Clear Sky Science · de
Verstärkendes Lernframework für computerisiertes adaptives Testen mit Multi‑Armed‑Bandit‑Ansatz
Intelligentere Tests für das digitale Klassenzimmer
Wer schon einmal eine lange, einheitliche Prüfung durchgestanden hat, kennt das Gefühl: langweilig und ungerecht. Manche Fragen sind viel zu einfach, andere unlösbar schwer, und die Endnote bildet möglicherweise nicht wirklich ab, was jemand weiß. Diese Arbeit stellt eine neue Methode vor, um computerbasierte Tests zu erstellen, die sich in Echtzeit an die Antworten jedes Einzelnen anpassen. Indem die Autoren Ideen aus der modernen künstlichen Intelligenz übernehmen, wollen sie Prüfungen kürzer, genauer und besser auf die tatsächliche Fähigkeit der Testpersonen zugeschnitten machen.
Warum fixe Tests nicht ausreichen
Traditionelle Prüfungen stellen allen Studierenden dieselbe Frageauswahl. Das macht die Testentwicklung einfach, verschwendet aber Informationen: leistungsstarke Prüflinge arbeiten viele einfache Aufgaben ab, während kämpfende Lernende schnell überfordert sind. Computerisiertes adaptives Testen versucht, das zu beheben, indem jede nächste Frage auf früheren Antworten basiert, doch die meisten heutigen Systeme stützen sich noch auf jahrzehntealte statistische Modelle und handgefertigte Regeln. Diese älteren Ansätze haben Probleme, komplexe Antwortmuster zu erfassen, und können häufig nicht die großen Unterschiede zwischen Lernenden in modernen, groß angelegten Online‑Umgebungen vollständig berücksichtigen.
Moderne KI ins Testen bringen
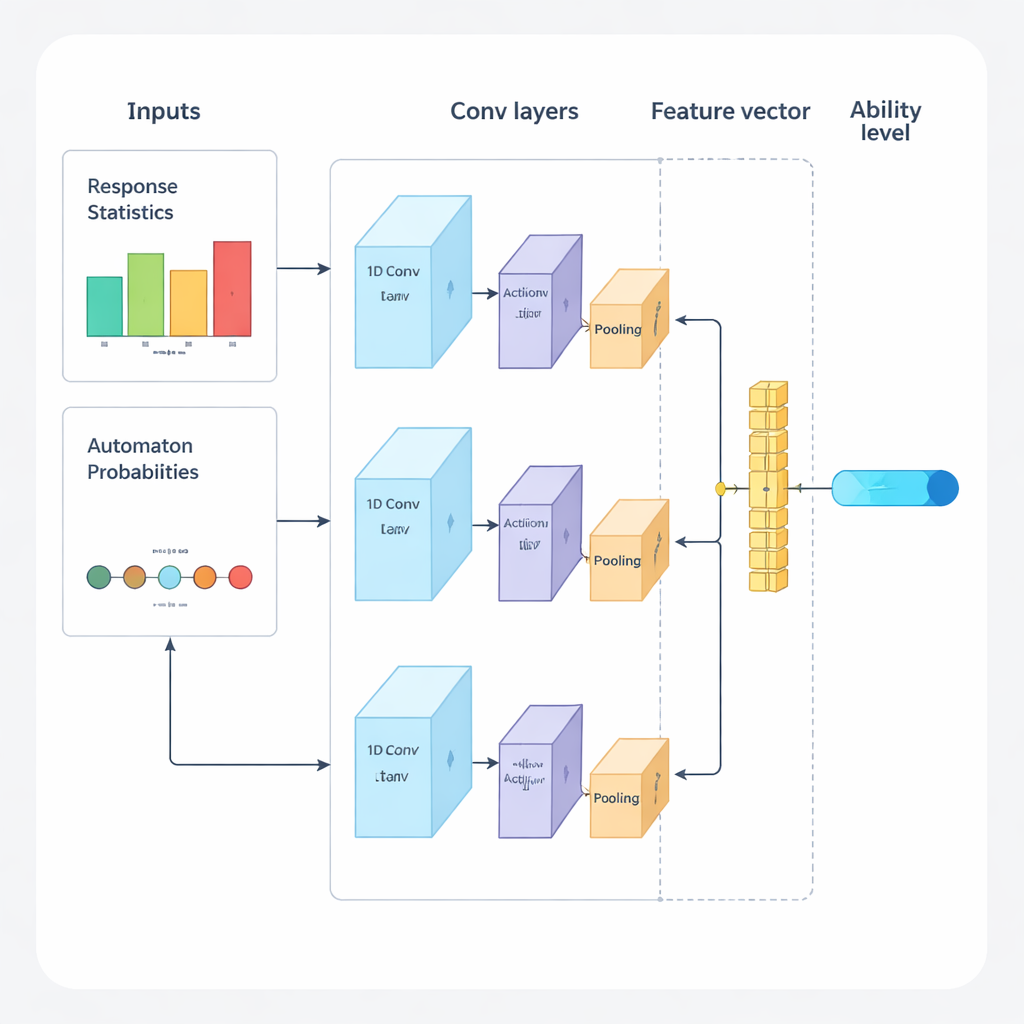
Die Autoren schlagen ein neues Framework vor, das Deep Learning und Verstärkendes Lernen kombiniert, um adaptive Prüfungen von Anfang bis Ende zu steuern. Das System arbeitet in wiederholten Zyklen. Zuerst analysiert ein eindimensionales Faltungsnetzwerk (1D‑CNN) die jüngsten Antworten einer Person, die Schwierigkeit der Fragen und weitere zusammenfassende Statistiken. Aus diesem Datenstrom erzeugt es eine einzelne Zahl, die die