Clear Sky Science · de
Ein automatisiertes System zur Quran-Unterrichtung für Hörgeschädigte mittels Körperposenerkennung und Integration der arabischen Gebärdensprache
Ein heiliges Buch für stille Stimmen öffnen
Für viele gehörlose und schwerhörige Muslime ist das Erlernen der Rezitation des Qur’an oft ausgesprochen schwierig, weil der traditionelle Unterricht auf Hören und Nachsprechen basiert. Diese Studie stellt ein technologiegestütztes Lehrmittel vor, das arabische Gebärdensprachgesten "sieht" und sie mit Versen aus einem kurzen Kapitel des Qur’an verknüpft. Indem Körperbewegungen zu einer Brücke zwischen Gebärde und Schrift werden, soll religiöses Lernen inklusiver für Millionen von Menschen gemacht werden, die hauptsächlich über Gebärdensprache kommunizieren.
Warum hörgeschädigte Lernende ausgeschlossen werden
Gehörlose Muslime sind häufig auf Gestik und Gebärden angewiesen, doch die meisten Qur’an-Unterrichtsformen sind auf Klang aufgebaut – Lehrende rezitieren laut, Lernende imitieren Melodie und Aussprache. Familien beherrschen Gebärdensprache oft nicht gut, und qualifizierte Gebärdensprachdolmetscher sind insbesondere für religiöse Inhalte rar. Infolgedessen haben viele gehörlose Gläubige schlechteren Zugang zur spirituellen Bildung als ihre hörenden Mitmenschen. Jüngste Fortschritte in der Computer-Vision und künstlichen Intelligenz, die Hand- und Körperbewegungen aus Kamerabildern erkennen können, bieten einen Weg, dies zu ändern, indem sie Gebärdensprache in etwas verwandeln, das ein Computer in Echtzeit verstehen und darauf reagieren kann.
Gesten in lehrbare Einheiten verwandeln
Die Forschenden konzentrierten sich auf Sūrat al-Ikhlāṣ, ein kurzes, aber theologisch dichtes Kapitel, das viele Muslime früh erlernen. In Zusammenarbeit mit Einrichtungen, die gehörlose Nutzer in Ägypten betreuen, wurden 2.054 Bilder arabischer Gebärdensprachgesten aufgenommen, die einzelnen Qur’an-Wörtern dieses Kapitels entsprechen. Um Verwechslungen