Clear Sky Science · de
Echtzeit-Erkennung von Feuer und Rauch mithilfe von Vision-Transformern und spatiotemporalem Lernen
Warum schnellere Brandwarnungen wichtig sind
Brände in Wohnungen, Fabriken und Wäldern können sich in wenigen Minuten tödlich entwickeln. Viele heutige Alarmsysteme beruhen noch auf Wärme- oder Rauchsensoren, die erst reagieren, wenn die Flammen bereits gut entwickelt sind. Dieser Artikel beschreibt ein neues Computer-Vision-System, das Anzeichen von Feuer und Rauch in Kamerabildern nahezu sofort erkennen kann, selbst unter schwierigen Bedingungen wie schwachem Licht oder dichter Dunst. Indem mehrere fortgeschrittene Methoden der künstlichen Intelligenz in einem einzigen Modell kombiniert werden, wollen die Forschenden Feuerwehrleuten, Stadtplanern und Umweltbehörden deutlich frühere Warnsignale liefern — mit dem Potenzial, Leben, Eigentum und Ökosysteme zu schützen.
Die wachsende Herausforderung, Flammen zu erkennen
Moderne Städte und Wälder werden zunehmend mit Kameras überwacht, doch Computern zuverlässig beizubringen, Feuer und Rauch in Bildern und Videos zu erkennen, ist knifflig. Traditionelle Ansätze verwenden neuronale Netze, die bei Standbildern oder kurzen Clips gut funktionieren, doch in unordentlichen Realweltszenen oft Probleme haben. Eine einzelne Aufnahme kann etwas zeigen, das wie Rauch aussieht, in Wirklichkeit aber nur Nebel oder Abgase ist. Videoorientierte Systeme können verfolgen, wie sich Formen im Laufe der Zeit bewegen, sind aber häufig langsam und hardwareintensiv. In der Folge lösen frühere Modelle oft Fehlalarme aus oder übersehen subtile, schnell wechselnde Gefahrenzeichen — insbesondere bei schlechtem Licht, dichtem Rauch oder unruhigem Hintergrund.
Ein hybrider KI-„Wächter“ für Bilder und Video
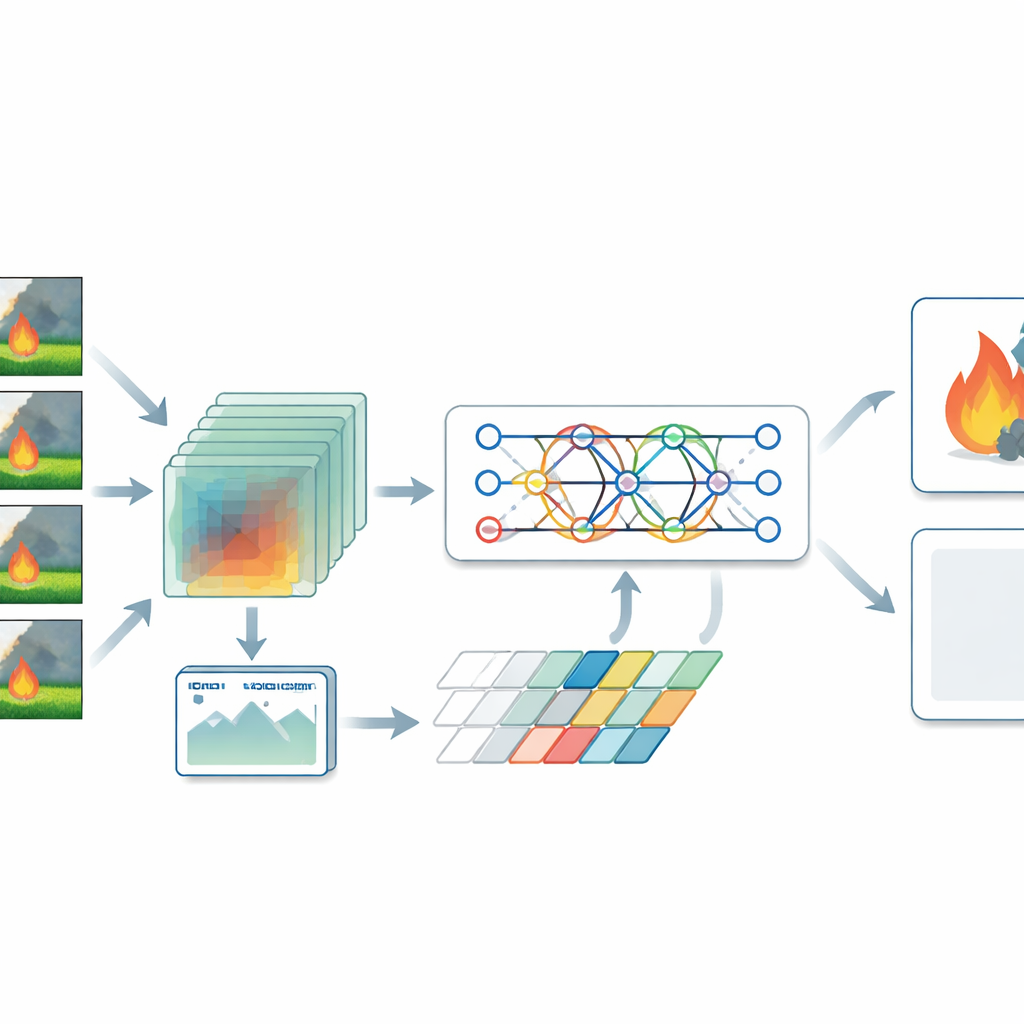
Die Autorinnen und Autoren schlagen ein hybrides Modell vor, das Branddetektion sowohl als räumliches als auch als zeitliches Problem angeht. Für Standbilder nutzen sie einen Typ neuronaler Netze, der als Vision-Transformer bekannt ist und ein Bild als Flickwerk von Regionen betrachtet, wobei er lernt, wie weit auseinanderliegende Bereiche zueinander in Beziehung stehen. Das hilft, großflächige Muster zu erkennen, etwa Rauchfahnen, die sich über ein Tal ausbreiten, oder verstreute Flammen in einem Wald. Für Video setzt das System auf ein dreidimensionales Faltungsnetz, das Stapel von Frames gleichzeitig verarbeitet und erfasst, wie sich Rauch und Feuer über die Zeit verändern. Ein Transformer-Encoder analysiert dann diese sich verändernden Muster und richtet die Aufmerksamkeit auf die Momente und Bereiche, die am ehesten auf Gefahr hinweisen, anstatt jedem Frame das gleiche Gewicht zu geben.
