Clear Sky Science · de
Verbesserung der Widerstandsfähigkeit gegen Angriffe in semantischen Caches für sichere Retrieval-Augmented-Generation-Systeme
Warum eine klügere KI-Erinnerung wichtig ist
Da Chatbots und KI‑Assistenten in Büros, Klassenzimmern und sogar Krankenhäusern Einzug halten, verlassen sie sich zunehmend auf einen Trick namens „Erinnern“ an frühere Fragen, um ähnliche Anfragen schneller und kostengünstiger beantworten zu können. Diese Erinnerung, bekannt als semantischer Cache, kann Kosten und Verzögerungen drastisch reduzieren – eröffnet aber zugleich Angreifern eine Hintertür, Systeme zur Preisgabe von Geheimnissen oder zur Ausgabe falscher Antworten zu bewegen. Dieses Papier untersucht diese verborgenen Risiken und stellt ein neues Design vor, SAFE-CACHE, das die Geschwindigkeit der KI‑Erinnerung bewahren und gleichzeitig den Missbrauch deutlich erschweren soll.
Wie heutige KI‑Assistenten frühere Antworten wiederverwenden
Moderne große Sprachmodelle (LLMs) arbeiten oft in einer Konfiguration namens Retrieval‑Augmented Generation (RAG). Wenn Sie eine Frage stellen, sucht das System zunächst relevante Dokumente und lässt das LLM dann eine Antwort unter Verwendung dieses Materials formulieren. Da viele Menschen fast dieselbe Frage mit anderen Worten stellen, fügen Unternehmen inzwischen einen semantischen Cache hinzu: eine Ablage alter Fragen und Antworten sowie mathematische Fingerabdrücke ihrer Bedeutung. Kommt eine neue Anfrage, prüft das System, ob deren Fingerabdruck „nah genug“ an einem bereits im Cache vorhandenen liegt; ist das der Fall, wird einfach die alte Antwort wiederverwendet, anstatt den kompletten Such‑und‑Generierungsprozess erneut auszuführen. Diese Idee, eingesetzt von Tools wie GPTCache und Cloud‑Plattformen von Microsoft und Google, spart Geld und beschleunigt Antworten in Kundenservice‑Bots, Unternehmens‑Chat‑Tools und anderen stark frequentierten KI‑Diensten. 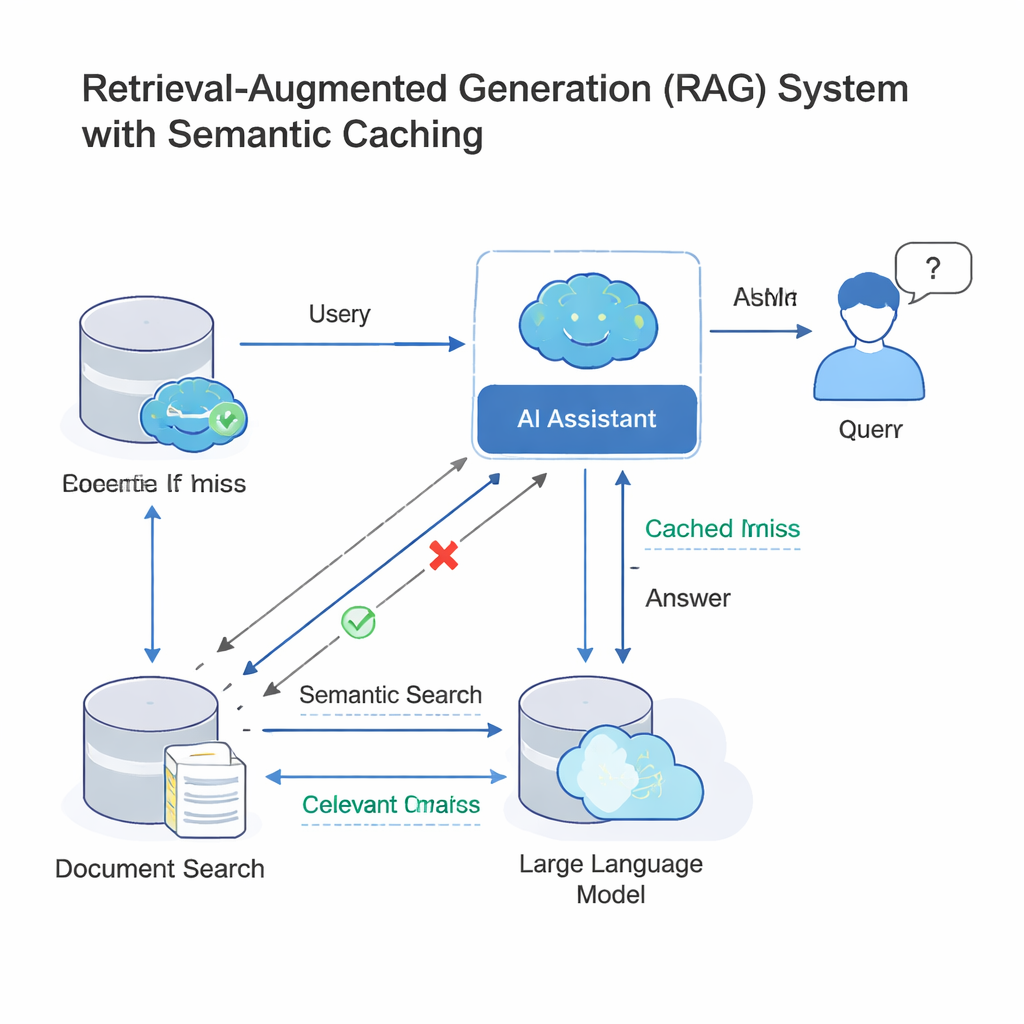
Wenn clevere Formulierungen zur Sicherheitslücke werden
