Clear Sky Science · de
Ein hybrides ResNet50-Vision-Transformer-Modell mit Aufmerksamkeitsmechanismus zur Klassifikation von Luftbildern
Warum intelligentere Augen am Himmel wichtig sind
Luftaufnahmen von Drohnen und Satelliten steuern inzwischen die Katastrophenhilfe, Stadtplanung, Landwirtschaft und sogar die Verkehrssteuerung. Computern jedoch beizubringen, diese komplexen, überfüllten Blickwinkel von oben zu verstehen, ist weiterhin schwierig. Diese Studie stellt zwei neue KI-Modelle vor, die verschiedene Arten des „Sehens“ kombinieren, um zehn Objektklassen in Drohnenfotos—etwa Gebäude, Autos, Bäume und Straßen—mit besserer Genauigkeit als frühere Methoden zu erkennen. Der Ansatz könnte die automatisierte Überwachung aus der Luft schneller, zuverlässiger und leichter in realen Einsätzen einsetzbar machen.
Herausforderungen beim Blick von oben
Luftbilder unterscheiden sich von den Alltagsfotos, die wir mit unseren Handys machen. Objekte sind kleiner, können in ungewöhnlichen Winkeln erscheinen und liegen oft dicht beieinander. Ein teilweise von einem Baum verdecktes Auto, ein schmaler Fußweg oder Trümmerhaufen nach einem Erdrutsch sind selbst für Menschen nicht immer leicht zu erkennen. Dennoch verlassen sich Behörden, Einsatzteams und Umweltbehörden zunehmend auf Drohnen- und Satellitenbilder, um Überschwemmungen, Waldbrände, Stadtwachstum und Infrastrukturschäden zu verfolgen. Mit Tausenden von Satelliten im Orbit und einem boomenden Markt für Luftbildaufnahmen wächst das Datenvolumen zu schnell, als dass Menschen alles manuell sichten könnten, was den Bedarf an genaueren und effizienteren automatischen Klassifikationsverfahren erhöht.
Zwei Sehweisen des maschinellen Lernens verbinden
Die meisten erfolgreichen Bilderkennungssysteme basieren heute auf Deep Learning. Eine Familie, die Faltungsneuronen-Netzwerke, ist sehr gut darin, lokale Muster wie Kanten, Texturen und kleine Formen zu erfassen. Eine andere, neuere Familie, die sogenannten Vision Transformer, behandelt ein Bild wie eine Folge von Patches und ist besonders gut darin, langfristige Zusammenhänge zu erfassen—zum Beispiel wie eine Straße, eine Gruppe von Dächern und ein angrenzendes offenes Feld zusammen eine Szene bilden. Diese Arbeit kombiniert beides: ein bekanntes Faltungsmodell namens ResNet-50 und einen Vision Transformer. Beide verarbeiten dasselbe Luftbild und extrahieren jeweils eigene numerische Merkmalsrepräsentationen—kompakte Zusammenfassungen dessen, was das Netzwerk über die Szene gelernt hat. Diese beiden Informationsströme werden dann zusammengeführt und an ein Aufmerksamkeitsmodul übergeben, das lernt, welche Merkmale für die Entscheidung zwischen den zehn Zielklassen am wichtigsten sind.
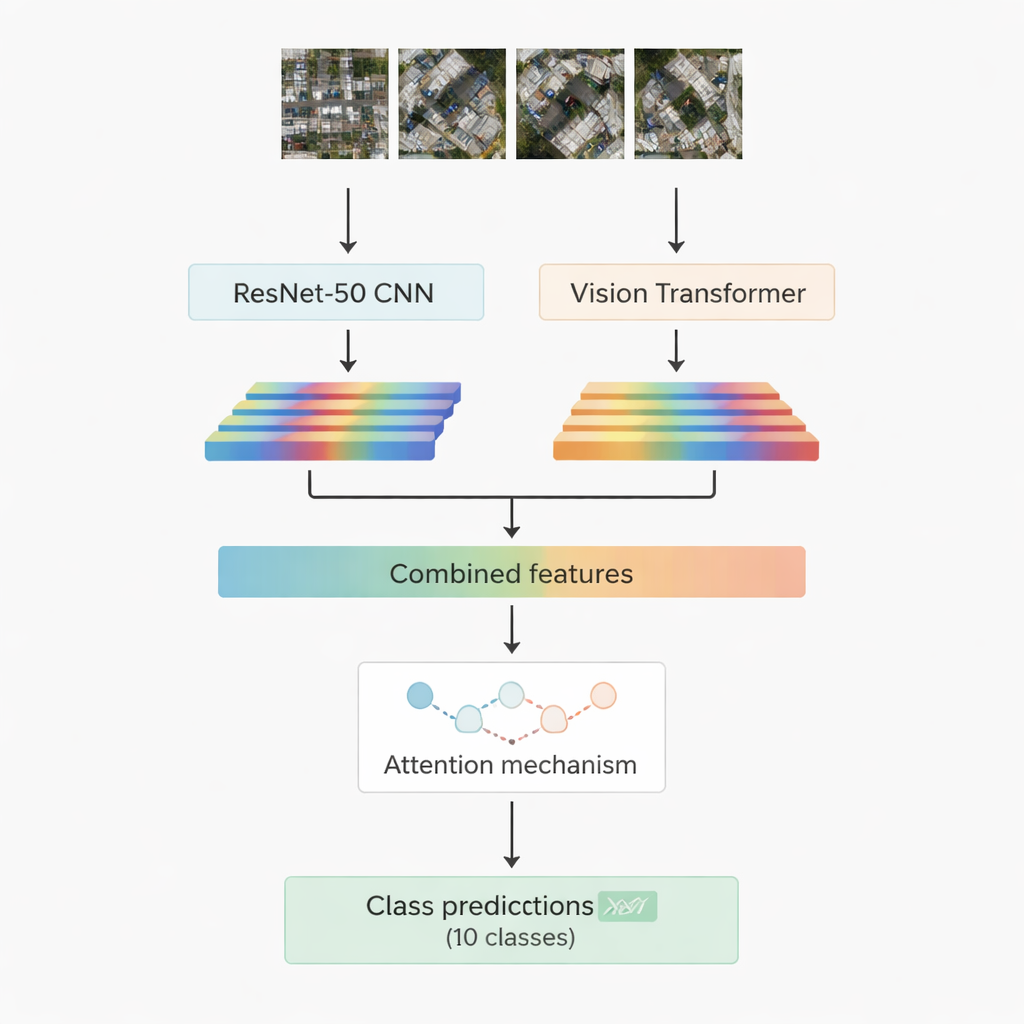
Zwei Aufmerksamkeitsstrategien, um sich auf das Wesentliche zu konzentrieren
