Clear Sky Science · de
Identifizierung von Risikofaktoren für großangelegte Vergnügungseinrichtungen mithilfe eines Mixtures-of-Experts-Ansatzes und der Fusion mehrerer Modelle
Warum die Sicherheit von Themenparks intelligenteres Lesen braucht
Jedes Jahr steigen Hunderte Millionen Menschen in Achterbahnen, Falltürme und Karussells und vertrauen darauf, dass komplexe Maschinen und beschäftigte Betreiber sie schützen. Hinter den Kulissen erstellen Aufsichtsbehörden und Ingenieure riesige Mengen an Berichten, Unfallaufzeichnungen und öffentlichen Beschwerden – doch die meisten dieser Informationen liegen als Text vor und sind schwer schnell zu durchsuchen. Diese Studie untersucht, wie moderne künstliche Intelligenz diese Dokumente in großem Maßstab „lesen“, Gefahrenmuster früher erkennen und Behörden ein klareres Bild darüber geben kann, wo Fahrgeschäfte am ehesten versagen.
Von verstreuten Berichten zu einem einheitlichen Risikobild
China beherbergt heute mehr als 25.000 große Fahrgeschäfte und über 700 Millionen Besucher pro Jahr. Trotz insgesamt besserer Sicherheitsstandards kommen seltene, aber schwere Unfälle weiterhin vor, oft nachdem Inspektionen frühe Warnsignale übersehen haben, die in technischen Beschreibungen oder Nutzerbeschwerden verborgen waren. Die Autoren argumentieren, dass traditionelle Aufsicht – basierend auf periodischen manuellen Kontrollen, Expertenurteilen und Wartungsprotokollen – für ein so dynamisches Umfeld zu langsam und subjektiv ist. Sie stellen eine große, realweltliche Textsammlung zusammen, die Unfallberichte, Gesetze und Normen, Inspektions- und Wartungsaufzeichnungen sowie Online-Beschwerden zu Vergnügungseinrichtungen umfasst. Nach sorgfältiger Bereinigung und Filterung wird dieses mehrquellige Korpus zur Rohdatenbasis für ein automatisiertes, datengetriebenes Risikoüberwachungssystem. 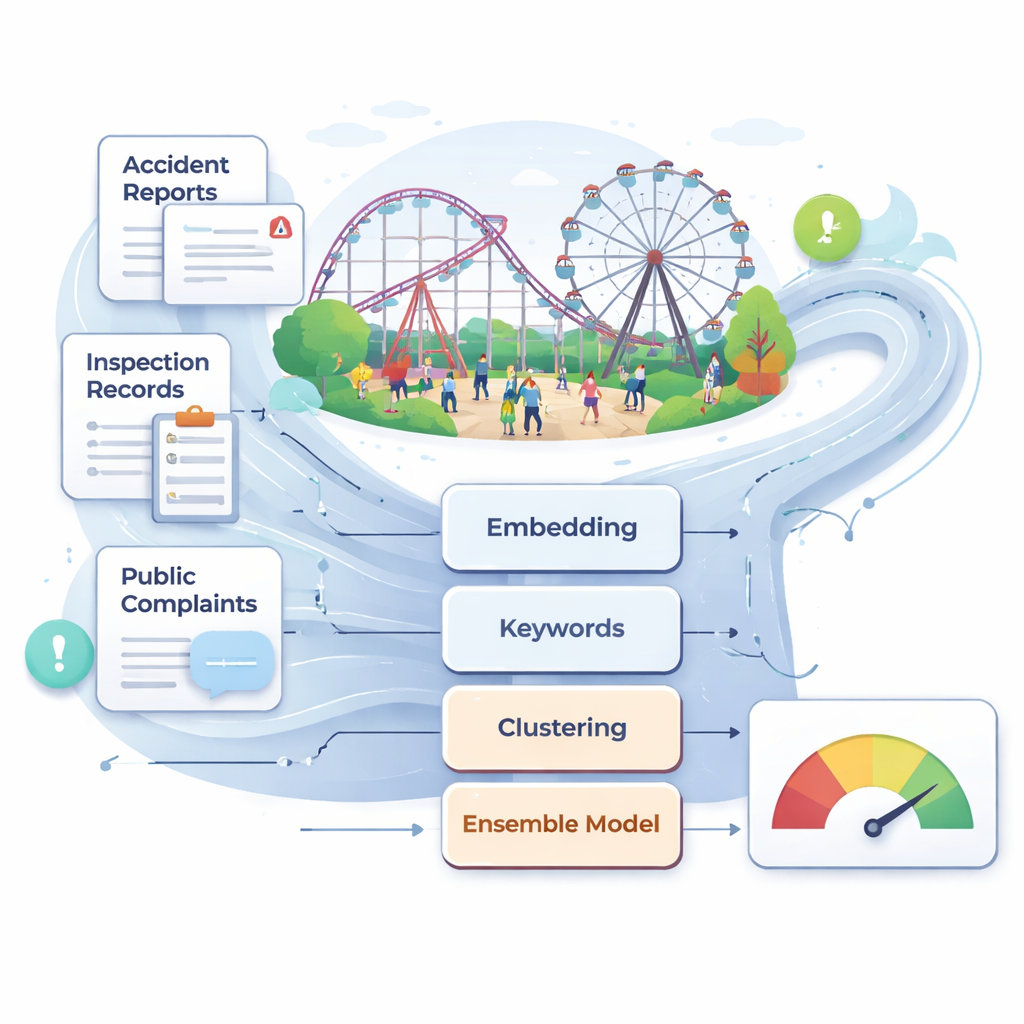
Computern das Verständnis der Risikosprache beibringen