bezüglich Bedeutung und Aussprache zu vermeiden, wurde jede Geste sowohl in arabischer Schrift als auch in einem standardisierten Transliterationssystem beschriftet, das in der islamischen Wissenschaft weit verbreitet ist. Diese sorgfältige Kennzeichnung sorgt dafür, dass das System jede Gebärde dem richtigen Qur’an-Begriff zuordnet und gleichzeitig genügend Flexibilität behält, um künftig auf weitere Kapitel ausgeweitet zu werden.
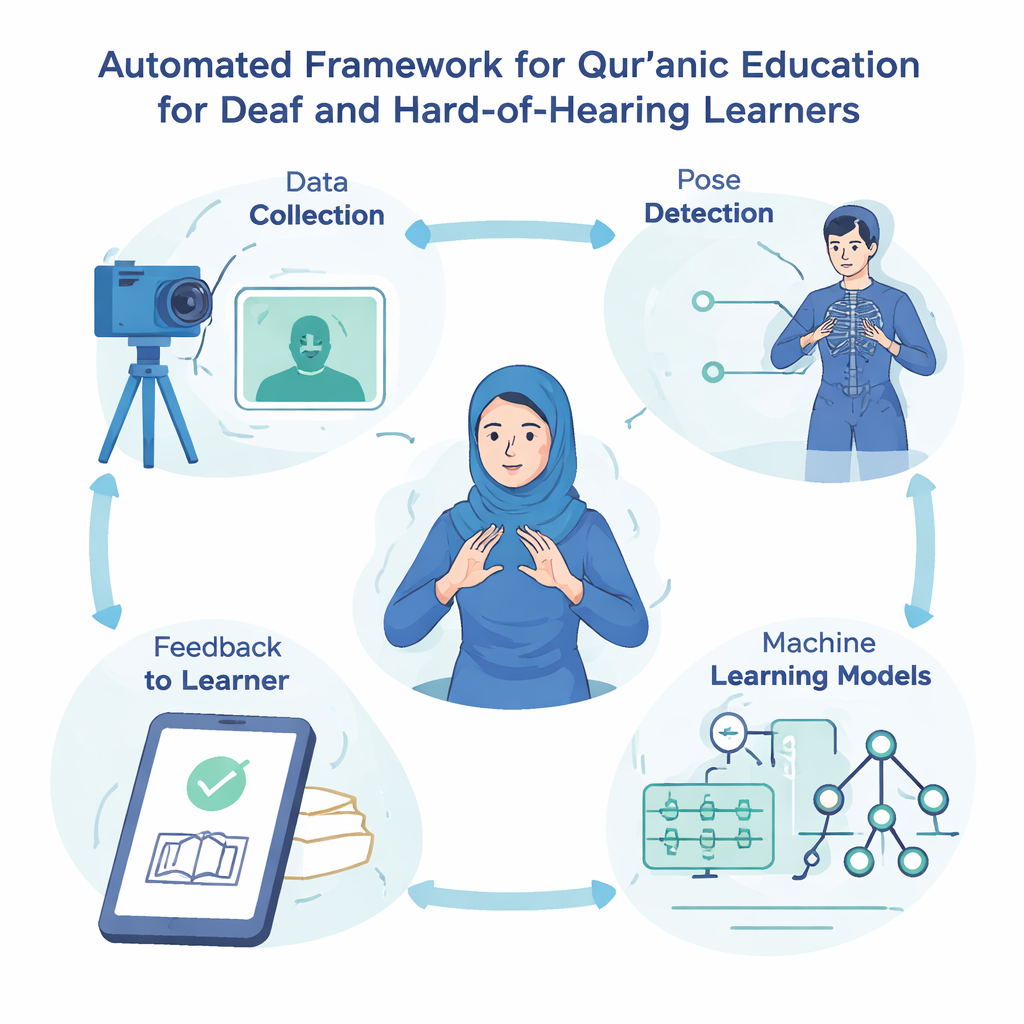
Wie der Computer lernende Gebetshaltungen erkennt
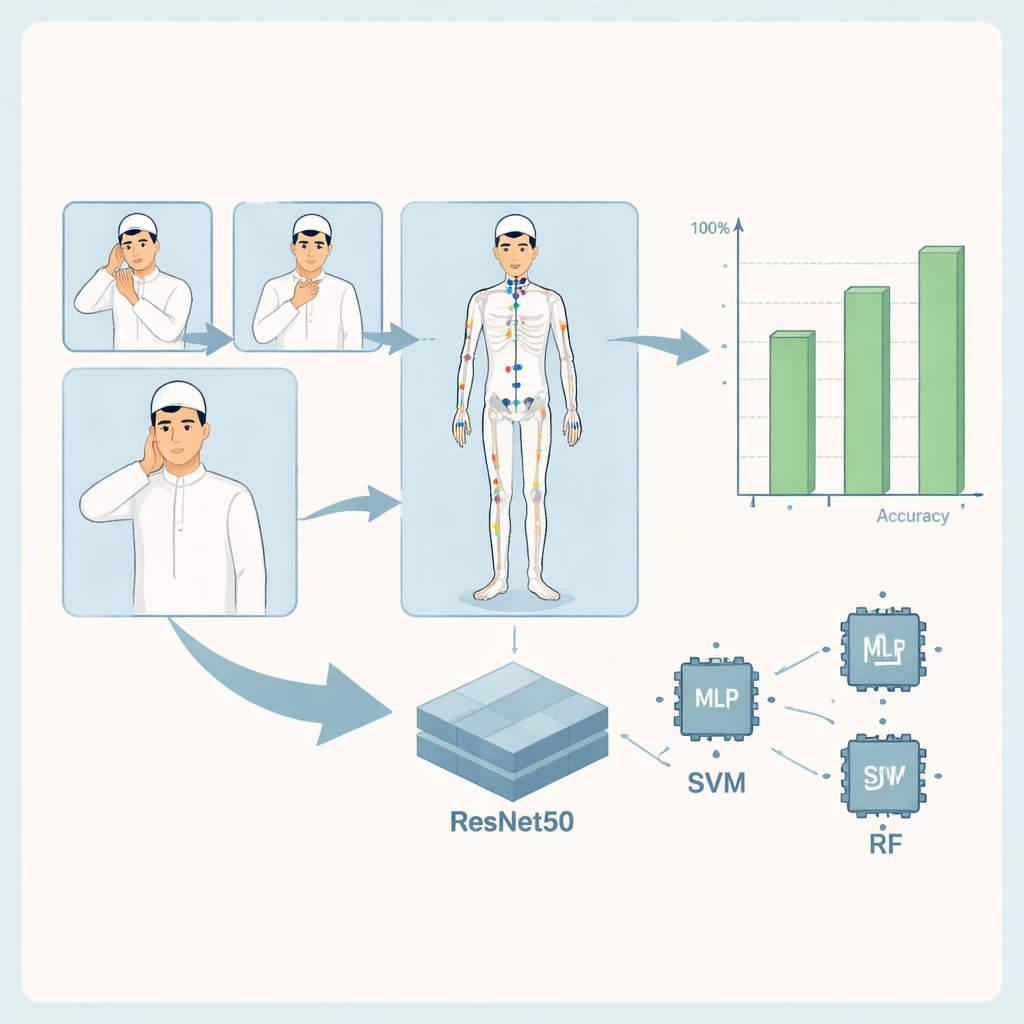
Kern des Systems ist eine visuelle Pipeline, die zunächst die Körperpose der gebärdenden Person detektiert und dann klassifiziert, welches Qur’an-Wort gezeigt wird. Alle Bilder werden auf ein Standardformat skaliert und bereinigt. Ein Softwaretool namens MediaPipe identifiziert 33 Schlüsselpunkte am Körper – etwa Schultern, Ellbogen und Handgelenke – und verfolgt ihre Positionen. Diese Koordinaten bilden eine komprimierte Beschreibung jeder Pose, die anschließend drei Arten von Machine-Learning-Modellen zugeführt wird: ein maßgeschneidertes Multi-Layer-Perceptron (ein einfaches neuronales Netz), eine Support-Vector-Machine und ein Random-Forest aus vielen kleinen Entscheidungsbäumen. Parallel dazu analysiert ein leistungsfähigeres Deep-Learning-Modell, ResNet50, das vollständige Bild, um detaillierte visuelle Muster zu erlernen, die mit jedem Wort verbunden sind.
Bemerkenswert genaue Erkennung von Qur’an-Gebärden
Zur Evaluation teilten die Autorinnen und Autoren ihren Datensatz in Trainings-, Validierungs- und Testmengen und prüften, wie genau die einzelnen Modelle die Gesten erkannten. Alle Ansätze zeigten starke Leistungen, wobei die posenbasierten Modelle die meisten Gebärden über 14–16 Qur’an-Wortklassen korrekt identifizierten. Das Random-Forest-Modell erzielte beispielsweise für viele Wörter nahezu perfekte Werte, mit nur wenigen Verwechslungen zwischen visuell ähnlichen Gesten. Das