Clear Sky Science · de
Entkopplung von Inhalt und Stil für multimodale Bildgenerierung mit latenter Diffusionsarchitektur
Warum intelligentere Bildstile wichtig sind
Von Filmplakaten und Spielgrafiken bis zu Social‑Media‑Filtern erwarten wir zunehmend, dass Bilder sowohl visuell auffällig als auch stark personalisiert sind. Im Hintergrund kämpfen viele Stil‑Transfer‑Systeme jedoch noch: Sie können Gesichter verformen, Gebäude in ihrer Form verändern oder viel Hardware erfordern. Dieses Papier stellt ein neues KI‑Modell vor, das reichhaltigere künstlerische Stile verspricht, dabei das Originalbild intakt lässt und effizient genug läuft, um auf Alltagsgeräten einsetzbar zu sein.
„Was es ist“ von „wie es aussieht“ trennen
Im Kern dieser Arbeit steht ein Modell namens Dual‑Condition Lightweight Style Diffusion Model (DCLSDM). Die zentrale Idee ist, den Bildinhalt — also Objekte, Anordnung und Szene — als einen „Kanal“ zu behandeln und die künstlerische Behandlung — Farben, Texturen, Pinselstriche — als einen anderen, und beide unabhängig steuerbar zu machen. Statt ein einzelnes Netzwerk diese beiden Aspekte zusammenmischen zu lassen, verwendet DCLSDM zwei getrennte Pfade: einen für den Inhalt und einen für den Stil. Der Inhaltsweg konzentriert sich darauf, Formen und Bedeutungen in einem Eingabebild oder einer Textbeschreibung zu erfassen, während der Stilweg die visuelle Charakteristik eines gewählten Kunstwerks oder einer Stilbeschreibung lernt.
Wie das neue Modell aufgebaut ist
DCLSDM baut auf Diffusionsmodellen auf, derselben Modellfamilie, die viele moderne Bildgeneratoren antreibt. Anstatt direkt mit Bildern in voller Auflösung zu arbeiten, operiert es in einem komprimierten „latenten“ Raum, der deutlich effizienter ist. Ein Modul namens Perceiver IO extrahiert den Inhalt: Es nimmt ein Bild oder eine Bildunterschrift auf und destilliert die Geometrie und Semantik der Szene in eine kompakte Repräsentation. Ein separates Stilmodul liest ein oder mehrere Stilbilder oder Textangaben und wandelt sie in Stil‑Feature‑Vektoren um. Diese Stil‑Features lassen sich mit einem gewichteten Interpolationsschema mischen, sodass sanfte Übergänge zwischen beispielsweise einem impressionistischen und einem minimalistischen Look möglich sind, ohne das übliche „matschige“ Mittelmaß.
Struktur bewahren, Stil ändern
Innerhalb des Diffusionsnetzwerks, das tatsächlich das Bild generiert, werden die beiden Informationsarten über unabhängige Wege eingespeist. Inhaltssignale lenken die Netzwerkschichten, die für Struktur zuständig sind — also wo Kanten, Objekte und Layouts platziert werden sollen. Stilsignale werden über dedizierte Attention‑Schichten eingespeist, die hauptsächlich Texturen, Farben und Pinselduktus formen. Darüber hinaus fügt eine Komponente namens ControlNet zusätzliche strukturelle Führung hinzu, indem sie Kantensowie Tiefenkarten aus dem ursprünglichen Inhalt extrahiert. Diese Kombination erlaubt es dem System, eine Sommerlandschaft in eine Winterpalette umzusetzen oder ein Foto im Stil von Van Gogh zu rendern, während Berge, Bäume und Gebäude an der richtigen Stelle bleiben und nicht verzerrt werden.
