Clear Sky Science · de
Eine Methode zur Entitätendisambiguierung für Kurztexte basierend auf dem BERT‑Modell und dem kürzesten‑Pfad‑Algorithmus
Warum das Auflösen verwirrender Namen wichtig ist
Jeden Tag suchen, scrollen und chatten wir mit kurzen, oft unordentlichen Textfetzen – Tweets, Suchanfragen, Chatnachrichten. Diese Textschnipsel enthalten Namen von Personen, Orten, Firmen und Dingen, die mehr als eine Bedeutung haben können, etwa „Apple“ als Frucht oder „Apple“ als Unternehmen. Computer müssen erraten, welche Bedeutung wir meinen, und wenn sie falsch liegen, werden Suchergebnisse, Empfehlungen und Online‑Dienste deutlich weniger nützlich. Dieses Papier stellt einen neuen Ansatz vor, der Maschinen dabei hilft, solche mehrdeutigen Namen in Kurztexten korrekt zu interpretieren, insbesondere in chinesischen sozialen Medien und Suchanfragen, indem moderne Sprachmodelle mit einem durchdachten Graphalgorithmus kombiniert werden.
Von unklaren Kurztexten zu eindeutigen Zielen
Kurztexte sind für Computer überraschend schwer zu verstehen. Im Gegensatz zu langen Artikeln liefern sie sehr wenig Kontext und sind voller Slang, Abkürzungen und unvollständiger Sätze. Traditionelle Methoden versuchten, einen Namen im Text mit Einträgen in einer Wissensbasis abzugleichen oder nutzten handgefertigte Regeln und einfachere Machine‑Learning‑Modelle. Diese Ansätze behandeln Wörter oft so, als hätten sie eine einzige feste Bedeutung, was versagt, wenn dasselbe Wort je nach Verwendung einen Berufstitel, ein Unternehmen oder einen Song bezeichnen kann. Das Ergebnis sind häufige Verwechslungen darüber, auf welche reale Entität ein Wort in einem Tweet oder einer Suchanfrage tatsächlich verweist.
Das System beibringen, mehrdeutige Namen zu erkennen
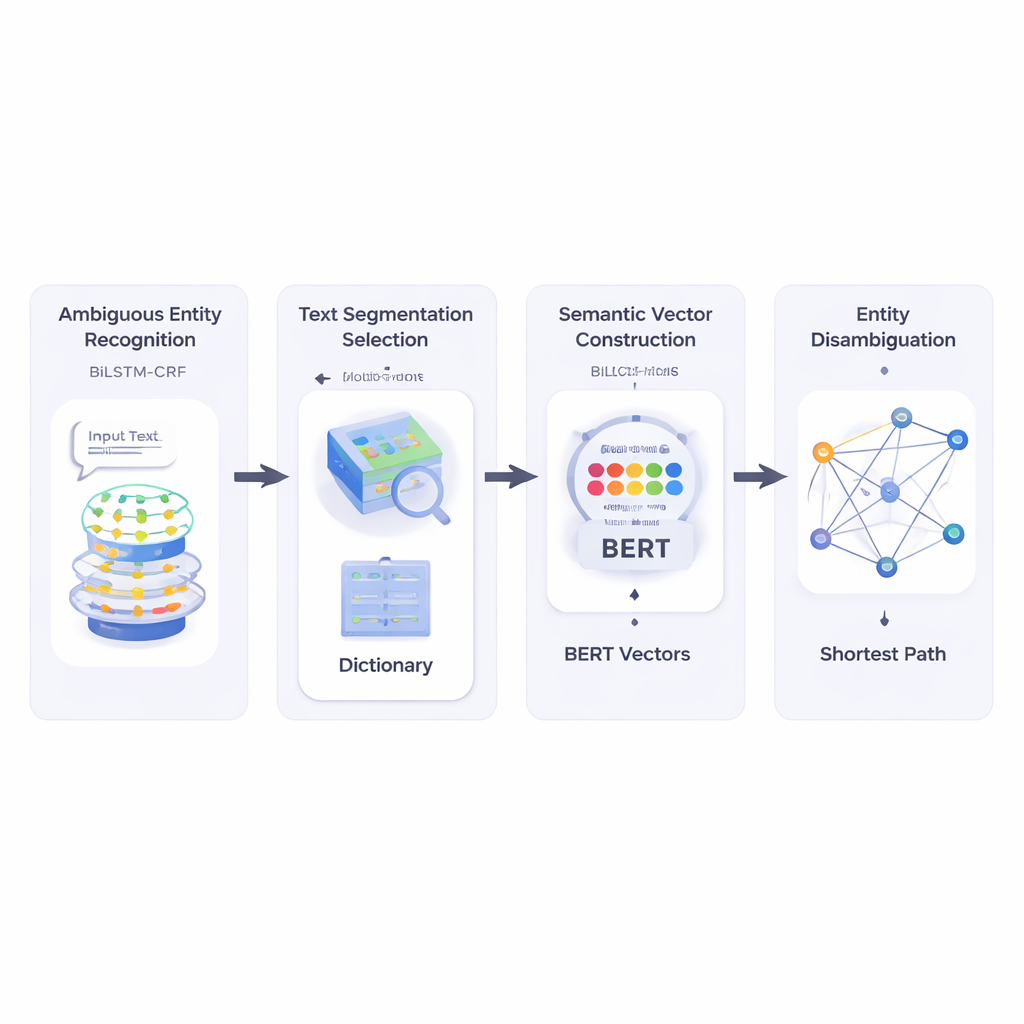