aktuelle Fertigkeit der Person auf einer normalisierten Skala repräsentiert, ähnlich der Abbildung von Fähigkeit in traditionellen Testtheorien, hier jedoch direkt aus den Daten erlernt. Dieses Netzwerk wird darauf trainiert, subtile Muster zu erkennen, etwa beständige Erfolge bei schwierigeren Aufgaben oder unerwartete Fehler bei einfacheren.
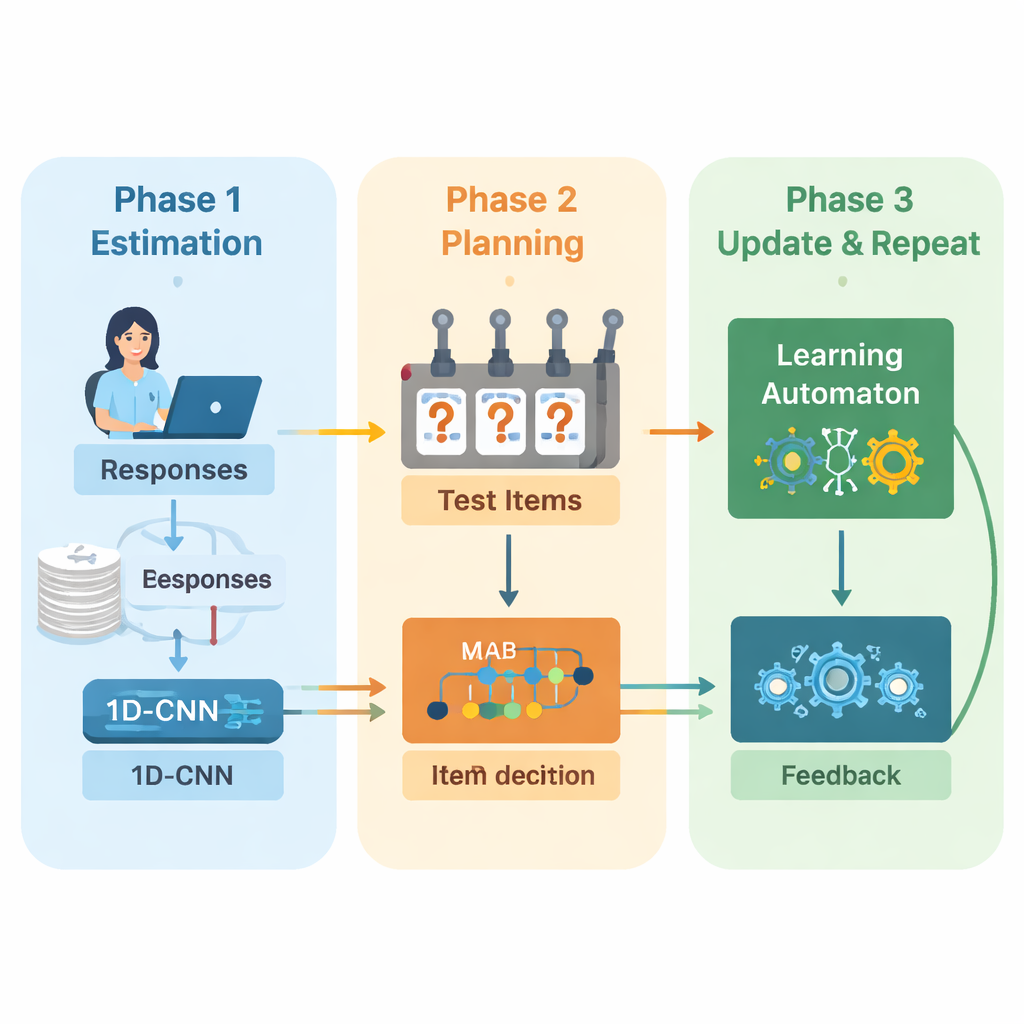
Die richtige nächste Frage auswählen
Sobald das System ein aktualisiertes Fähigkeitsbild hat, muss es entscheiden, welche Frage als Nächstes gestellt wird. Dafür nutzen die Autoren eine Multi‑Armed‑Bandit‑Strategie, ein klassisches Werkzeug aus der Entscheidungstheorie, bei dem jede mögliche Aktion wie das Ziehen eines Hebels an einem Spielautomaten behandelt wird. In diesem Kontext ist jede Frage im Aufgabenbestand ein Arm. Der Algorithmus betrachtet Fragen, deren Schwierigkeit ungefähr zur aktuellen Fähigkeitsabschätzung passt, und wählt dann diejenigen aus, die voraussichtlich am informativsten sind. Er balanciert zwei Ziele: eine gute Schwierigkeitsanpassung, sodass Antworten weder zu einfach noch zu schwer sind, und die Abdeckung möglichst vieler unterschiedlicher Inhaltsbereiche, damit der Test keine wichtigen Themen vernachlässigt. Eine Belohnungsgröße, die diese beiden Ziele mischt, steuert den Auswahlprozess.
Aus den eigenen Entscheidungen lernen
Damit das System sich während der Prüfung weiter verbessert, ergänzt es eine weitere Lernkomponente, die als Lernautomat bezeichnet wird. Dieses Modul beobachtet, wie sich die geschätzte Fähigkeit über die Runden verändert und ob die Genauigkeit der Person besser oder schlechter wird. Es passt eine kleine Menge von Wahrscheinlichkeiten an, die zusammenfassen, ob das Modell erwartet, dass die Fähigkeit steigt, gleich bleibt oder sinkt. Diese Wahrscheinlichkeiten werden dann als zusätzliche Eingabe an das neuronale Netzwerk in der nächsten Runde zurückgeführt. Auf diese Weise lernt die Testmaschine nicht nur über den Lernenden, sondern auch über ihre eigenen bisherigen Entscheidungen – sie belohnt Trends, die zu genauen Schätzungen führten, und bestraft solche, die dies nicht taten.
