Clear Sky Science · de
Intelligente Erkennung des Verhaltens von Schülern für intelligente Lernumgebungen
Warum intelligentere Klassenräume sehen müssen, was Schüler tun
In vielen Klassenräumen müssen Lehrkräfte raten, wer aufmerksam ist, wer den Anschluss verloren hat und wer still und heimlich nicht bei der Sache ist. Dieses Papier untersucht, wie künstliche Intelligenz automatisch erkennen kann, was Schüler tun — etwa lesen, schreiben oder die Hand heben — anhand gewöhnlicher Klassenraumfotos. Indem rohe Bilder in verlässliche Messgrößen für Klassenraumaktivität verwandelt werden, soll das System Lehrkräften Echtzeit‑Feedback zur Engagementlage liefern, ohne auf zeitaufwändige Beobachtung oder aufdringliche Überwachung angewiesen zu sein.
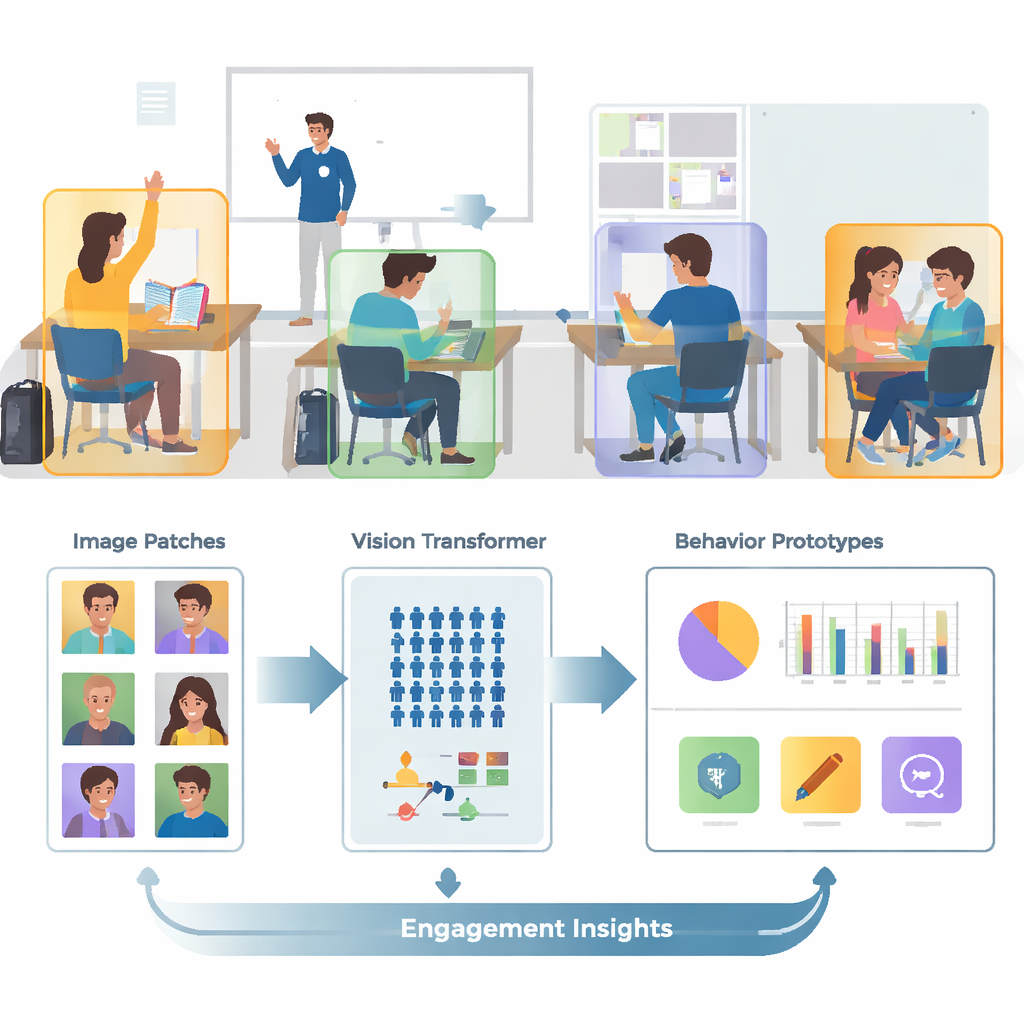
Von unübersichtlichen Fotos zu fokussierten Ausschnitten
Reale Klassenräume sind voll, geschäftig und visuell verwirrend. Ein einzelnes Bild kann Dutzende Schüler, überlappende Körper und ablenkende Hintergrunddetails wie Wände, Bildschirme oder Poster enthalten. Die Autoren bauen auf einer öffentlichen Bildsammlung namens SCB‑05 auf, die Tausende von Klassenraumfotos enthält, die mit spezifischen Verhaltensweisen wie Handheben, Lesen, Schreiben, Stehen, Sprechen oder Interagieren an der Tafel gekennzeichnet sind. Anstatt gesamte Szenen in das System zu geben, verwendet das Modell zunächst Annotationsdateien, um nur die Bereiche um einzelne Schüler oder Lehrkräfte herauszuschneiden. Dieser Vorverarbeitungsschritt entfernt einen Großteil der visuellen Unordnung, sodass das Modell sich auf Körperhaltung, Handposition und andere Hinweise konzentrieren kann, die ein Verhalten von einem anderen unterscheiden.
