Clear Sky Science · de
Multitask‑Optimierung und Konvergenzstabilität mit hierarchischem Feature‑Learning für selbstgesteuerte Optimierung
Klügere KI, die mehrere Aufgaben gleichzeitig meistern kann
Moderne Anwendungen bauen zunehmend auf künstlicher Intelligenz auf, die mehrere Dinge zugleich tun muss – etwa Bilder und Text gemeinsam verstehen, medizinische Entscheidungen unterstützen oder Fahrzeugen helfen, die Straße wahrzunehmen. Wenn ein KI‑Modell jedoch zu viele Fähigkeiten gleichzeitig lernt, kann das Training instabil werden und die Fähigkeiten sich gegenseitig stören. Diese Arbeit stellt ein neues Deep‑Learning‑Framework vor, die Unified Multitask and Multiview Deep Architecture (UMDA), das einem Modell erlaubt, aus vielen Datentypen zu lernen und zahlreiche Aufgaben zu lösen, ohne durcheinander zu geraten oder instabil zu werden.
Warum heuteige Multi‑Skill‑KI oft Probleme hat
Die meisten aktuellen Systeme, die mehrere Aufgaben lernen (Multitask‑Lernen) oder verschiedene Datentypen wie Bilder und Text kombinieren (Multiview‑Lernen), leiden unter drei großen Problemen. Erstens können sich unterschiedliche Aufgaben während des Trainings gegenseitig behindern: Verbesserungen bei einer Aufgabe können unbemerkt eine andere verschlechtern, ein Phänomen, das als negative Transfer bekannt ist. Zweitens geht beim bloßen Stapeln oder Mitteln von Informationen aus verschiedenen Quellen oft subtile, aber wichtige Beziehungen zwischen ihnen verloren. Drittens kann der Trainingsprozess selbst wackelig werden, mit großen Schwankungen in den Richtungen, in die die Modellparameter aktualisiert werden. Diese Probleme sind besonders gravierend in realen Einsatzszenarien wie Diagnostik oder industrieller Inspektion, wo die Daten komplex sind und Entscheidungen verlässlich sein müssen.
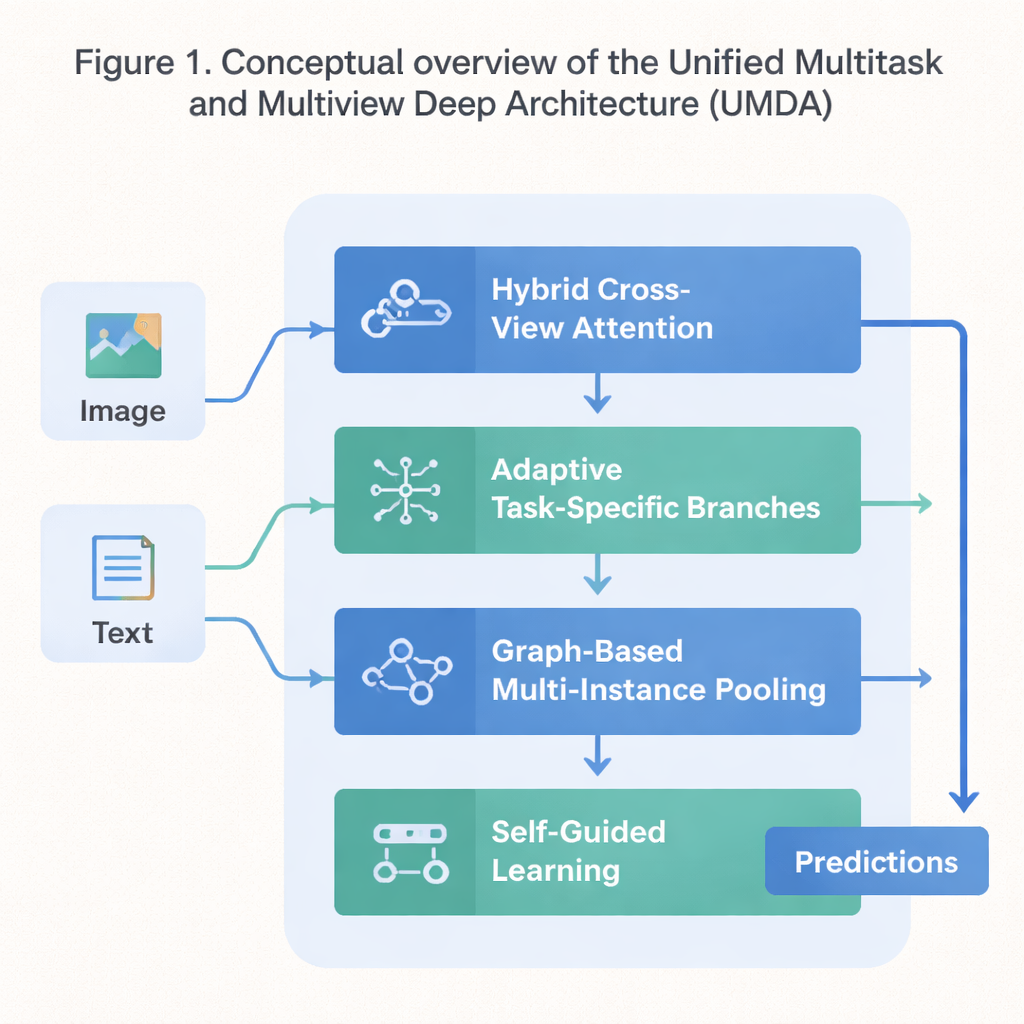
Ein vierteiliger Plan für kooperatives Lernen
UMDA begegnet diesen Schwächen, indem es den Lernprozess in vier eng verzahnte Teile gliedert, die Informationen auf kontrollierte Weise teilen. Der erste Teil, Hybrid Cross‑View Attention, betrachtet verschiedene Sichten derselben Daten – etwa Text und Bilder zu einem Film – und lernt, welche Sicht in welchem Schritt eine andere beeinflussen sollte. Er nutzt mathematische Methoden, die das Modell ermutigen, sich nicht zu stark auf eine einzelne Sicht zu stützen, jede Sicht unterscheidbar zu halten und zugleich für breite Übereinstimmung zu sorgen. Kurz gesagt: Er lehrt das Modell, auf alle seine ‚Sinne‘ zu hören, ohne dass einer die anderen übertönt.
