Am Meeresboden fungieren autonome Unterwasserfahrzeuge als unsere Augen und Ohren für Klimaforschung, Infrastrukturinspektionen und Such‑und‑Rettung. Doch diese Roboter‑U-Boote haben mit einem grundlegenden Problem zu kämpfen: Sie müssen in einer rauen Umgebung klar kommunizieren und denken, in der Signale langsam, verrauscht und stromsparend übermittelt werden müssen. Dieses Papier stellt einen neuen Ansatz vor, der Unterwasserrobotern durch die Kombination von Augmented und Virtual Reality mit einer KI‑Richtung namens Reinforcement Learning dabei hilft, zu kommunizieren, Objekte zu erkennen und sicherer zu agieren.
Warum Unterwasserkommunikation so schwierig ist
Datenübertragung unter Wasser ist wesentlich anspruchsvoller als durch Luft. Radiowellen, die Wi‑Fi und 5G antreiben, werden vom Meerwasser schnell gedämpft. Akustische (schallbasierte) Signale kommen zwar weiter, bieten aber sehr geringe Datenraten und können verzögert, reflektiert oder verzerrt werden. Magnetinduktion funktioniert nur über einige Dutzend Meter. Bestehende Steuerungssysteme für Unterwasserroboter behandeln diese Kanäle oft separat und nutzen feste Regeln für Navigation und Sensorik. Das macht sie träge gegenüber veränderten Bedingungen, verschwendet Batterieenergie und lässt Kommunikationsverbindungen anfällig für Abhören oder Angriffe.
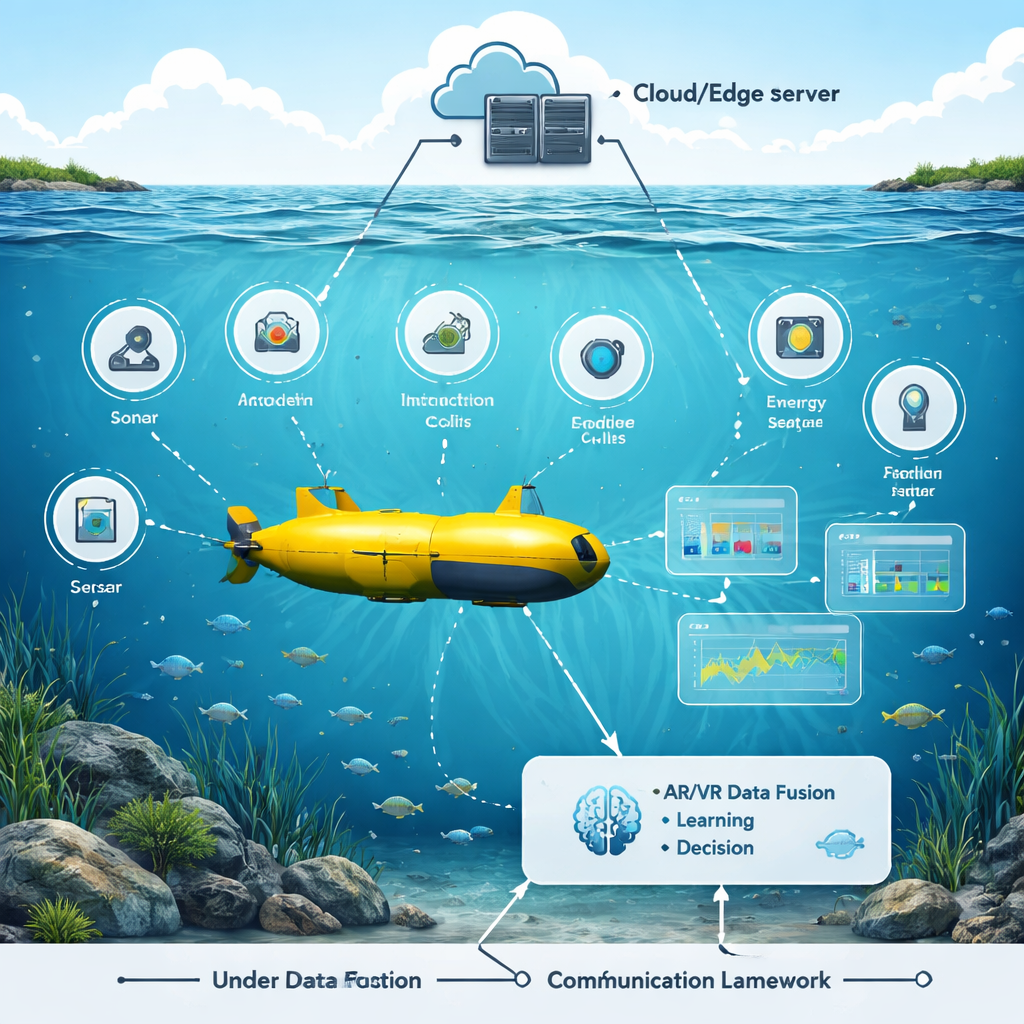
Ein virtueller Ozean, um bessere Instinkte zu trainieren Figure 1.