Wie die KI neue Verhaltensweisen aus sehr wenigen Beispielen lernt
Ein großes Problem ist, dass manche Klassenraumverhaltensweisen in den Daten häufig vorkommen (wie Lesen), andere dagegen selten sind (wie kurze Bühneninteraktionen). Für jede mögliche Verhaltensklasse ausreichend viele gelabelte Bilder zu sammeln ist teuer und wirft Datenschutzfragen auf. Um das zu umgehen, nutzen die Autoren eine Strategie namens „Few‑Shot‑Learning“, bei der das Modell darauf trainiert wird, neue Klassen aus nur wenigen Beispielen zu erkennen. Das Training ist in viele kleine Aufgaben gegliedert, von denen jede nur wenige Verhaltensklassen und pro Klasse ein paar Beispielbilder enthält. Für jede Aufgabe bildet das System einen einfachen „Prototyp“ für jedes Verhalten, indem es die interne Repräsentation dieser Beispiele mittelt. Neue Bilder werden dann klassifiziert, indem geprüft wird, welchem Prototyp sie am nächsten sind — so kann das Modell sich schnell anpassen, selbst wenn nur wenige Daten vorliegen.
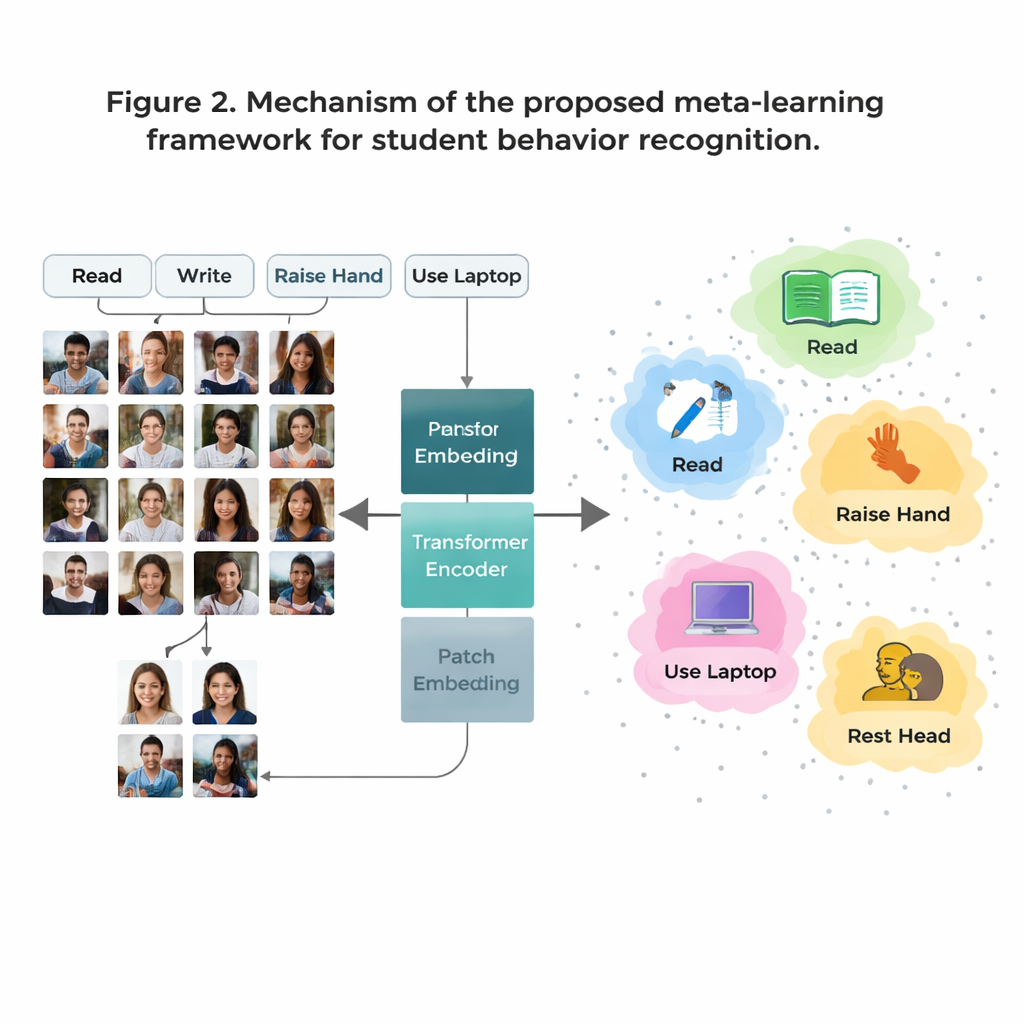
Den ganzen Klassenraum sehen, nicht nur kleine Details
Traditionelle Bildsysteme, sogenannte Convolutional Neural Networks, neigen dazu, sich auf kleine lokale Muster wie Kanten oder Texturen zu konzentrieren. Das ist begrenzend, wenn zwei Verhaltensweisen, etwa Lesen und Schreiben, aus der Nähe sehr ähnlich aussehen. Diese Arbeit ersetzt solche älteren Netze durch einen Vision Transformer, ein Modell, das jedes Bild in Patches zerlegt und lernt, wie alle Patches zueinander in Beziehung stehen. Diese globale Sicht hilft dem System, subtile Haltungsunterschiede und langreichweitige Hinweise zu verstehen — etwa die Beziehung zwischen einer erhobenen Hand und einer Lehrperson vorn im Raum. Das Team verfeinert das Modell zusätzlich, indem es es darauf trainiert, Bilder desselben Verhaltens näher zusammenzuführen und ähnlich aussehende, aber unterschiedliche Verhaltensweisen auseinanderzuziehen, mit besonderem Fokus auf „schwierige“, verwirrende Fälle. Dadurch wird die interne Karte der Verhaltensweisen klarer und besser trennbar.