Um diesen unordentlichen Text zu interpretieren, nutzen die Forschenden moderne Sprachmodelle, die Sätze in numerische Vektoren umwandeln, welche deren Bedeutung erfassen. Sie verwenden vornehmlich ein chinesisches Modell namens BGE, das jeden Text als 1.024-dimensionalen Punkt im Raum repräsentiert, ergänzt durch einen kompakten Satz von 30 schlüsselwortbasierten Merkmalen, die sich auf Begriffe wie „Wartung“, „Inspektion“ und „Beseitigung“ konzentrieren. Diese doppelte Sicht – tiefer semantischer Kontext plus handkuratierte Risikobegriffe – hilft dem System, subtile Unterschiede zu erkennen, etwa zwischen routinemäßigen Kontrollen und schwerwiegenden Mängeln. Das Team experimentiert außerdem mit einem anderen modernen Embedding-Modell, Qwen3, um zu prüfen, ob ein anderer Sprachbackbone die Leistung verbessert; in der Praxis erweist sich BGE für diese Sicherheitsaufgabe als geringfügig besser.
Verborgene Muster und zentrale Schwachstellen finden
Bevor Texte in konkrete Risikokategorien eingeteilt werden, nutzen die Autoren unüberwachte Methoden, um natürliche Gruppierungen aufzudecken. Sie wenden k-means-Clustering auf die Embeddings an und verwenden eine Visualisierungsmethode namens UMAP, die zeigt, dass Berichte in mehrere klar erkennbare Themencluster fallen. Anschließend bauen sie einen semantischen Graphen, in dem jeder Knoten ein sicherheitsrelevantes Schlüsselwort darstellt und Kanten starke Koauftreten und semantische Ähnlichkeit anzeigen. Ein Community-Detection-Algorithmus gruppiert diese Knoten in Cluster, die breiten Themen wie Geräte- und Struktursicherheit, täglicher Betrieb und Wartung, Notfallreaktion sowie Management und Aufsicht entsprechen. Innerhalb dieses Netzwerks fungieren bestimmte Wörter – etwa „Wartung“, „Inspektion“ und „Verantwortung“ – als Brücken zwischen Clustern und heben übergreifende Schwächen hervor, die auf verschiedenen Wegen Unfälle auslösen können. Aus dieser Struktur extrahieren sie 31 Kernrisikofaktoren, die vier Hauptdimensionen abdecken, von der Echtzeitüberwachung der Ausrüstung bis zur Klarheit der Aufgabenverantwortlichkeiten. 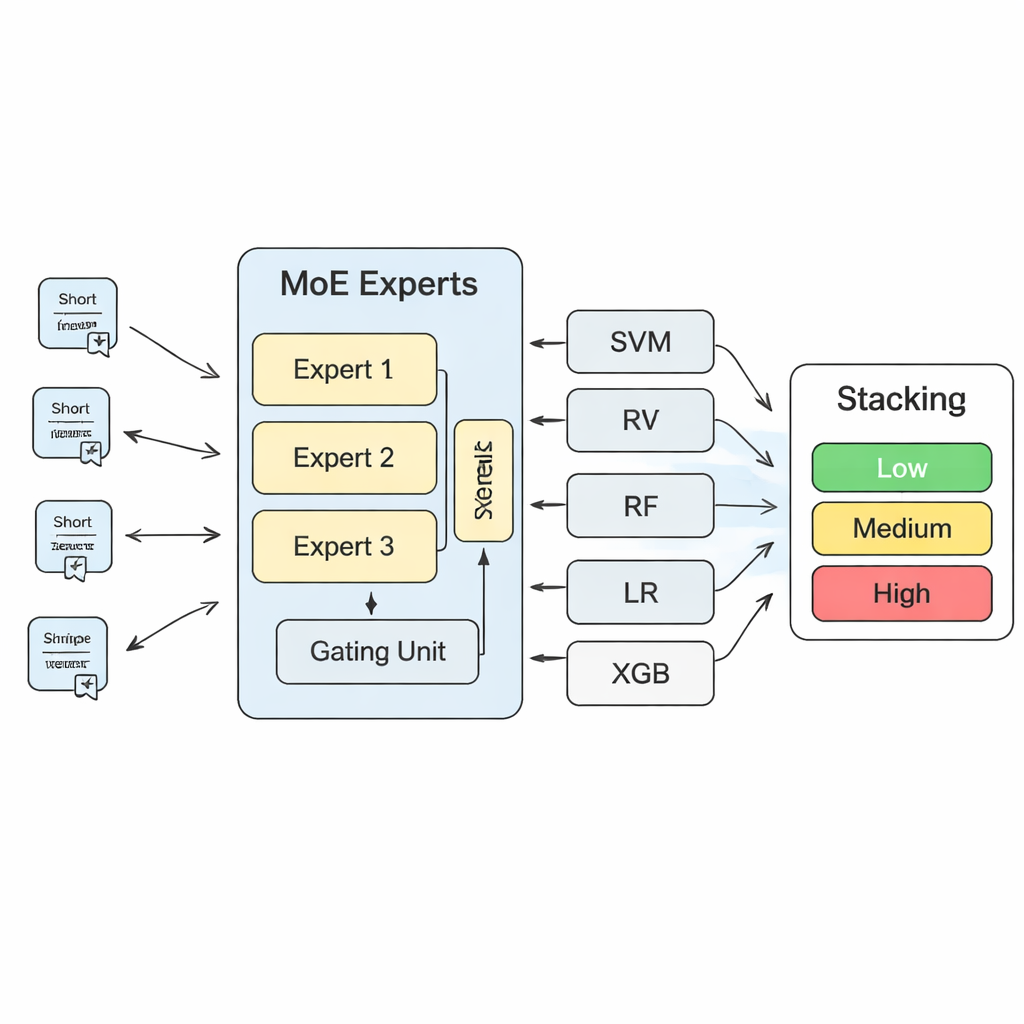
Viele Modelle zu einem stärkeren Sicherheitsrichter verschmelzen