Die Autoren haben einen Augmented‑ und Virtual‑Reality‑Testbed aufgebaut, der eine belebte Unterwasserwelt nachbildet: schwimmende Fische, Felsen, Boote und Bojen sowie realistische Störgeräusche und Signalverluste im Wasser. Ein simuliertes Unterwasserfahrzeug fährt durch diese Umgebung und nutzt zahlreiche Sensoren – Sonar, Kameras, akustische Modems, Energiemesser und Positionssensoren. In der virtuellen Szene können Forschende Regler verschieben, um Objektpositionen, Wasserbedingungen und Sensoreinstellungen zu ändern, und sofort sehen, wie der Roboter reagiert. Diese AR/VR‑Schicht ist nicht nur visuelle Spielerei; sie verschmilzt rohe Sensordaten zu einem einheitlichen 3D‑Bild, das für ein KI‑System leichter zu interpretieren und darauf zu reagieren ist.
Dem Roboter beibringen, aus Erfahrung zu lernen
Im Kern des Frameworks steht eine KI‑Strategie, die die Autoren Adaptive Augmented Reality and Reinforcement Learning Scheduling Strategy (AARLSS) nennen. Anstatt einem festen Skript zu folgen, lernt der Roboter durch Versuch und Irrtum im virtuellen Ozean. In jedem Moment beobachtet er seinen zusammengeführten Sensorzustand, wählt eine Aktion (etwa Kursänderung, Anpassung der Abtastrate von Sensoren oder Umschalten zwischen Kurz‑ und Langstreckenkommunikation) und erhält eine Belohnung. Diese Belohnung balanciert vier Ziele: Energieeinsparung, Verringerung der Latenz, Senkung des Sicherheitsrisikos und geringerer Einsatz von Rechen‑ und Netzwerkressourcen. Ein Deep‑Q‑Learning‑Netzwerk speichert und aktualisiert den erwarteten Wert verschiedener Entscheidungen und verwendet Mini‑Batches vergangener Erfahrungen, die in einem Replay‑Memory gehalten werden, sodass der Roboter sowohl aus jüngeren als auch älteren Situationen lernen kann.
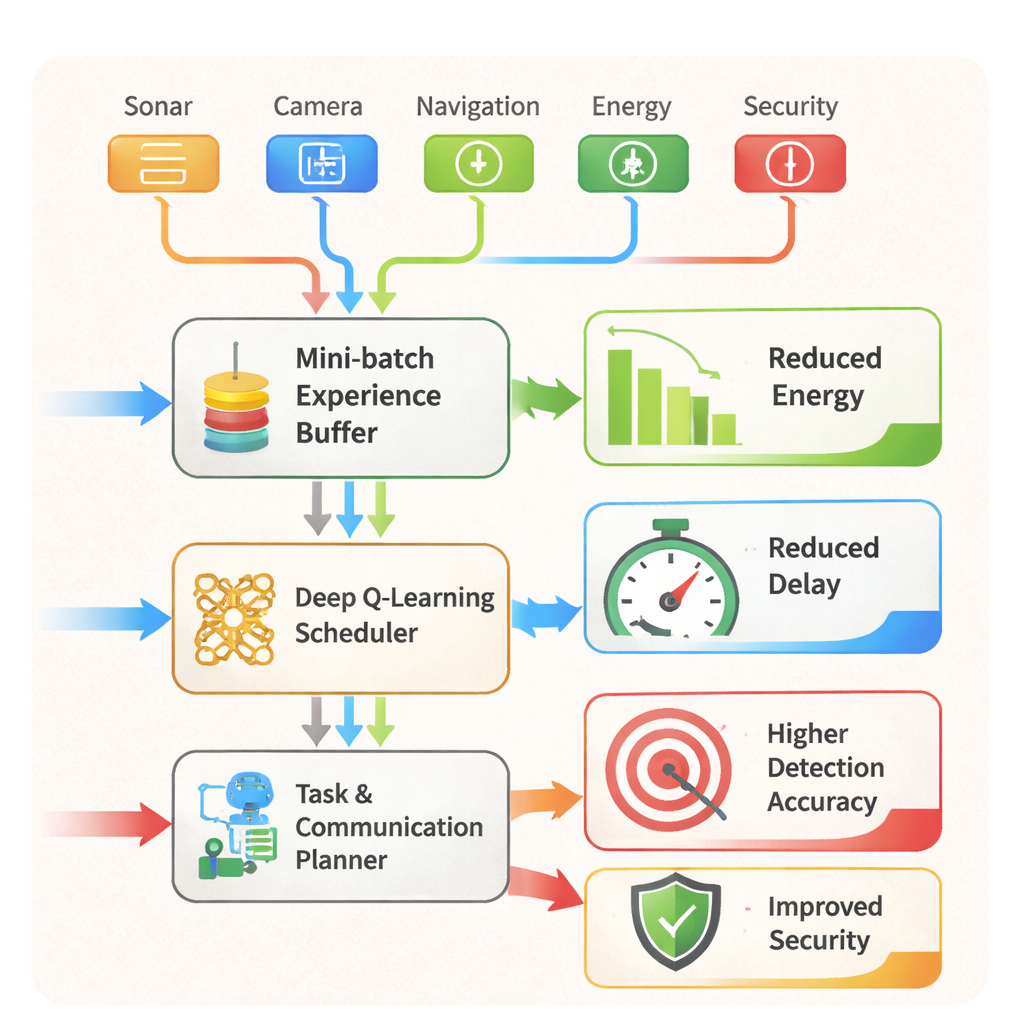
Von smarter Planung zu sichereren Einsätzen Figure 2.
