Clear Sky Science · de
Wichtigkeitsgeführter Autoencoder zur Dimensionsreduktion in Intrusion-Detection-Systemen
Warum intelligentere Cyberabwehr wichtig ist
Jede E‑Mail, jedes gestreamte Video und jeder Einkauf reist über Netzwerke, die ständig angegriffen werden. Intrusion-Detection-Systeme (IDS) fungieren dabei wie Alarmanlagen für diese Netze und erkennen verdächtiges Verhalten, bevor es zu einem Einbruch kommt. Moderne Netzwerkinformationen sind jedoch riesig und komplex; das Durchforsten all dieser Details kann Systeme ausbremsen oder dazu führen, dass subtile Angriffe übersehen werden. Dieser Beitrag untersucht eine neue Methode, die diese Daten intelligent verkleinert, sodass IDS‑Werkzeuge sowohl schneller werden als auch besser darin, selbst seltene, schwer erkennbare Cyberangriffe aufzuspüren. 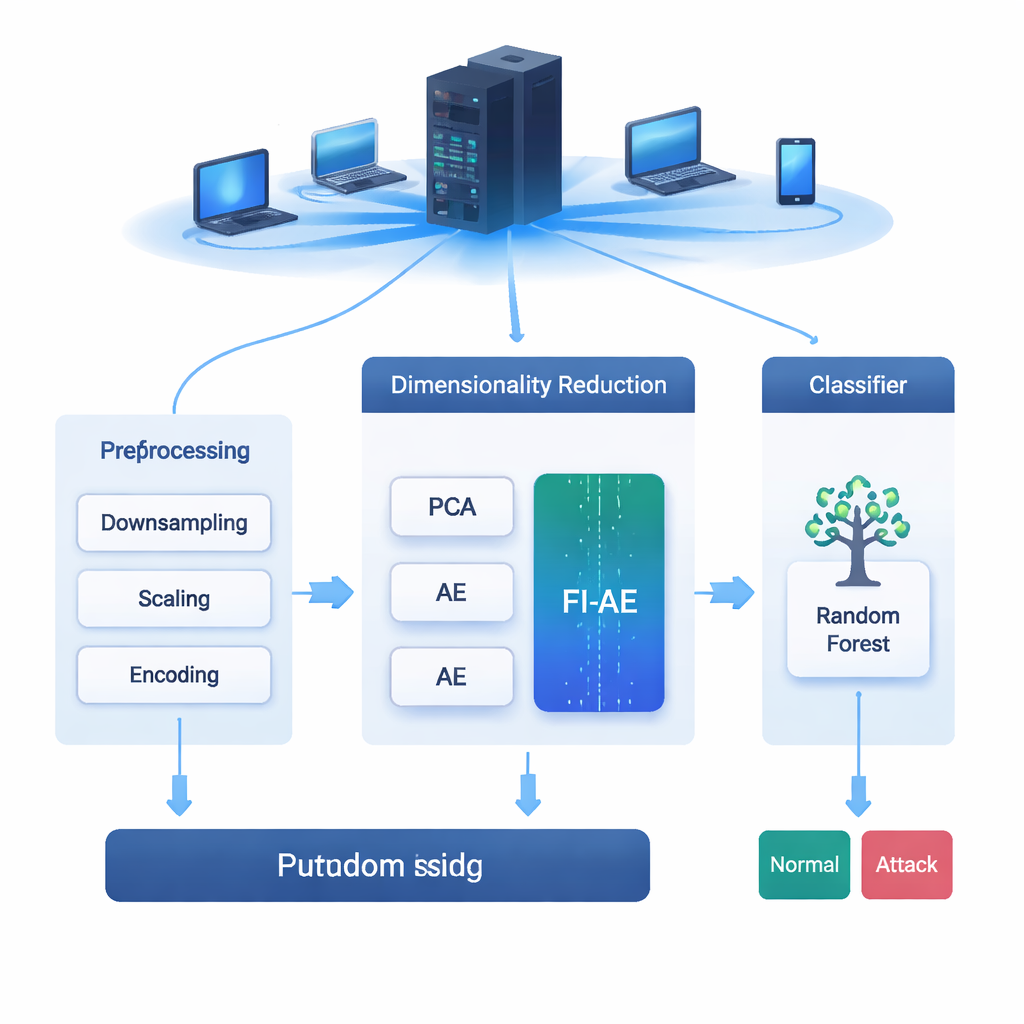
Das Problem zu vieler Netzwerkdaten
Netzwerkverkehrsaufzeichnungen enthalten Dutzende bis Hunderte von Messwerten für jede Verbindung — etwa Dauer, Anzahl der Bytes und Fehlerraten. Auf maschinellem Lernen basierende IDS-Modelle stützen sich auf diese Messwerte, um zu entscheiden, ob Verkehr normal oder bösartig ist. Die Nutzung aller Messwerte kann jedoch die Erkennung verlangsamen und manchmal sogar die Genauigkeit verschlechtern, besonders wenn einige Angriffe viel seltener sind als andere. Übliche Methoden zur Dimensionsreduktion, wie Principal Component Analysis und Standard‑Autoencoder, komprimieren die Daten, konzentrieren sich dabei aber vor allem auf die Rekonstruktion des Gesamtverkehrs. Das bedeutet, sie legen womöglich mehr Gewicht auf die Mehrzahl der alltäglichen Verbindungen und übersehen die schwachen, charakteristischen Muster, die Minderheitsangriffe kennzeichnen.
