Clear Sky Science · de
Optimierte auf Aufmerksamkeit basierende kaskadierte Shuffle-Langzeit‑Abhängigkeitsnetzwerk‑Leistungsanalyse des adaptiven E‑Learnings unter IT‑Fachkräften
Intelligenteres Online‑Training für berufstätige Tech‑Profis
Für viele Fachkräfte der Informationstechnik (IT) sind Online‑Kurse inzwischen die Hauptmöglichkeit, ihre Fähigkeiten auf dem neuesten Stand zu halten. Die meisten Schulungsplattformen bewerten Lernende jedoch noch mit groben Instrumenten wie Quiz‑Summen oder Abschlussabzeichen. Diese Studie stellt einen schlaueren Weg vor, die digitalen „Spuren“, die Lernende hinterlassen, zu interpretieren und in präzise, Echtzeit‑Einsichten darüber zu verwandeln, wie gut jede Person tatsächlich lernt.
Warum Einheitslösungen bei Online‑Kursen nicht ausreichen
Klassisches E‑Learning behandelt die meisten Lernenden gleich: alle sehen dieselben Module, absolvieren dieselben Prüfungen und werden mit denselben festen Tests beurteilt. Dieser Ansatz ignoriert, wie unterschiedlich Fachkräfte vorankommen, besonders in schnelllebigen Bereichen wie Cybersicherheit oder Cloud‑Computing. Frühere Forschungen versuchten, dies mit maschinellem Lernen zu beheben — indem sie Quiz‑Punkte, aufgewendete Zeit und Klickdaten kombinierten, um Erfolg vorherzusagen — doch viele Modelle hatten Probleme mit verrauschten oder unvollständigen Daten, konnten nicht auf realistische Plattformen skaliert werden oder erfassten nicht, wie sich Lernen über Wochen und Monate entwickelt. Das Ergebnis waren oft verzögerte, grobe Rückmeldungen, die sich nicht leicht zur Steuerung individualisierter Inhalte oder rechtzeitiger Interventionen eigneten.
Rohe Kursprotokolle in saubere, faire Daten verwandeln
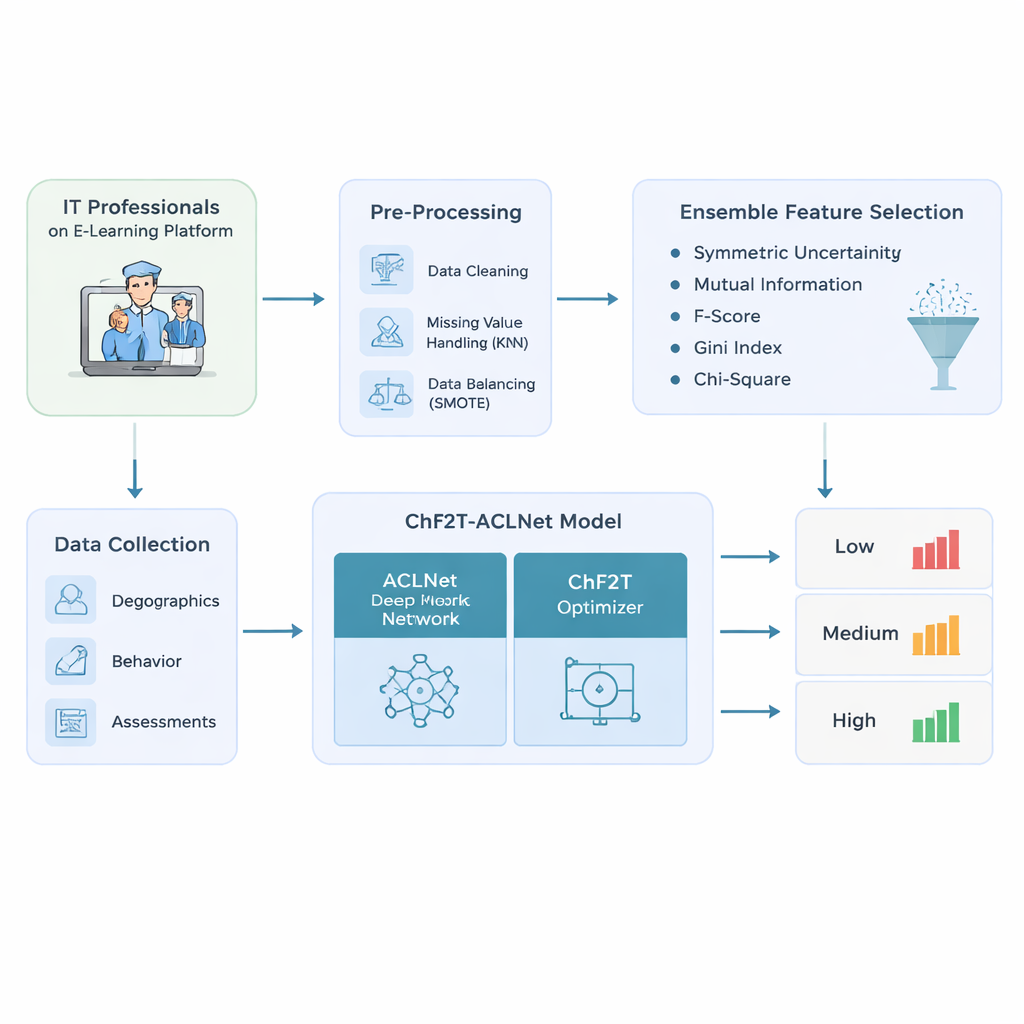
Die Autoren beginnen mit dem Entwurf einer sorgfältigen Datenpipeline für IT‑Fachkräfte, die adaptive E‑Learning‑Plattformen nutzen. Sie sammeln eine reichhaltige Mischung an Informationen: grundlegende Profildaten wie Alter und Berufsrolle; Verhaltensspuren wie aufgewendete Zeit, Zugriffsdatumsangaben und aktive Tage; sowie Leistungsindikatoren einschließlich Quiz‑Ergebnissen, Versuchen, Zertifikaten und Feedback‑Bewertungen. Bevor irgendein Modell angewendet wird, säubern sie die Daten — entfernen doppelte Einträge, schätzen fehlende Werte durch Betrachtung ähnlicher Lernender und korrigieren verzerrte Klassenverteilungen, sodass Niedrig‑, Mittel‑ und Hochleister fairer vertreten sind. Dieser Ausgleichsschritt verhindert Modelle, die nur für die häufigsten „Durchschnitts“‑Lernenden übermäßig zuversichtlich sind und jene übersehen, die Schwierigkeiten haben oder besonders gute Leistungen zeigen.