Wie gut funktioniert es in der Praxis?
Die Forschenden evaluierten ihr Framework mit einem großen, mehrsprachigen Prüfungsdatensatz und Tausenden simulierter Testpersonen, deren wahre Fähigkeitsniveaus bekannt waren. Sie verglichen ihren Ansatz mit mehreren führenden adaptiven Testmethoden. Über verschiedene Fehler‑ und Korrelationsmaße hinweg lieferte das neue System genauere Fähigkeitsabschätzungen bei gleichzeitig geringerem Fragenaufwand. Seine Fehler — gemessen an gängigen Kennzahlen wie Root Mean Squared Error und Mean Absolute Error — lagen deutlich unter denen konkurrierender Methoden. Gleichzeitig verteilte es die Verwendung der Fragen gleichmäßiger über den Aufgabenbestand und verringerte so das Risiko, dass bestimmte Fragen übermäßig oft eingesetzt werden und dadurch öffentlich werden.
Was das für zukünftige Prüfungen bedeutet
Alltagsnah formuliert deutet diese Arbeit darauf hin, dass künftige computerbasierte Tests eher wie eine maßgeschneiderte Nachhilfestunde als wie eine starre Prüfung wirken könnten. Fragen würden schnell die passende Schwierigkeit für jede Person treffen, das gesamte relevante Themenspektrum abdecken und beenden, sobald das System mit seiner Einschätzung zufrieden ist — oft mit weniger Items als heutige Tests. Zwar hängt die Methode weiterhin von guten Trainingsdaten und Rechenressourcen ab und wurde bisher nur an einem Datensatz erprobt, doch sie weist den Weg zu einer neuen Generation intelligenterer, fairerer und effizienterer Assessments, die sich natürlich an einzelne Lernende anpassen.
Zitation: Tang, B., Li, S. & Zhao, C. Reinforcement learning framework for computerized adaptive testing using multi armed bandit approach. Sci Rep 16, 7441 (2026). https://doi.org/10.1038/s41598-026-36394-5
Schlüsselwörter: computerisiertes adaptives Testen, Bildungsbewertung, Deep Learning, Verstärkendes Lernen, Multi‑Armed‑Bandit