Die gleiche Abkürzung, die die Geschwindigkeit erhöht, kann auch gegen das System verwendet werden. Angreifer können Anfragen so gestalten, dass sie in Struktur ähnlich wirken, aber eine andere Bedeutung haben – ein Datum ändern, eine Person oder einen Ort austauschen oder die Aussage einer Frage umkehren. Da heutige Caches überwiegend der numerischen Ähnlichkeit von Embeddings (diesen Bedeutungs‑Fingerabdrücken) vertrauen, kann eine bösartige Anfrage in diesem Vektorraum mit einer harmlosen kollidieren, obwohl sich die Intention verschoben hat. Diese Kollision kann dazu führen, dass der Cache die falsche Antwort zurückgibt, vertrauliche Informationen preisgibt oder zulässt, dass schlechte Daten für spätere Wiederverwendungen gespeichert werden. Frühere Arbeiten haben bereits gezeigt, dass Vektordatenbanken und semantische Caches auf diese Weise vergiftet werden können, insbesondere wenn viele Nutzer denselben zugrunde liegenden Cache in Multi‑Tenant‑Systemen teilen.
Streute Fragen in stabile Intent‑Cluster verwandeln
Die Autoren argumentieren, dass das Grundproblem darin liegt, jede Anfrage isoliert zu behandeln. Ihre Lösung, SAFE-CACHE, gruppiert frühere Frage‑Antwort‑Paare in Cluster, die zugrundeliegende Intentionen repräsentieren – etwa „Wer hat das Senatsrennen in Arizona 2022 gewonnen?“ oder „Wie viel kostet Teslas Full Self‑Driving‑Software?“. Anstatt neue Anfragen direkt mit einzelnen alten zu vergleichen, setzt SAFE‑CACHE auf den Vergleich mit dem Zentrum, dem Centroid, jedes Clusters. Zum Aufbau dieser Cluster werden zunächst vollständige Frage‑Antwort‑Paare eingebettet (nicht nur die Frage allein), sodass Unterschiede in den Antworten – etwa eine Weigerung, sensible Daten preiszugeben – ebenfalls die Gruppierung beeinflussen. Anschließend wird ein Community‑Detection‑Algorithmus verwendet, um natürliche Cluster zu finden, und statistische Tests, um Rauschgruppen zu markieren, die unterschiedliche Intentionen oder gegnerische Einträge mischen könnten. Diese verdächtigen Cluster werden mit Hilfe eines speziell trainierten Bi‑Encoders bereinigt und aufgeteilt, der gelernt hat, ehrliche Beispiele zusammenzuführen und vergiftete auseinanderzuziehen.
