Clear Sky Science · de
Gruppenlernen in Empfehlungssystemen: auf dem Weg zu adaptiver und impliziter Gruppenmodellierung
Warum intelligentere Gruppen online wichtig sind
Von Filmabenden mit Freunden bis hin zu Familienreisen werden viele unserer Entscheidungen in Gruppen getroffen. Dennoch denken die meisten Online‑Plattformen weiterhin in Einzelpersonen. Dieses Papier stellt eine einfache, aber folgenreiche Frage: Was wäre, wenn unsere Streaming‑Seiten, Shopping‑Apps und Reiseportale stillschweigend natürliche Gruppen von Menschen und Artikeln selbst entdecken und sich an sie anpassen könnten, anstatt sich auf feste, manuell erstellte Gruppenlisten zu verlassen? Die Autorinnen und Autoren stellen eine neue Methode vor, mit der Empfehlungssysteme solche Gruppen automatisch lernen können, um Vorschläge zu machen, die sich für alle Beteiligten fair und zufriedenstellend anfühlen.
Von festen Teams zu flexiblen Gemeinschaften
Die heutigen Gruppenempfehlungs‑Werkzeuge beginnen meist mit einer starren Vorstellung davon, wer zusammengehört: ein vordefinierter Freundeskreis, eine Klasse oder einmalig mit einem statistischen Werkzeug gebildete Cluster. Das System versucht dann, ein „gut genuges“ Element für diese eingefrorene Gruppe zu finden. Das wirkliche Leben ist jedoch unordentlicher. Die Personen, die heute Abend einen Film auswählen, können sich von denen unterscheiden, die nächsten Monat einen Urlaub planen, und auch die Gegenstände selbst lassen sich natürlich in Bündel einteilen, etwa Playlists oder Reisepakete. Die Arbeit argumentiert, dass die Gruppenbildung nicht als separater, einmaliger Schritt behandelt werden sollte, sondern in den Kern dessen integriert werden muss, wie das Empfehlungssystem aus Daten lernt.
Eine verborgene Landkarte von Menschen und Dingen
Die Autorinnen und Autoren stellen ein Modell vor, das sie Deep Dynamic Group Learning Model (DDGLM) nennen. Im Kern baut das System eine verborgene Landkarte, in der sowohl Personen als auch Artikel als Punkte in einem mathematischen Raum dargestellt werden. Anstatt jede Person oder jedes Produkt einer einzigen festen Gruppe zuzuordnen, lässt das Modell sie zunächst mehreren überlappenden „weichen“ Gruppen mit unterschiedlichen Mitgliedschaftsgraden angehören. Eine Temperatursteuerung schärft diese Mitgliedschaften im Verlauf des Lernens, sodass zum Zeitpunkt des Einsatzes jede Person oder jeder Artikel praktisch derjenigen Gruppe zugeordnet ist, die für die jeweilige Aufgabe am besten passt. Diese gelernten Gruppen basieren nicht allein auf sichtbaren Merkmalen wie Alter oder Genre, sondern darauf, wie gut sie dem System helfen, die Bewertungen oder Entscheidungen vorherzusagen, die Nutzer tatsächlich treffen.
Individuen und Gruppen in Einklang bringen
DDGLM geht einen Schritt weiter, indem es darauf besteht, dass das Bild einer Person als Individuum und das Bild dieser Person als Teil einer Gruppe übereinstimmen müssen. Es fügt dem Lernprozess einen zusätzlichen Term hinzu, der individuelle und Gruppenrepräsentationen sanft näher zusammenführt. Das verhindert, dass Gruppenprofile in unrealistische Muster abdriften, die kein Mitglied wirklich widerspiegelt, und erlaubt dem Modell zugleich, geteilte Vorlieben einzufangen. Mit diesen Repräsentationen kann das System vier typische Situationen einheitlich behandeln: die Empfehlung eines einzelnen Elements für eine Person, eines Elements für eine Gruppe, eines Bündels von Elementen für eine Person oder eines Bündels für eine Gruppe. In jedem Fall reduzieren sich die Empfehlungen auf einfache Vergleiche zwischen den relevanten Personen‑ und Artikelgruppen innerhalb der verborgenen Landkarte.
Helfen adaptive Gruppen wirklich?
Um zu prüfen, ob diese Idee funktioniert, führten die Autoren umfangreiche Experimente mit bekannten Film‑Bewertungsdatensätzen namens MovieLens‑100K und MovieLens‑1M durch. Sie verglichen DDGLM mit Methoden, die Gruppen zufällig bilden, mit traditionellen Clustering‑Verfahren oder mit früheren einheitlichen Empfehlungsrahmen. In allen vier Szenarien — Einzelperson, Gruppe, Paket und Paket‑zu‑Gruppe — lieferte das dynamische Modell genauere Bewertungsprognosen und bessere Top‑Empfehlungen. Es war besonders stark, wenn Gruppen oder Bündel involviert waren, in denen statische Ansätze Schwächen zeigten. Sorgfältige statistische Tests bestätigten, dass diese Verbesserungen nicht nur zufällig zustande kamen, und Laufzeitmessungen zeigten, dass die Methode gut mit wachsender Anzahl von Nutzern, Artikeln und Gruppen skaliert.
