Clear Sky Science · de
Domänenübergreifende kontinuierliche Skalen-Superauflösung für Fernerkundungsbilder mittels Meta-Gewicht Lernen
Scharfere Ansichten aus dem All
Satellitenbilder treiben alles an, von Stadtplanung bis Katastrophenhilfe, aber viele Aufnahmen sind aufgrund von Begrenzungen in Kamerahardware und Datenübertragung unschärfer, als wir es uns wünschen. Diese Arbeit stellt eine neue Methode vor, um verschwommene Satellitenfotos in schärfere Bilder für beliebige Zoomstufen zu verwandeln, mithilfe einer Lernstrategie, die sich an die besonderen Eigenschaften luftgestützter Bilder anpasst, ohne für jede Situation neu trainiert werden zu müssen.
Warum schärfere Satellitenbilder wichtig sind
Hochauflösende Fernerkundungsbilder sind entscheidend, um kleine Objekte zu erkennen, Bodenveränderungen zu verfolgen und Landnutzung detailliert zu kartieren. In der Praxis müssen Satelliten jedoch Auflösung gegen Kosten, Sensorgröße und Bandbreite abwägen, sodass viele Bilder in niedrigerer Qualität ankommen, als Analysten es bevorzugen würden. Traditionelle „Super‑Resolution“-Verfahren können Bilder schärfen, sind aber meist für eine feste Vergrößerung wie genau zwei- oder vierfach trainiert. Das bedeutet, dass Betreiber für jede Zoomstufe separate Modelle benötigen, was ineffizient und unflexibel ist, wenn viele Satelliten und verschiedene Aufgaben zu bewältigen sind.
Mehr als ein Einheitszoom
Neuere Forschung hat „kontinuierliche Skalen“-Superauflösung entwickelt, die ein Bild als glattes Signal betrachtet und mit einem einzigen Modell scharfe Ausgaben für jeden Vergrößerungsfaktor erzeugen kann. Die meisten dieser Methoden wurden jedoch für Alltagsfotos entwickelt und getestet, nicht für Satellitendaten. Sie entscheiden typischerweise mithilfe fester geometrischer Regeln, wie benachbarte Pixelinformationen zu mischen sind — im Wesentlichen werden Nachbarn nach Abstand gewichtet. Das funktioniert für natürliche Szenen wie Gesichter oder Landschaften einigermaßen gut, aber Satellitenbilder enthalten dichte Bebauung, sich wiederholende Texturen und abrupte Kanten, die diesen Mustern nicht folgen. Wenn auf natürlichen Fotos trainierte Modelle auf Satellitenansichten angewendet werden, versagen ihre Annahmen, und Details wie Dächer, Straßen und Fahrzeuge werden nicht treu wiederhergestellt.