Aufgaben unterscheiden, aber dennoch kooperativ bleiben
Der zweite Teil, Adaptive Task‑Specific Branching, trennt allgemeines Wissen, das viele Aufgaben teilen, von dem speziellen Wissen, das jede Aufgabe individuell benötigt. Anstatt alle Aufgaben gezwungenermaßen genau dieselben Merkmale nutzen zu lassen, baut UMDA getrennte „Zweige“ für jede Aufgabe auf, die über sorgfältig gewichtete Verbindungen dennoch miteinander kommunizieren können. Zusätzliche Strafterme in der Trainingszielsetzung drängen diese Zweige dazu, sich ausreichend zu unterscheiden, um zu spezialisieren, aber nicht so sehr, dass sie auseinanderdriften und die Kooperation abbrechen. Dieses Gleichgewicht hilft, schädliche Interferenzen zwischen Aufgaben zu reduzieren und gleichzeitig von den Erkenntnissen der anderen zu profitieren.
Struktur in Sammlungen von Beispielen erkennen
Viele reale Datensätze liegen als Sammlungen verwandter Elemente vor – zum Beispiel mehrere Bildausschnitte von einem medizinischen Präparat oder viele Frames eines Videos. Der dritte Teil von UMDA, Graph‑Based Multi‑Instance Pooling, modelliert explizit die Beziehungen zwischen diesen Elementen, indem er sie als Knoten in einem Netzwerk behandelt. Ähnliche Elemente werden verbunden, Informationen fließen entlang dieser Verbindungen, und die gesamte Sammlung wird anschließend in eine kompakte Repräsentation zusammengefasst. Zusätzliche Regularisierung bewegt nahe beieinander liegende Elemente dazu, miteinander übereinzustimmen, hält aber gleichzeitig genug Diversität aufrecht, sodass das Modell strukturelle Muster erfasst, die einfaches Mittelwertbilden übersehen würde.
Sich selbst justierendes Training für stetigen Fortschritt
Der abschließende Teil, Self‑Guided Learning, konzentriert sich auf den Trainingsprozess selbst statt auf die interne Architektur. Er misst kontinuierlich, wie stark und wie ähnlich die Trainingssignale jeder Aufgabe sind, und passt dann automatisch die Lernrate für jede Aufgabe an. Zudem werden die Gradienten geglättet und neu gewichtet – die Signale, die dem Modell sagen, wie es sich ändern soll –, sodass Aufgaben mit ähnlichen Zielen einander verstärken und Aufgaben, die in sehr unterschiedliche Richtungen ziehen, das Training nicht destabilisieren. In Tests an einem Standarddatensatz, der Filmplots und Poster mischt, erreichte UMDA eine höhere durchschnittliche Genauigkeit als ein Dutzend moderner Vergleichsverfahren, hielt die Beziehung zwischen den Sichten konsistenter und verringerte eine wichtige Maßzahl für Trainingsinstabilität um mehr als die Hälfte.
Was das für reale KI‑Systeme bedeutet
Für Nicht‑Spezialisten lautet die Kernbotschaft: UMDA bietet einen Weg, einzelne KI‑Modelle zuverlässiger zu bauen, die mehrere Datentypen und Ziele bewältigen können. Indem es dem Modell beibringt, wann Informationen geteilt und wann sie getrennt gehalten werden sollten, und indem es ihm erlaubt, sein Lernverhalten automatisch zu justieren, liefert das Framework bessere Vorhersagen, kohärentere interne Repräsentationen und ein glatteres Training. Das macht es zu einem vielversprechenden Baustein für zukünftige Systeme in der Medizin, im autonomen Fahren und in anderen komplexen Anwendungen, in denen KI viele Signale zugleich interpretieren muss, ohne das Gleichgewicht zu verlieren.
Zitation: Mahmood, K., Althobaiti, M.M., Hassan, M.U. et al. Multitask optimization and convergence stability with hierarchical feature learning for self guided optimization. Sci Rep 16, 6414 (2026). https://doi.org/10.1038/s41598-026-36622-y
Schlüsselwörter: Multitask‑Lernen, multimodale KI, Stabilität des Deep Learning, Aufmerksamkeitsnetzwerke, Graph‑Neuronale Netze