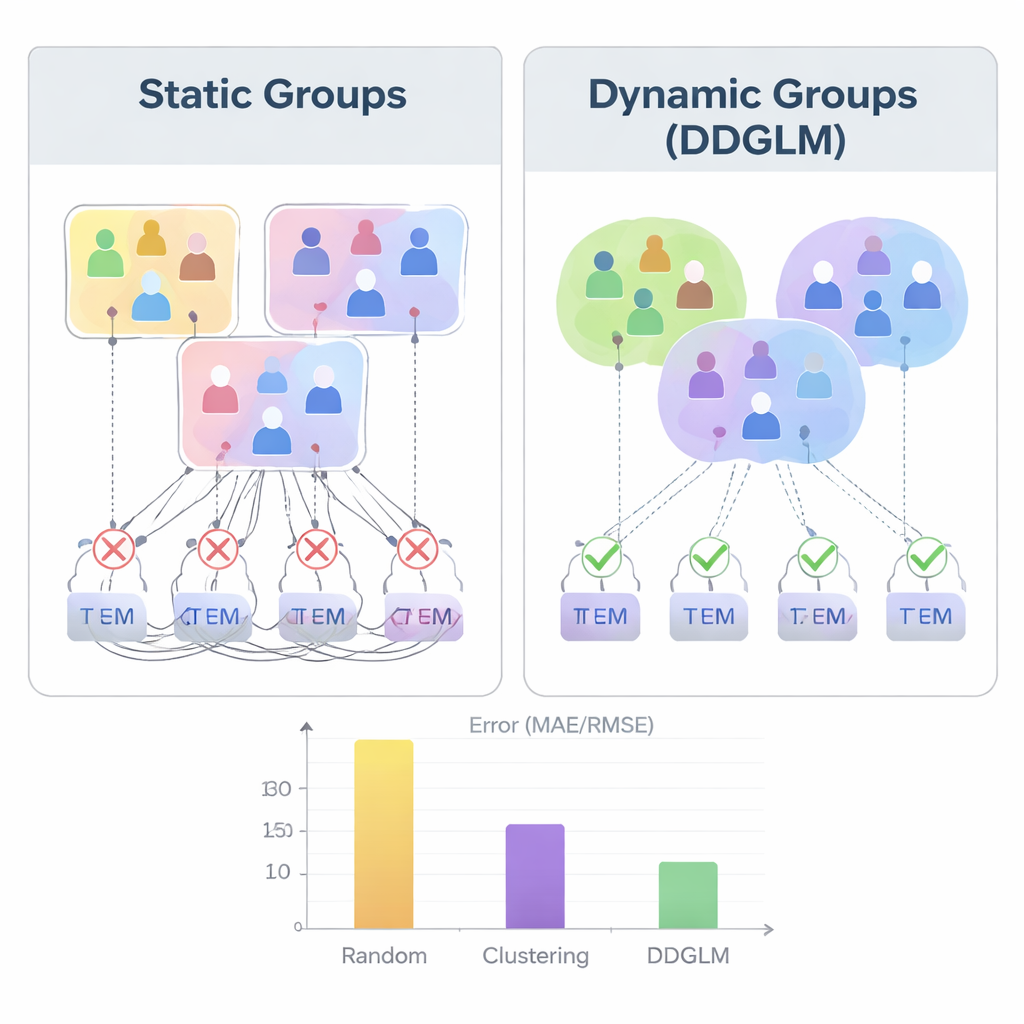
Was das für Alltagsnutzer bedeutet
Für Nicht‑Fachleute ist die Quintessenz klar: Empfehlungssysteme funktionieren besser, wenn sie nützliche Gruppierungen spontan entdecken dürfen, anstatt an starren, im Voraus gewählten Gruppenbegriffen festzuhalten. Indem DDGLM lernt, welche Personen und Artikel in den Daten natürlich zusammengehören — und diese Muster laufend aktualisiert —, kann es Vorschläge erzeugen, die geteilte Vorlieben besser widerspiegeln, sei es ein Film für eine Familie, eine Playlist für eine Party oder ein Urlaubspaket für eine Reisegruppe. Die Studie zeigt, dass die Behandlung der Gruppenbildung selbst als lernbare Komponente zu genaueren, anpassungsfähigeren und potenziell gerechteren Empfehlungen in den digitalen Diensten führt, die wir täglich nutzen.
Zitation: Busireddy, N.R., Kagita, V.R. & Kumar, V. Group learning in recommendation systems: towards adaptive and implicit group modeling. Sci Rep 16, 5918 (2026). https://doi.org/10.1038/s41598-026-36356-x
Schlüsselwörter: Gruppenempfehlungssysteme, dynamisches Gruppenlernen, personalisierte Empfehlungen, kollaboratives Filtern, Deep Learning