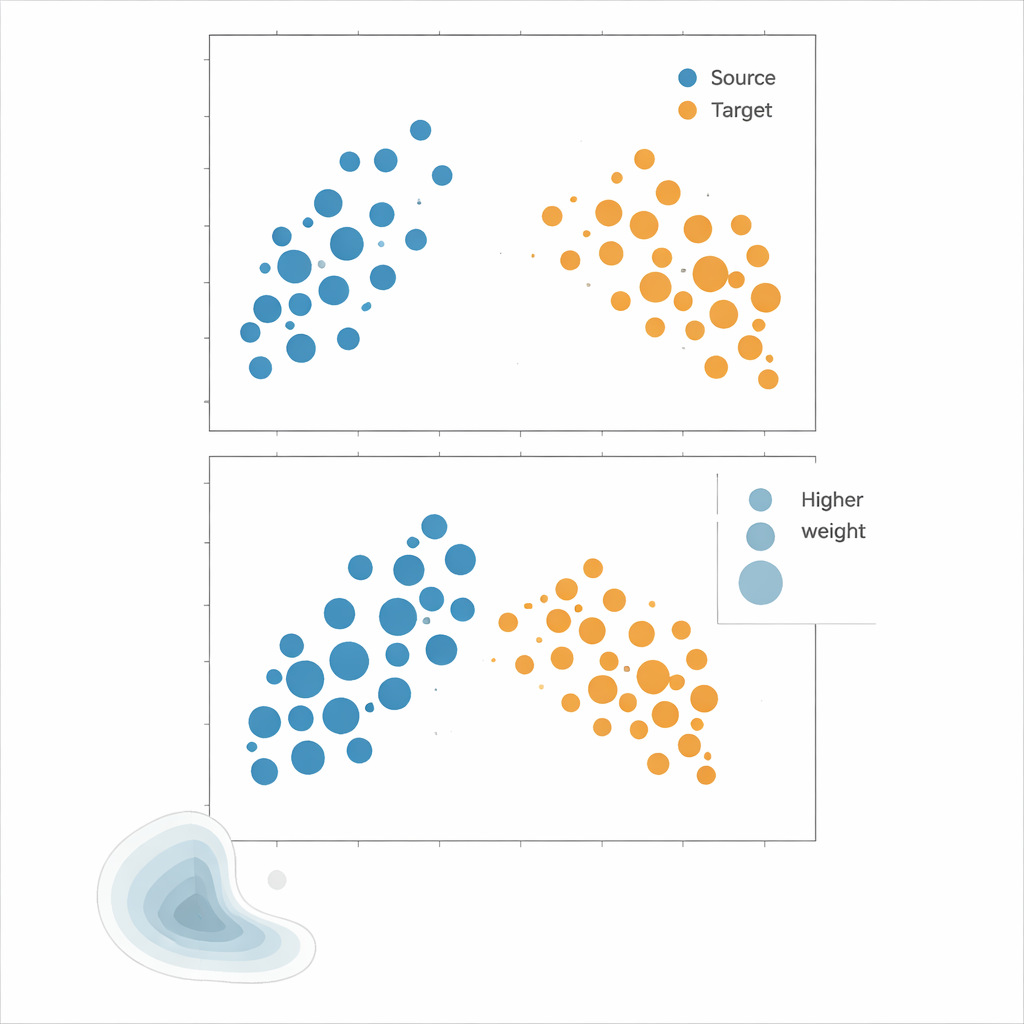
Erprobung der Methoden
Um herauszufinden, welche Strategie am besten funktioniert, führen die Autorinnen und Autoren umfangreiche Experimente mit synthetischen und realen Daten durch. Die synthetischen "Landschaften" bestehen aus Mischungen von Gaußschen Clustern, deren Ausdehnung, Form und Domänenabdeckung exakt gesteuert werden können, was strukturierte Tests wie das Bescheiden eines Teils der Domäne, das Ändern von Korrelationsmustern zwischen Merkmalen oder das Umschalten zwischen stark gebündelten und nahezu gleichmäßig verteilten Punktmustern erlaubt. Zu den realen Datensätzen gehören nordische Pflanzenartenbeobachtungen, beschrieben durch Klima und Standort, sowie räumliche Anordnungen von Immunzellen in Tumoren. In all diesen Szenarien werden Modelle auf gebündelten Quelldaten trainiert und auf weniger gebündelten Zieldaten bewertet, was typische Stichprobenverzerrungen nachbildet. Die Leistung wird mit mehreren Fehlermetriken beurteilt, wobei der Fokus darauf liegt, wie genau die geschätzten Risiken jeder Methode den wahren Fehler im Ziel verfolgen.
Zuverlässigere Risikoabschätzung in unordentlichen, hochdimensionalen Räumen
In nahezu allen synthetischen Setups und realen Datensätzen liefert KMM die genauesten und stabilsten Risikoabschätzungen. Es reduziert den mittleren absoluten prozentualen Fehler um etwa 12 bis 87 Prozent gegenüber den Alternativen und vermeidet entscheidend die "Gewichtsexplosion", die Importance Weighting in hohen Dimensionen plagt. In herausfordernden Tumorlayouts können Beispielswiese Importance-Weighting-Fehler mehreren tausend Prozent erreichen, während KMM in handhabbaren Grenzen bleibt. Klassifikatorbasiertes Reweighting verbessert typischerweise gegenüber naiven Methoden, hinkt aber KMM hinterher, was seine Orientierung an Diskriminierung statt an treuem Verteilungsabgleich widerspiegelt. Diese Ergebnisse legen nahe, dass KMM für räumliche Anwendungen – bei denen Daten gebündelt, verzerrt und hochdimensional sind – einen prinzipiellen Weg bietet, einzuschätzen, wie viel Vertrauen man in die Vorhersagen eines Modells setzen kann.
Was das für Entscheidungen in der Praxis bedeutet
Für Nicht-Spezialisten, die Machine Learning in Ökologie, Umweltwissenschaften oder Biomedizin einsetzen, ist die Botschaft klar: Standard-Testwerte können gefährlich irreführend sein, wenn sich Ihre Einsatzregion von der Region unterscheidet, aus der Ihre Daten stammen. Kernel Mean Matching bietet eine Möglichkeit, dies zu korrigieren, indem der Einfluss der Trainingsproben so neu gewichtet wird, dass sie statistisch den Orten oder Geweben ähneln, die für Sie relevant sind. Die Studie zeigt, dass dieser Ansatz konsistent ehrlichere Schätzungen des Modellfehlers liefert, selbst bei starker räumlicher Verzerrung und vielen Eingangsvariablen. In der Praxis bedeutet das verlässlichere Entscheidungsgrundlagen bei der Wahl zwischen Modellen und ein klareres Bild davon, wo Vorhersagen vertrauenswürdig sind und wo Vorsicht geboten ist.
Zitation: Serov, E., Koldasbayeva, D. & Zaytsev, A. Kernel mean matching enhances risk estimation under spatial distribution shifts. Sci Rep 16, 6921 (2026). https://doi.org/10.1038/s41598-026-36740-7
Schlüsselwörter: Verteilungsverschiebung, räumliche Modellierung, Kernel Mean Matching, Modellrisikoabschätzung, ökologische und biomedizinische Daten