Ein kleines Modell trainieren, um die KI‑Erinnerung zu stärken
Einige Intentionen treten im realen Verkehr nur selten auf, wodurch ihre Cluster fragil sind. Um sie zu stabilisieren, nutzt SAFE‑CACHE ein feinabgestimmtes, leichtgewichtiges Sprachmodell (eine Gemma‑3‑Variante mit etwa 1 Milliarde Parametern), um Paraphrasen zu erzeugen, die dieselbe Intention bei variierter Formulierung bewahren. Diese zusätzlichen Beispiele machen die Cluster dichter und ihre Centroid‑Positionen zuverlässiger, ohne dass Menschen Tausende Varianten kennzeichnen müssen. Zur Laufzeit wird jede neue Anfrage eingebettet und mit diesen Centroiden verglichen. Liegt ihre Ähnlichkeit zum am besten passenden Centroid über einer sorgfältig abgestimmten Schwelle, wird die gecachte Antwort zurückgegeben; andernfalls greift das System auf die vollständige RAG‑Pipeline zurück und entscheidet später, wie das neue Paar geclustert werden soll. In Experimenten mit starken Angriffsverfahren basierend auf metamorpher Umschreibung und GPT‑4.1 reduzierte SAFE‑CACHE erfolgreiche Vergiftungsversuche um etwa zwei Drittel bis drei Viertel gegenüber einem GPTCache‑ähnlichen Design, während die Antwortgeschwindigkeit im Wesentlichen unverändert blieb. 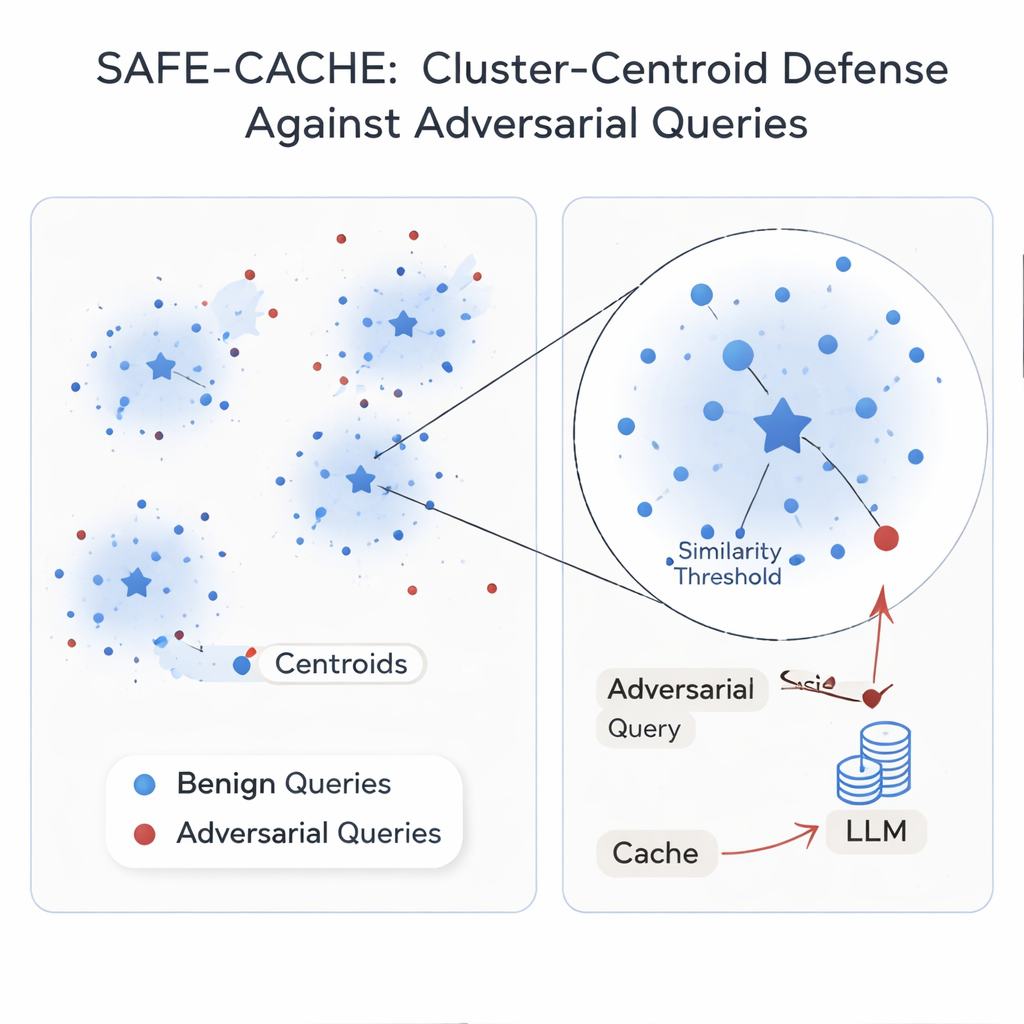
Was das für den Alltag von KI‑Nutzern bedeutet
Für Nicht‑Spezialisten lautet die Schlussfolgerung: KI‑Systemen „Erinnerung“ zu geben ist nicht kostenlos – naive Designs können Geheimnisse preisgeben oder dazu gebracht werden, falsche Antworten zu verbreiten. SAFE‑CACHE zeigt, dass man durch die Organisation der Erinnerung um tiefere, intent‑basierte Muster und die Verstärkung dieser Muster mit gezielten Paraphrasen die Geschwindigkeits‑ und Kostenvorteile semantischer Caches bewahren und gleichzeitig das Angriffsrisiko erheblich senken kann. Da KI‑Assistenten zur Zugangstür zu sensiblen Daten werden – von Unternehmensunterlagen bis zu persönlichen Informationen – werden Ansätze wie SAFE‑CACHE entscheidend sein, um sicherzustellen, dass das, woran KI sich erinnert, nicht leicht gegen uns verwendet werden kann.
Zitation: Afiffy, M., Fakhr, M.W. & Maghraby, F.A. Enhancing adversarial resilience in semantic caching for secure retrieval augmented generation systems. Sci Rep 16, 5936 (2026). https://doi.org/10.1038/s41598-026-36721-w
Schlüsselwörter: semantischer Cache, retrieval-augmented generation, gegnerische Angriffe, cluster-basierte Verteidigung, LLM-Sicherheit