Die Forschenden entwerfen und testen zwei Varianten ihres hybriden Systems. In der ersten Variante verbinden sie einfach die Merkmale von ResNet-50 und dem Transformer und führen sie in ein Multi-Head-Attention-Modul ein. Dieser Mechanismus lässt sich als viele kleine Scheinwerfer denken, die jeweils die Merkmale aus einem etwas anderen Blickwinkel betrachten und dann ihre Erkenntnisse kombinieren. In der zweiten Version nutzen sie Cross-Attention: Die Merkmale des Faltungsnetzwerks fungieren als Query, die die Transformer-Merkmale fragt, wo nachgesehen werden soll, wodurch ein Strom den anderen leiten kann. In beiden Fällen wird die Ausgabe der Attention durch Standardschichten geleitet, die schließlich das Bildpatch einer von zehn Klassen zuordnen, darunter Gebäude, Autos, Trümmer, Fußwege, Metallstraßen, offene Felder, Schatten, Panzer, Bäume und Dächer.
Test auf realen Drohnenbildern
Um die Leistung ihrer Modelle zu bewerten, verwenden die Autorinnen und Autoren einen öffentlichen Datensatz aus dem indischen Bundesstaat Sikkim, der mit einer Drohne in 60 bis 120 Metern Flughöhe aufgenommen wurde. Die Daten decken Flüsse, Wälder, Hügel und bebautes Gebiet ab und sind in kleine Patches unterteilt, sodass jedes Bild einer der zehn Kategorien zugeordnet werden kann. Der Datensatz ist ausgeglichen, mit gleicher Anzahl von Trainings- und Testbildern pro Klasse, was einen fairen Test ermöglicht. Die Forschenden trainieren beide Hybridmodelle unter identischen Bedingungen und vergleichen anschließend ihre Leistung mithilfe weit verbreiteter Metriken: Genauigkeit, Precision, Recall, F1-Score, Konfusionsmatrizen und ROC-Kurven. Außerdem stellen sie ihre Ergebnisse mehreren bekannten Netzen und neueren Transformer-basierten Methoden aus der aktuellen Literatur gegenüber.

Scharfere Klassifikation und Potenzial in der Praxis
Beide Hybridmodelle übertreffen frühere Systeme auf diesem Datensatz und erreichen Gesamtgenauigkeiten von 95,52 % bzw. 95,80 %, wobei die Multi-Head-Attention-Version leicht führt. Ihre Leistung bleibt über alle zehn Objektarten hinweg solide und stabil, und detaillierte Analysen zeigen, dass selbst die schwächeren Klassen noch mit hohen Raten erkannt werden. Das deutet darauf hin, dass die Kombination aus Faltungsnetzwerken, Vision Transformern und Aufmerksamkeitsmechanismen ein leistungsfähiges Rezept zum Verständnis komplexer Luftszenen ist. Für eine allgemeine Leserschaft lautet die Kernbotschaft: Computer werden deutlich besser darin, Fragen wie „Wo liegen die Straßen?“ oder „Welche Bereiche zeigen Trümmer oder Gebäude?“ in großen Sammlungen von Drohnenbildern zu beantworten. Wenn solche Modelle weiter verfeinert und auf neue Datensätze ausgeweitet werden, könnten sie eine Grundlage für intelligentere Katastrophenhilfe, Umweltüberwachung und Smart-City-Dienste bilden, die auf schnelle, verlässliche Interpretation von Bildern aus der Luft angewiesen sind.
Zitation: Aboghanem, A., Abd Elfattah, M., M. Amer, H. et al. A hybrid ResNet50-vision transformer model with an attention mechanism for aerial image classification. Sci Rep 16, 5940 (2026). https://doi.org/10.1038/s41598-026-36492-4
Schlüsselwörter: Klassifikation von Luftbildern, Drohnenaufnahmen, Tiefes Lernen, Vision Transformer, Fernerkundung