Wie gut es funktioniert und warum das wichtig ist
Auf dem SCB‑05‑Benchmark erreicht die vorgeschlagene Methode etwa 91 % Gesamtgenauigkeit und starke Werte bei anspruchsvolleren Metriken, die unausgeglichene Daten berücksichtigen. Häufige Verhaltensweisen wie Lesen und Handheben werden besonders zuverlässig erkannt, während seltener auftretende wie das Schreiben an der Tafel weiterhin herausfordernder sind, aber immer noch bessere Ergebnisse liefern als frühere Systeme. Visuelle Inspektionen der internen Cluster des Modells zeigen, dass sich verschiedene Verhaltensweisen in dichten, gut getrennten Gruppen formen, was darauf hindeutet, dass die KI eindeutige „Signaturen“ von Klassenraumhandlungen gelernt hat. Bei Tests auf einem anderen Klassenraum‑Datensatz mit neuen Kamerawinkeln und Raumaufteilungen sank die Leistung nur leicht, was darauf hindeutet, dass die gelernte Repräsentation nicht an einen einzelnen Raum oder eine einzelne Schule gebunden ist.
Was das für Lehren und Lernen bedeutet
Praktisch zeigt die Studie, dass Computer viele wichtige Schülerverhaltensweisen aus Standbildern zuverlässig erkennen können, selbst wenn sie von jeder nur wenige Beispiele gesehen haben. Solche Systeme sollen Lehrkräfte nicht ersetzen, sondern könnten unaufdringlich zusammenfassen, wer engagiert ist, wer häufig Hilfe sucht oder welche Aktivitäten oft Aufmerksamkeit verlieren — und das ohne die Identität der Schüler nachzuverfolgen. Mit weiterer Arbeit zu Datenschutz, Fairness und zur Analyse von Videos über die Zeit hinweg könnte diese verhaltensbewusste KI zu einem starken Verbündeten für Lehrende werden, die responsivere und inklusivere Lernumgebungen gestalten wollen.
Zitation: Abozeid, A., Alrashdi, I. & Al-Makhlasawy, R.M. Intelligent recognition of students’ behavior for smart learning environments. Sci Rep 16, 5674 (2026). https://doi.org/10.1038/s41598-026-36633-9
Schlüsselwörter: smarter Klassenraum, Schülerverhalten, Computer Vision, Few‑Shot‑Learning, Vision Transformer