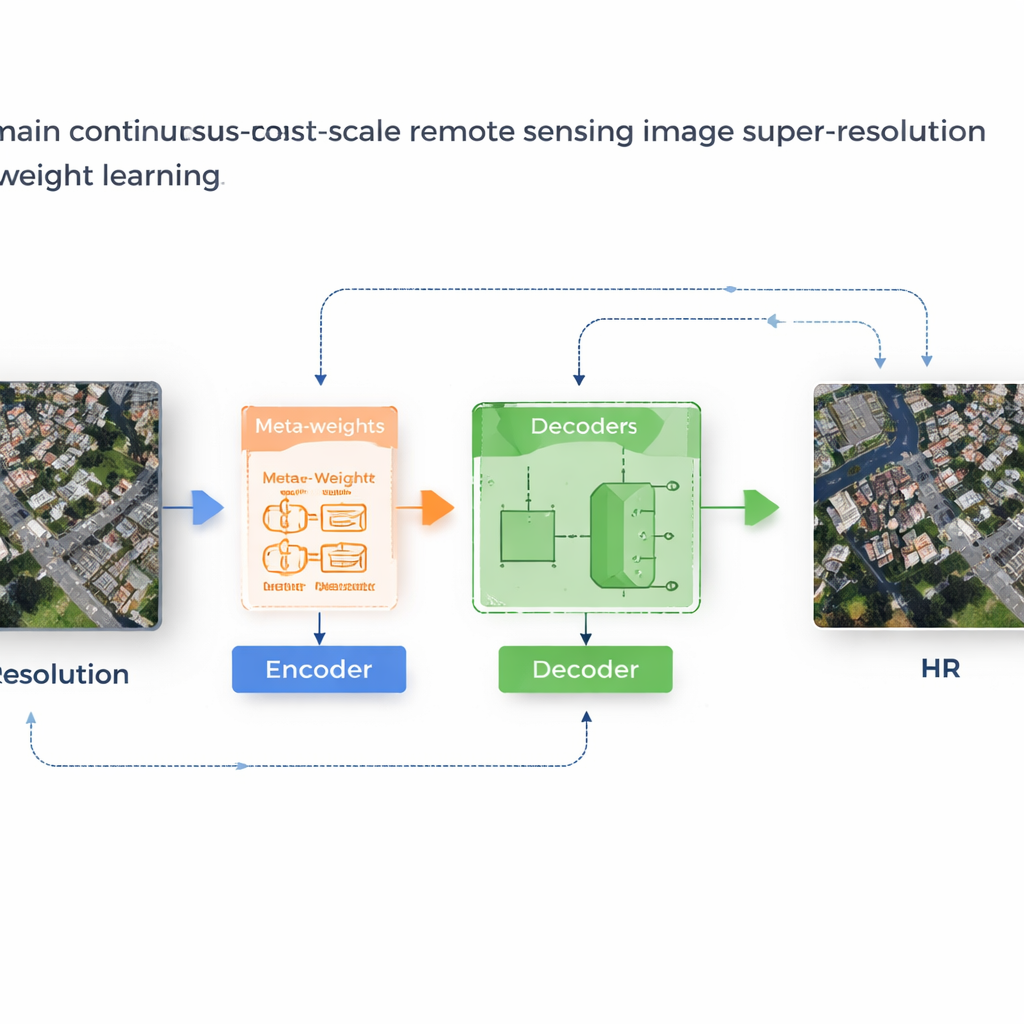
Ein Lernsystem, das seine eigenen Regeln anpasst
Die Autoren schlagen ein Framework namens MLIN (Meta-Learning-based Implicit Neural Network) vor, um dieses domänenübergreifende Problem zu lösen. Anstatt händisch festzulegen, wie benachbarte Pixelmerkmale kombiniert werden sollen, lernt MLIN diese Kombinationsregeln aus Daten. Es belässt einen leistungsfähigen Bild-Encoder, der ursprünglich auf Alltagsfotos trainiert wurde, vollständig eingefroren, sodass er weiterhin reichhaltige visuelle Muster extrahiert, ohne durch die kleineren Satellitendatensätze verzerrt zu werden. Darauf baut MLIN einen neuen „impliziten Decoder“ mit einem Meta-Lernmodul auf. Für jeden Punkt im hochaufgelösten Bild, den das Modell rekonstruieren möchte, schaut dieses Modul auf die umliegenden Merkmale und ihre exakten Positionen und sagt dann eine Menge von weichen Gewichten voraus, die dem Decoder anzeigen, wie stark jeder Nachbar zu berücksichtigen ist. Anders gesagt: Das System nimmt nicht mehr an, dass nur die Distanz zählt; es lässt den lokalen Inhalt — etwa Dachtexturen, Felder oder Wasserflächen — die Rekonstruktion mitgestalten.
Von verschwommenen Blöcken zu klaren Strukturen
Technisch funktioniert die Methode, indem für jede Zielposition im Ausgabebild eine kleine 2×2‑Nachbarschaft verborgener Merkmale abgetastet wird. Ein Meta‑Netz kombiniert dann Informationen über diese Merkmale, deren relative Koordinaten und den geforderten Vergrößerungsfaktor, um Gewichte zu wählen, die sich zu eins summieren. Der Decoder verwendet diese Gewichte, um Vorhersagen der einzelnen Nachbarn zu mischen und so einen endgültigen Farbwert an dieser Stelle zu erzeugen. Da diese Gewichtung gelernt wird, kann MLIN komplexe Regionen — etwa dichte Wohnblocks, Häfen mit Schiffen oder Flughäfen mit Start- und Landebahnen — ganz anders behandeln als homogene Bereiche wie Wüsten oder Ozeane. Experimente an zwei weit verbreiteten Satellitendatensätzen (WHU‑RS19 und UCMerced) zeigen, dass MLIN durchweg höhere numerische Qualitätswerte und sichtbar schärfere Details liefert als mehrere führende Methoden für kontinuierliches Zoomen, sowohl bei vertrauten Zoomstufen als auch bei extremen Vergrößerungen bis zum Zehnfachen.