Eine neue Methode, um wirklich Wichtige zu bewerten
Die Autorinnen und Autoren stellen ein Merkmalssortierverfahren namens One‑Versus‑All (OVA) Feature Importance vor, um dieses Ungleichgewicht anzugehen. Anstatt zu fragen: „Welche Messwerte sind insgesamt am nützlichsten?“, beantwortet OVA diese Frage getrennt für jeden Angriffstyp. Für jede Klasse (zum Beispiel normaler Verkehr, Denial‑of‑Service oder Passwort‑Erraten) wird ein Random‑Forest‑Modell trainiert, das diese Klasse gegen alle anderen unterscheidet. Die eingebauten Wichtigkeitswerte des Modells zeigen dann, welche Messwerte speziell für diese Klasse besonders hilfreich sind. Indem man diesen Prozess klasse für klasse wiederholt und für jede Messgröße den höchsten Wichtigkeitswert über alle Klassen hinweg nimmt, entsteht ein einzelner Gewichtungsvektor, der Merkmale hervorhebt, die für mindestens eine Art von Angriff relevant sind — selbst wenn dieser Angriff in den Daten selten vorkommt.
Den Autoencoder auf die Schlüsselsignale ausrichten
Um diese Gewichte zu nutzen, entwerfen die Forschenden einen feature‑importance‑basierten Autoencoder (FI‑AE). Wie ein herkömmlicher Autoencoder komprimiert FI‑AE die Eingaben zu einer niedrigdimensionalen „Flaschenhals“-Darstellung und rekonstruiert anschließend die Originaldaten. Der Unterschied liegt in der Trainingszielgröße: Anstatt alle Rekonstruktionsfehler gleich zu behandeln, verwendet das Modell einen gewichteten mittleren quadratischen Fehler, der jeden Fehler eines Merkmals mit seiner OVA‑basierten Wichtigkeit multipliziert. Einfach gesagt wird FI‑AE stärker bestraft, wenn es Messwerte, die entscheidend für die Unterscheidung von Angriffen sind, falsch darstellt, und weniger für weniger informative Details. Die Architektur selbst ist kompakt und reduziert Netzwerkaufzeichnungen auf nur 16 Zahlen, wobei Standardtechniken wie Batch‑Normalisierung, Dropout und der Adam‑Optimizer verwendet werden, um ein stabiles Training zu gewährleisten.