Um diese Erkenntnisse in konkrete Risikovorhersagen zu überführen, baut die Studie ein geschichtetes Machine-Learning-System. Im Kern steht ein „Mixture of Experts“ (MoE)-Modell: mehrere neuronale Netze, oder Experten, lernen, sich auf unterschiedliche Risikomuster zu spezialisieren, während eine Steuerkomponente entscheidet, welchen Experten für jeden neuen Text am meisten zu vertrauen ist. Die Ausgaben dieses MoE-Modells werden dann mit den Vorhersagen traditionellerer Algorithmen kombiniert, etwa Support Vector Machines, Random Forests, logistischer Regression und gradientenverstärkten Bäumen. Eine abschließende „Stacking“-Schicht – ein weiteres Machine-Learning-Modell – lernt, wie all diese Einschätzungen zu gewichten sind, um zu einer endgültigen Entscheidung zu gelangen. Durch umfangreiche Kreuzvalidierung stellen die Autoren fest, dass drei Experten in der MoE-Schicht das beste Gleichgewicht zwischen Modellkapazität und Stabilität bieten.
Was die Verbesserungen für die Praxis bedeuten
Verglichen mit einzelnen Modellen verbessert das MoE‑plus‑Stacking‑System die Genauigkeit, Präzision, Trefferquote und eine Zuverlässigkeitsmetrik namens LogLoss deutlich. Praktisch bedeutet das: weniger verpasste Warnungen und weniger Fehlalarme beim Screening großer Mengen sicherheitsrelevanter Texte. Das Modell kann auf einem gewöhnlichen Arbeitsplatzrechner laufen und schnelle Risikoabschätzungen für neue Inspektionsberichte oder Beschwerden liefern, wodurch es sich als Entscheidungsunterstützungstool eignet und nicht als Ersatz für menschliches Urteilsvermögen. Die Autoren betonen, dass ihr Ansatz auch auf andere Sonderausrüstungen wie Aufzüge oder Seilbahnen übertragbar ist. Für Laien lautet die wichtigste Erkenntnis: Indem man Computern beibringt, die Sprache der Sicherheit – über technische Dokumente, Vorschriften und alltägliche Beschwerden hinweg – zu lesen, können Aufsichtsbehörden Gefahrenmuster früher erkennen, Inspektionen gezielter planen und den Besuch im Park für alle etwas sicherer machen.
Zitation: Hao, S., Xing, L. & Zhang, M. Risk factor identification for large scale amusement facilities using mixture of experts and fusion of multiple models. Sci Rep 16, 6804 (2026). https://doi.org/10.1038/s41598-026-36377-6
Schlüsselwörter: Sicherheitsprüfung von Fahrgeschäften, Textanalyse von Risiken, maschinelles Lernen, Mixture of Experts, Überwachung der öffentlichen Sicherheit