Die Autoren bauen zunächst ein System, das einen Kurztext liest und identifiziert, welche Teile Entitätsnamen sind und welche davon möglicherweise mehrdeutig sind. Sie verwenden eine neuronale Kombination namens BiLSTM‑CRF, die gut darin ist, Wortsequenzen zu taggen, weil sie sowohl linken als auch rechten Kontext berücksichtigt. Sobald potenzielle Entitäten markiert sind, konsultiert das System eine große lexikalische Ressource namens HowNet. Wenn HowNet mehrere Bedeutungen für ein Wort aufführt, wird dieses Wort als mehrdeutig markiert; gibt es nur eine Bedeutung, gilt das Wort als bereits klar. Dieser Schritt liefert eine fokussierte Liste von Namen, die tatsächlich einer Disambiguierung bedürfen.
Bedeutungen in Punkte im Raum verwandeln
Als Nächstes zerlegt die Methode den Kurztext in mögliche Wortsegmente und wählt die beste Segmentierung, indem sie prüft, wie gut jeder mögliche Schnitt in der Bedeutung mit klar verstandenen Referenzwörtern im gleichen Satz übereinstimmt. Zur Messung nutzen die Autoren BERT, ein leistungsfähiges vortrainiertes Sprachmodell, das für jede Wortverwendung einen numerischen „semantischen Vektor“ erzeugt, der die kontextabhängige Bedeutung einfängt. Durch Berechnung der Kosinusähnlichkeit zwischen diesen Vektoren findet das System die Segmentierung, deren Teile semantisch am kompatibelsten mit den unmissverständlichen Referenzbegriffen sind. So kann das Modell jede mögliche Bedeutung jedes Wortes als Punkt in einem mehrdimensionalen Raum darstellen.
Den kürzesten Weg zur richtigen Bedeutung finden
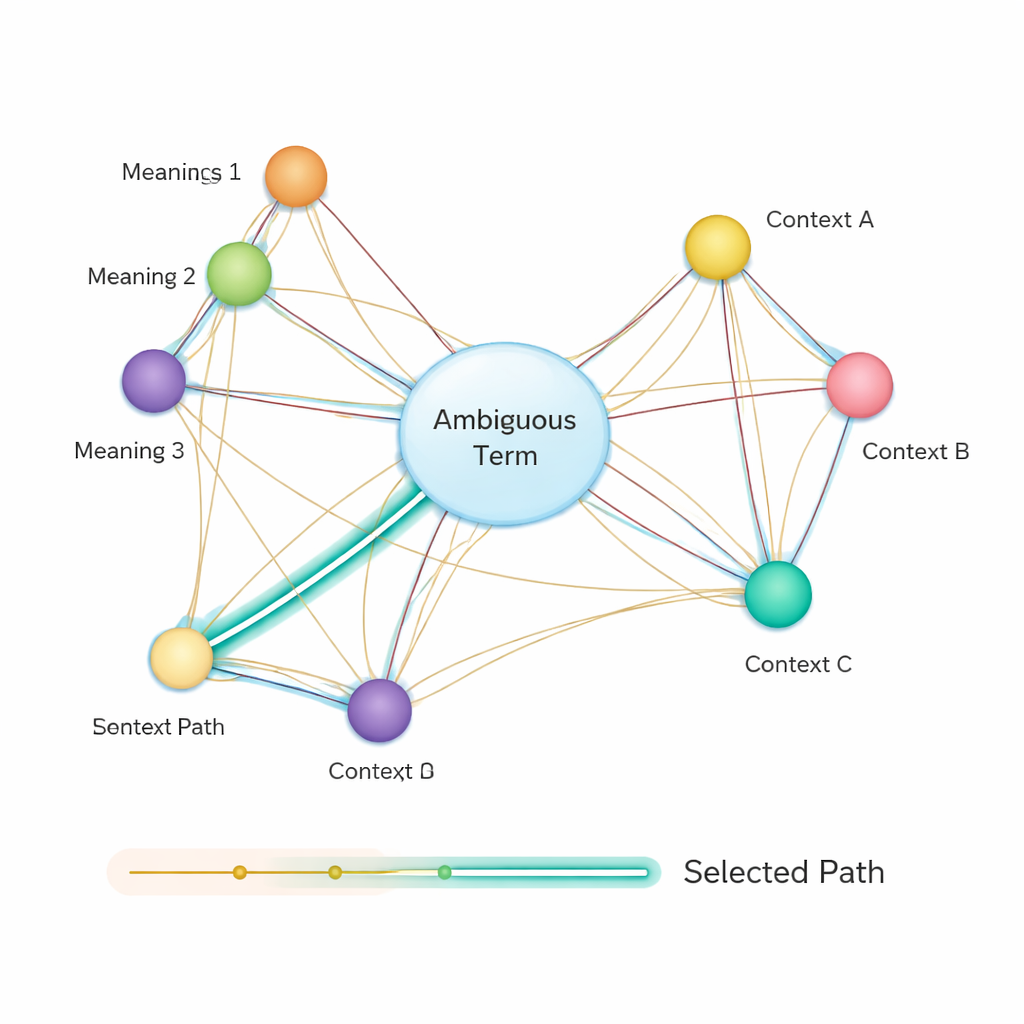
Danach baut die Methode ein semantisches Netzwerk: einen Graphen, in dem jede mögliche Bedeutung jedes Begriffs ein Knoten ist und Kanten Bedeutungen verbinden, die im selben Satz gemeinsam auftreten könnten. Die Stärke jeder Kante basiert darauf, wie ähnlich die Bedeutungen sind, wiederum unter Verwendung der BERT‑basierten Vektoren. Um zu entscheiden, welche Bedeutung eines mehrdeutigen Wortes am besten zum Satz passt, wenden die Autoren einen klassischen Algorithmus an: Dijkstras Algorithmus für kürzeste Wege. Anschaulich sucht das System nach dem Pfad durch diesen Bedeutungsgraphen, der die gesamte semantische „Distanz“ so klein wie möglich hält. Der gewählte Pfad entspricht einer konsistenten Interpretation aller Begriffe, und die Bedeutung der mehrdeutigen Entität, die auf diesem Pfad liegt, wird als endgültige Antwort ausgewählt.