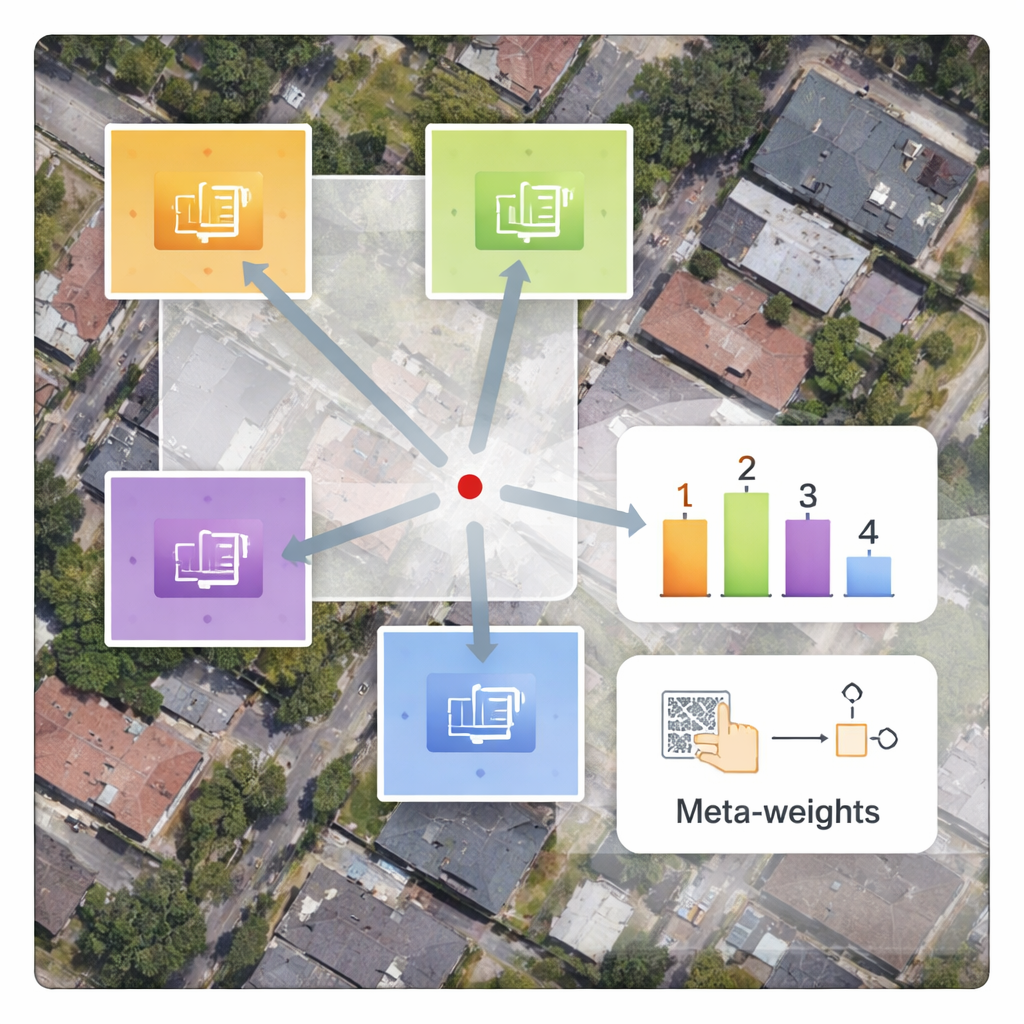
Schnelleres Training ohne zusätzlichen Zeitverlust
Ein praktischer Vorteil des Designs ist, dass nur der neue Decoder und das Meta‑Gewichtsnetz auf Satellitenbildern trainiert werden müssen, während der große Encoder unverändert bleibt. Das reduziert die Trainingszeit erheblich im Vergleich zu Methoden, die alle Parameter von Grund auf neu trainieren. Obwohl das Meta‑Netz zusätzliche Rechenarbeit einführt, bewältigen moderne Grafikprozessoren diese Operationen effizient, sodass die Verarbeitungszeit für ein einzelnes Bild nahezu mit bestehenden Ansätzen vergleichbar bleibt. Ablationsstudien — sorgfältige Tests, bei denen Teile des Systems entfernt oder vereinfacht werden — bestätigen, dass die inhaltsbewusste Gewichtung die zentrale Komponente ist, die sowohl Kantenschärfe als auch Texturkontinuität verbessert.
Deutlichere Augen für die Erde
Einfach ausgedrückt zeigt diese Arbeit, wie leistungsfähige Bildmodelle, die auf Alltagsfotos trainiert wurden, wiederverwendet und intelligent an die sehr unterschiedliche Welt der Satellitenbildgebung angepasst werden können. Indem das System lernt, Informationen benachbarter Pixel basierend auf dem tatsächlichen Szeneninhalt auszubalancieren, erzeugt MLIN klarere, verlässlichere Satellitenbilder für jede Zoomstufe mit nur einem Modell. Das bedeutet bessere Werkzeuge für Wissenschaftler, Planer und Rettungskräfte, die auf detaillierte Ansichten unseres Planeten angewiesen sind — und das bei überschaubarem Rechen- und Speicheraufwand.
Zitation: Zhang, Q., Ma, S., Tang, Y. et al. Cross-domain continuous-scale remote sensing image super-resolution via meta-weight learning. Sci Rep 16, 6073 (2026). https://doi.org/10.1038/s41598-026-36632-w
Schlüsselwörter: Satelliten-Superauflösung, Fernerkundungsbilder, Meta-Lernen, Beliebiger-Skalierungsfaktor, Bildverbesserung