AARLSS fungiert auch als Echtzeit‑Scheduler. Es entscheidet, welche Aufgaben – Navigation, Objekterkennung, Kommunikation oder Sicherheitsprüfungen – wo und wann ausgeführt werden sollten, und ob Daten an Bord verarbeitet, an einen Edge‑Server ausgelagert oder verzögert werden. Zusätzlich durchsucht ein integriertes Intrusion‑Detection‑System kontinuierlich Muster in Sensor‑ und Netzdaten, um Anomalien zu erkennen, die auf einen Angriff oder eine Fehlfunktion hindeuten könnten, und kann Schutzmaßnahmen auslösen, etwa das Sperren riskanter Verbindungen oder das Erzwingen rein lokaler Berechnungen. In Tests im AR/VR‑Simulator übertraf das Framework mehrere etablierte Reinforcement‑Learning‑Methoden. Es senkte den Energieverbrauch des Unterwasserfahrzeugs um etwa 20 %, reduzierte Kommunikations‑ und Aufgabendauern um rund 18–20 % und steigerte die Objekterkennungsgenauigkeit auf etwa 97–98 %, selbst bei komplexen Manövern und in überfüllten Szenen.
Was das für die reale Meereswelt bedeutet
Für Nicht‑Fachleute lautet die Kernbotschaft: Diese Forschung weist in Richtung Unterwasserroboter, die unabhängiger, effizienter und vertrauenswürdiger sind. Indem sie in einem reichhaltigen virtuellen Ozean trainieren und lernen, Energie, Zeit, Genauigkeit und Sicherheit gleichzeitig abzuwägen, ermöglicht AARLSS einem Fahrzeug, zu entscheiden, wann es sprechen, wann es lauschen und wann es aus Energiespargründen schweigen sollte – und dabei die Umgebung aufmerksam im Blick zu behalten und die eigenen Daten zu schützen. Obwohl diese Ergebnisse aus einem ausgefeilten Simulator stammen und nicht aus offener See, deuten sie darauf hin, dass künftige Flotten von Unterwasserrobotern längere, sicherere und datenreichere Missionen mit weniger menschlicher Aufsicht durchführen könnten, was alles verbessern würde, von der Meeresforschung bis zu Inspektionen der Offshore‑Industrie.
Zitation: Lakhan, A., Mohammed, M.A., Ghani, M.K.A. et al. A novel augmented reality and reinforcement learning empowered communication framework for underwater unmanned autonomous vehicle.
Sci Rep16, 6241 (2026). https://doi.org/10.1038/s41598-026-36647-3