Nur die aussagekräftigsten Signale auswählen
Aus dem bereinigten Datensatz füttert das System nicht einfach jede verfügbare Spalte in eine Blackbox. Stattdessen verwendet es ein Ensemble aus fünf einfachen Ranglistenverfahren, um zu entscheiden, welche Merkmale wirklich wichtig für die Vorhersage von Lernergebnissen sind. Jede Methode untersucht die Verbindung zwischen einem Kandidatenmerkmal — etwa Anzahl der Quiz‑Versuche oder aufgewendeter Zeit — und dem finalen Leistungslabel. Durch die Kombination ihrer Ranglisten mittels eines Medianwerts filtert der Ansatz verrauschte oder redundante Signale heraus und behält nur die informativsten. Das reduziert nicht nur den Rechenaufwand für das folgende Modell, sondern hilft ihm auch, sich auf Muster zu konzentrieren, die niedrig, mittel und hoch Leistende sinnvoll unterscheiden.
Ein hybrides Netzwerk, trainiert wie ein Sportteam
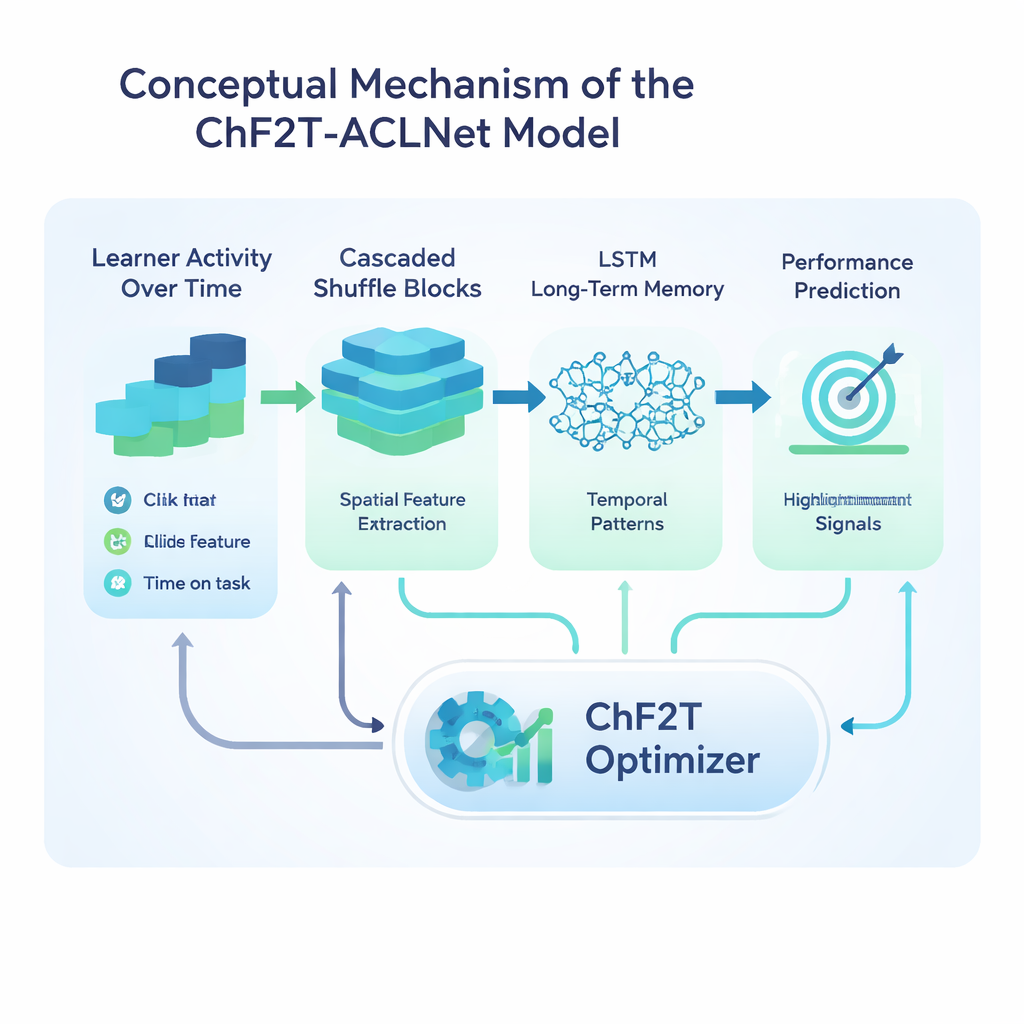
Das Herzstück der Studie ist ein hybrides Deep‑Learning‑Modell namens ACLNet, gekoppelt mit einer unkonventionellen Trainingsstrategie, die von Teamsportarten inspiriert ist. ACLNet verwendet zunächst leichte „Shuffle“‑Blöcke, um Eingabesignale effizient zu komprimieren und zu vermischen, und führt sie dann einem Speichermodul zu, das nachzeichnet, wie sich das Verhalten eines Lernenden über die Zeit verändert. Eine Aufmerksamkeits‑Schicht hebt die einflussreichsten Kanäle hervor — etwa plötzliche Aktivitätsabbrüche oder konstant hohe Quiz‑Ergebnisse — bevor eine finale Vorhersage der Leistungs‑Kategorie des Lernenden getroffen wird. Um die vielen internen Einstellungen dieses Netzes zu optimieren, führen die Autoren einen Chaotic Football Team Training (ChF2T) Algorithmus ein. Hier erkunden virtuelle „Spieler“ verschiedene Parameterkonfigurationen, imitieren starke Performer, meiden schwache und führen gelegentlich große, chaotische Sprünge aus, die der Suche helfen, aus schlechten lokalen Lösungen zu entkommen. Diese Mischung aus Struktur und kontrollierter Zufälligkeit beschleunigt die Konvergenz und verringert Overfitting.