Die Methode auf die Probe stellen
Das Team bewertet FI‑AE an drei weit verbreiteten Intrusion‑Detection‑Datensätzen: NSL‑KDD, UNSW‑NB15 und CIC‑IDS2017, die zusammen Millionen von Verbindungen und eine breite Palette von Angriffstypen abdecken. Vor dem Training bereinigen sie die Daten, indem sie extrem verzerrte Klassendistributionen ausgleichen, numerische Merkmale skalieren und Kategorien so kodieren, dass ihre Beziehung zu den Zielkategorien erhalten bleibt. Anschließend vergleichen sie drei Pipelines, die alle mit einem Random‑Forest‑Klassifikator enden: eine mit PCA, eine mit einem Standard‑Autoencoder und eine mit FI‑AE zur Dimensionsreduktion. Über alle drei Datensätze hinweg liefert FI‑AE durchgehend höhere Genauigkeit und F1‑Scores, mit besonders deutlichen Verbesserungen bei Minderheits‑ und seltenen Angriffen, bei denen traditionelle Methoden typischerweise Schwierigkeiten haben. 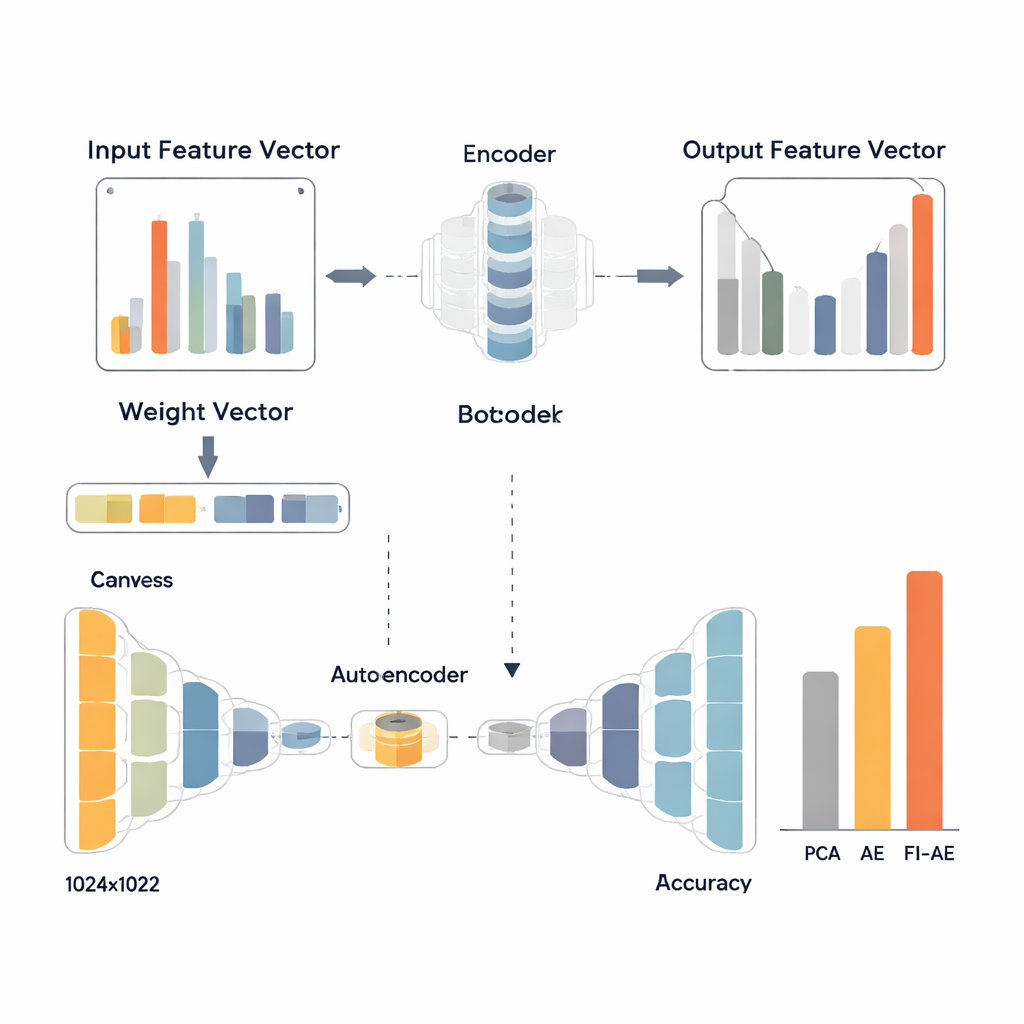
Was das für die alltägliche Sicherheit bedeutet
Für Nicht‑Spezialisten ist die Kernbotschaft, dass diese Arbeit eine feinere Linse für die Netzwerküberwachung bietet. Anstatt Daten nur zu komprimieren, um sie kleiner zu machen, lernt FI‑AE, die Messwerte zu bewahren, die wirklich wichtig sind, um verschiedene Angriffsarten zu erkennen — einschließlich der seltenen, oft besonders schädlichen. Mit nur 16 verdichteten Merkmalen können auf diesem Ansatz basierende Intrusion‑Detection‑Systeme effizienter arbeiten und dennoch eine gleichwertige oder bessere Erkennungsgenauigkeit erreichen. In der Praxis bedeutet das, dass Sicherheitstools mehr Verkehr scannen, schneller reagieren und besseren Schutz für die digitalen Dienste bieten können, auf die Menschen täglich angewiesen sind.
Zitation: Abdel-Rahman, M.A., Alluhaidan, A.S., El-Rahman, S.A. et al. Feature importance guided autoencoder for dimensionality reduction in intrusion detection systems. Sci Rep 16, 5013 (2026). https://doi.org/10.1038/s41598-026-36695-9
Schlüsselwörter: Intrusion-Detection, Netzwerksicherheit, Dimensionsreduktion, Autoencoder, Merkmalswichtigkeit