Hinweise zusammenführen und die Daten ausbalancieren
Ein zentraler Schritt im System ist eine Fusionsschicht, die detaillierte Hinweise aus Standbildern mit Bewegungsmustern aus dem Video verbindet. Durch die Kombination dieser komplementären Perspektiven kann das Modell echte Brände besser von harmlosen Täuschungen wie Sonnenreflexen, Nebel oder Wolken unterscheiden. Die Forschenden stellten außerdem fest, dass viele öffentliche Datensätze deutlich mehr Brand- als Nicht-Brand-Beispiele enthalten, was ein Modell dazu verleiten kann, Flammen zu übermelden. Um dem entgegenzuwirken, erzeugten sie eine breite Palette realistischer Nicht-Brand-Szenen durch sorgfältige Datenaugmentation — etwa durch Änderungen der Helligkeit, Zuschneiden und Spiegeln von Bildern sowie die Simulation von Situationen wie nebligen Morgen oder dunklen Innenräumen. Anschließend trainierten sie das Modell mit einer Verlustfunktion, die Fehler bei Brand- und Nicht-Brand-Fällen explizit ausgleicht, wodurch die Zuverlässigkeit im Alltag verbessert wird.
Das System auf die Probe stellen
Um die Leistungsfähigkeit ihres Ansatzes zu prüfen, testeten die Autorinnen und Autoren ihn an zwei weit verbreiteten Datensätzen: einem mit fast tausend Standbildern aus der NASA Space Apps Challenge und einem weiteren mit brandbezogenen Videos von Kaggle. Nach Vorverarbeitung und Ausbalancierung trainierten und evaluierten sie ihr hybrides Modell neben bekannten Baselines wie ResNet, VGG, LSTM, reinen 3D-Faltungsnetzen und mehreren hybriden Kombinationen dieser älteren Methoden. Das neue System erreichte etwa 99,2 % Genauigkeit bei den NASA-Bildern und 98,3 % beim Videodatensatz und übertraf damit deutlich die traditionellen Modelle, die typischerweise im Bereich der mittleren 80er bis mittleren 90er lagen. Es lief außerdem schnell genug — nur wenige zehn Millisekunden pro Frame — und bei moderater Modellgröße, sodass es sich für den Einsatz an Edge-Geräten wie kleinen GPUs und Embedded-Boards eignet.
Was das für die alltägliche Sicherheit bedeutet
Praktisch zeigt diese Forschung, dass eine durchdacht gestaltete KI Kamerabilder in Echtzeit überwachen und zuverlässig eine einfache, aber lebenswichtige Frage beantworten kann: "Gibt es hier gerade Feuer oder gefährlichen Rauch?" Durch die Kombination von weitem visuellen Kontext, Bewegungen über die Zeit und gezielter Aufmerksamkeit auf die aussagekräftigsten Details reduziert das hybride Modell sowohl verpasste Brände als auch Fehlalarme deutlich. Mit weiterer Feinabstimmung und zusätzlicher Exposition gegenüber stärker variierenden Szenen — etwa dichten Städten, Untergrundräumen und extremen Wetterverhältnissen — könnte es zur praktischen Grundlage für intelligentere Alarmsysteme, Netzwerke zur Überwachung von Waldbränden und industrielle Sicherheitslösungen werden, die schneller und genauer reagieren als viele heutige Systeme.
Zitation: Lilhore, U.K., Sharma, Y.K., Venkatachari, K. et al. Real time fire and smoke detection using vision transformers and spatiotemporal learning. Sci Rep 16, 8928 (2026). https://doi.org/10.1038/s41598-026-36687-9
Schlüsselwörter: Branddetektion, Raucherkennung, Computer Vision, Transformermodelle, Echtzeitüberwachung