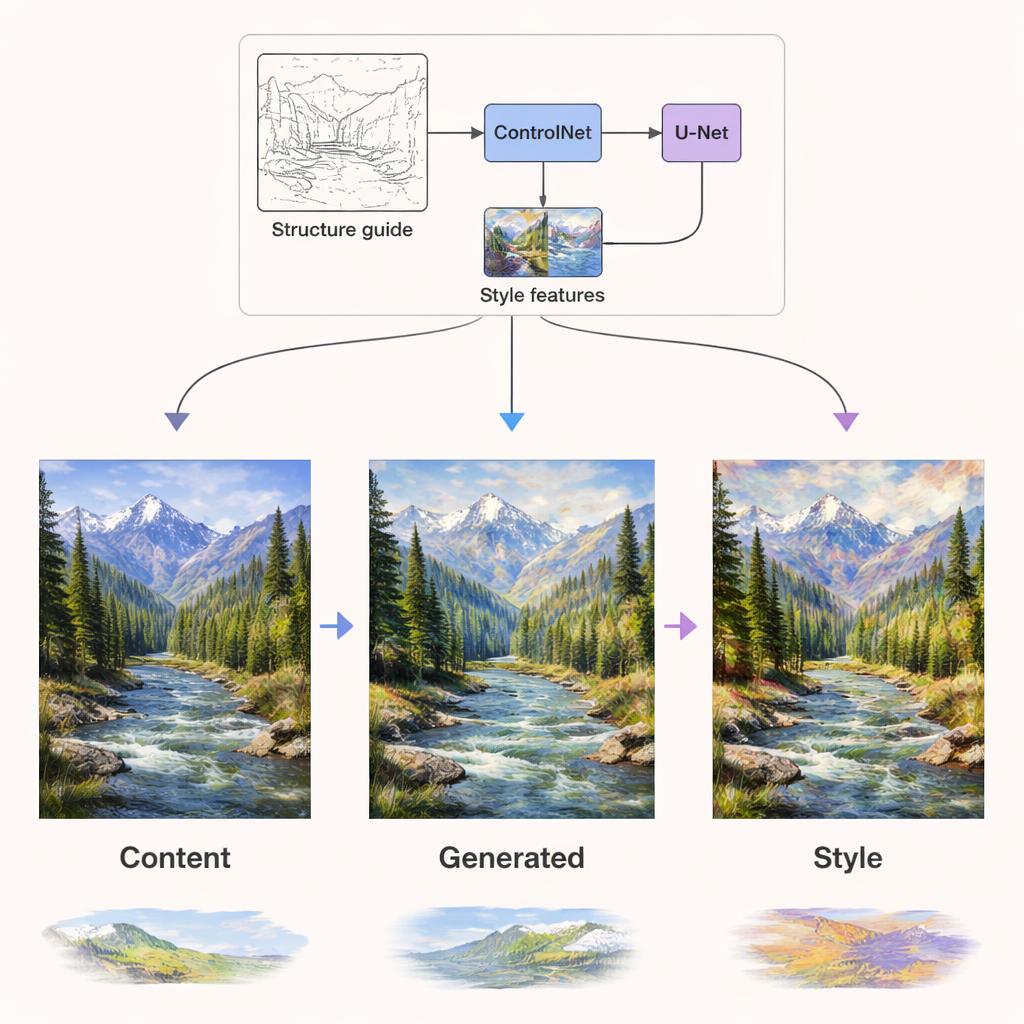
Bessere Qualität, mehr Stile, weniger Rechenaufwand
Die Autoren testen DCLSDM rigoros an zwei öffentlichen Datensätzen: WikiArt, das Dutzende von Kunstbewegungen abdeckt, und Summer2Winter Yosemite, das sich auf saisonale Veränderungen in einer Landschaft konzentriert. Sie vergleichen ihr Modell mit einer Reihe von State‑of‑the‑Art‑Systemen aus Forschung und Industrie. Bei Messgrößen wie struktureller Ähnlichkeit, wahrgenommener visueller Qualität und der Nähe der generierten Bilder zu realen Kunstwerken erzielt DCLSDM durchgängig die besten Werte. Es läuft außerdem schneller, verbraucht weniger Speicher und hat weniger Parameter als viele Konkurrenten, bietet aber dennoch flexible Mischungen mehrerer Stile und unterstützt sowohl bildbasierte als auch textbasierte Stileingaben.
Was das für alltägliche Kreativität bedeutet
Praktisch zeigt diese Arbeit, dass es möglich ist, Nutzern eine fein abgestufte Kontrolle darüber zu geben, wie ein Bild aussieht, ohne das zu opfern, was das Bild zeigt — und das auf bescheidenerer Hardware. Designer könnten schnell viele künstlerische Varianten desselben Layouts ausprobieren, mobile Apps könnten reichhaltigere Filter anbieten, die Gesichter oder Szenen nicht verformen, und Projekte zur Kulturerbe‑Erhaltung könnten alte Fotos umstylen und dabei entscheidende strukturelle Details bewahren. Durch die saubere Trennung von Inhalt und Stil innerhalb eines modernen Diffusionsrahmens weist DCLSDM den Weg zu einer Zukunft, in der kreative Bildwerkzeuge zugleich leistungsfähiger und verlässlicher im Alltag sind.
Zitation: Chu, K., Shang, Y., Zhang, L. et al. Content style decoupling for multi style image generation using latent diffusion architecture. Sci Rep 16, 6642 (2026). https://doi.org/10.1038/s41598-026-36407-3
Schlüsselwörter: Bildstiltransfer, Diffusionsmodelle, Inhalt‑Stil‑Entkopplung, digitale Kunstgenerierung, effiziente Bildgenerierung