kombinierte ResNet50-basierte Modell, das die Bilder direkt betrachtet und gleichzeitig von Pose-Informationen profitiert, erreichte auf den Testdaten nahezu fehlerfreie Ergebnisse: Jede Geste wurde korrekt klassifiziert, und Standardmaße wie Genauigkeit, Precision, Recall sowie eine Trennfähigkeit gemessene ROC–AUC erreichten ihre Maximalwerte. Diese Ergebnisse deuten darauf hin, dass selbst relativ kleine Bildsammlungen, wenn sie sorgfältig vorbereitet sind, eine sehr präzise Erkennung religiöser Gebärdensprache ermöglichen können.
Versprechen, Grenzen und der weitere Weg
Obwohl die Leistungskennzahlen beeindruckend sind, betonen die Autorinnen und Autoren, dass sie nur für die kontrollierten Bedingungen ihrer Studie gelten: ein einzelnes Kapitel, eine begrenzte Anzahl von Gebärdenden und Standbilder statt kontinuierlicher Gebärdenbewegung. Für den Einsatz in der Praxis wären größere, vielfältigere Datensätze, eine bessere Erfassung von Unterkörperbewegungen und sorgfältige Tests mit Gebärdenden aus verschiedenen Regionen nötig. Nichtsdestotrotz zeigt die Arbeit, dass moderne Vision- und Lernwerkzeuge Qur’an-Gebärden zuverlässig erkennen und sofortiges Feedback geben können, etwa durch ein Häkchen oder eine korrigierende Animation, wenn eine Lernende oder ein Lernender eine Geste ausführt. Praktisch bedeutet das: Eine gehörlose Schülerin oder ein gehörloser Schüler könnte Qur’an-Verse vor einer einfachen Kamera üben und Anleitung erhalten, ohne einen Live-Dolmetscher zu benötigen – ein wichtiger Schritt, um heiliges Wissen für alle zugänglicher zu machen.
Zitation: AbdElghfar, H., Youness, H.A., Wahba, M. et al. An automated framework for qur’anic education of the hearing-impaired using body pose classification and Arabic sign language integration. Sci Rep 16, 5939 (2026). https://doi.org/10.1038/s41598-026-36578-z
Schlüsselwörter: Quran-Unterricht, Arabische Gebärdensprache, hörgeschädigte Lernende, Posenerkennung, assistive Technologie