Wie gut das System in der Praxis funktioniert
Die Forscher testen ihre Pipeline an einem synthetischen, aber realistischen Datensatz von 1.200 IT‑Fachkräften, der reale Learning‑Management‑System‑Aufzeichnungen mit absichtlich ungleichmäßigen Klassenverteilungen nachbildet. Sie vergleichen ihr ChF2T‑ACLNet‑Modell mit mehreren starken Baselines, darunter föderierte Lernkonfigurationen, fortgeschrittene bild‑ähnliche Netze, die für Bildung adaptiert wurden, sowie andere tiefe oder Ensemble‑Modelle. In mehreren Cross‑Validation‑Setups erreicht die vorgeschlagene Methode etwa 98,9 % Genauigkeit, mit ähnlich hohen Werten für Präzision, Recall und F‑Scores. Sie erzielt außerdem eine nahezu perfekte Übereinstimmungsrate, die Zufallseffekte korrigiert, und starke AUC‑Werte, was bedeutet, dass sie Leistungsniveaus über viele Schwellenwerte zuverlässig trennt. Trotz ihrer Komplexität läuft das System schneller als konkurrierende Ansätze, dank sorgfältiger Merkmalsauswahl, effizientem Netzwerkdesign und der schnellen Konvergenz des Optimierers.
Was das für das alltägliche Online‑Lernen bedeutet
Einfach ausgedrückt zeigt diese Arbeit, dass es möglich ist, zu beobachten, wie Fachkräfte durch Online‑Kurse navigieren, und mit hoher Sicherheit abzuleiten, wer Schwierigkeiten hat, wer sich nur durchwurstelt und wer den Stoff wirklich beherrscht — ohne auf eine Abschlussprüfung warten zu müssen. Ein solches System könnte frühzeitige Hinweise auslösen, andere Übungen empfehlen oder Mentoren lange bevor ein Lernender zurückfällt benachrichtigen. Die Autoren nennen verbleibende Herausforderungen, darunter die Skalierung auf sehr große Plattformen, die Anpassung an schnell wechselnde Kursdesigns und die Erklärbarkeit der Modellentscheidungen. Dennoch ist ihr Ansatz ein starker Schritt hin zu E‑Learning‑Systemen, die eher wie aufmerksame persönliche Coaches als wie statische digitale Lehrbücher agieren.
Zitation: Yuvapriya, P., Subramanian, P. & Surendran, R. Optimized attention-based cascaded shuffle long-term dependent network based performance analysis of adaptive e-learning among IT professionals. Sci Rep 16, 6245 (2026). https://doi.org/10.1038/s41598-026-36470-w
Schlüsselwörter: adaptives E‑Learning, Lernanalyse, Deep Learning, IT‑Fachkraft‑Schulung, Vorhersage der Studienleistung