Wie viel besser funktioniert das?
Die Forscher testeten ihre Methode an einem öffentlichen chinesischen Datensatz aus dem CLUE‑Benchmark, der reale Kurztext‑Szenarien wie Social‑Media‑Posts und Suchanfragen simuliert. Sie verglichen vier Ansätze: Versionen mit traditionellen Word2Vec‑Einbettungen, dem Sprachmodell ELMo, einem BERT‑basierten System ohne den kürzesten‑Pfad‑Schritt und ihrer vollständigen BiLSTM‑CRF‑BERT‑SPA‑Pipeline. Über Tausende von Texten verbesserte ihre komplette Methode Genauigkeit, Recall und F1‑Score im Durchschnitt um etwa ein Viertel im Vergleich zu den anderen. Praktisch bedeutet das: Das System erkannte korrekte Entitäten besser und tat dies konsistenter über verschiedene Datengrößen hinweg.
Was das für Alltags‑Technologie bedeutet
Für Nicht‑Spezialisten ist die Schlussfolgerung einfach: Durch die Kombination eines leistungsfähigen Sprachverständnismodells (BERT) mit einer graphbasierten Suche nach dem kürzesten Pfad geben die Autoren Computern eine verlässlichere Methode, um zu entscheiden, worauf sich ein mehrdeutiger Name in kurzen, verrauschten Texten tatsächlich bezieht. Das kann Suchmaschinen intelligenter machen, sozialen Plattformen helfen, Beiträge besser zu verstehen, und nachgelagerte Werkzeuge wie Empfehlungssysteme und Wissensgraphen verbessern. Obwohl die Methode derzeit auf Chinesisch ausgerichtet ist und noch Spielraum für Effizienzverbesserungen bietet, zeigt sie, wie die Verbindung moderner KI mit klassischen Algorithmen Verwirrung bei der maschinellen Interpretation unserer Alltagssprache deutlich reduzieren kann.
Zitation: Liu, X., Zhang, D., Xiao, T. et al. A short text entity disambiguation method based on BERT model and shortest path algorithm. Sci Rep 16, 5720 (2026). https://doi.org/10.1038/s41598-026-36411-7
Schlüsselwörter: Entitätendisambiguierung, Kurztext, BERT, Wissensgraph, Verarbeitung natürlicher Sprache