Clear Sky Science · de
Deep-Inception-Neuronales Netzwerk mit Residualverbindungen zur Erkennung handgeschriebener tamilischer Zeichen
Handschrift im digitalen Zeitalter bewahren
Von alten Palmblattmanuskripten bis zu alltäglichen Notizen lebt ein großer Teil des tamilischen schriftlichen Erbes noch auf Papier. Diese Vielfalt handgeschriebener Seiten in durchsuchbaren, digitalen Text zu verwandeln, ist entscheidend, um Kultur zu bewahren, Bildung zu unterstützen und bessere Sprachtechnologien zu entwickeln. Dieser Artikel stellt ein neues Computer-Vision-System vor, TamHNet genannt, das tamilische Handschrift mit nahezu perfekter Genauigkeit liest, selbst wenn Zeichen einander verwirrend ähnlich sehen.
Warum tamilische Zeichen für Computer schwierig sind
Tamil wird von mehr als 80 Millionen Menschen gesprochen und nutzt eine Schrift mit 247 Zeichen, darunter Vokale, Konsonanten und viele Kombinationen beider. Viele Zeichen unterscheiden sich nur durch winzige Kringel oder zusätzliche Striche, und Schreibende variieren stark darin, wie sie jedes Zeichen formen. Paare wie எ/ஏ oder ஒ/ஓ können auf den ersten Blick fast identisch wirken, und Zeichen wie ல und வ lassen sich leicht verwechseln. Frühere Computerprogramme und selbst moderne Maschinenlernverfahren hatten oft Probleme mit diesen Feinheiten, was zu falsch gelesenen Wörtern und unzuverlässiger Digitalisierung von Dokumenten führte.
Ein reales Handschrift‑Datenset aufbauen
Um ihr System unter realistischen Bedingungen zu trainieren und zu testen, erstellten die Forschenden ein neues Tamil Isolated Character Dataset mit handschriftlichen Proben von 1.000 Studierenden. Statt sich auf synthetische oder computererzeugte Bilder zu stützen, sammelten sie echte Stift‑auf‑Papier‑Zeichen, die 12 Vokale, 18 Konsonanten und 214 gängige Kombinationen abdecken. Das Team beschriftete diese Proben sorgfältig und stellte das Datenset öffentlich zugänglich, damit andere Gruppen Methoden vergleichen und darauf aufbauen können. Indem sie die Schrift in 104 Basissymbole organisierten, die alle 247 Zeichen erfassen, reduzierten sie Redundanz und repräsentierten dennoch die volle Bandbreite der in echter Handschrift auftretenden Formen.
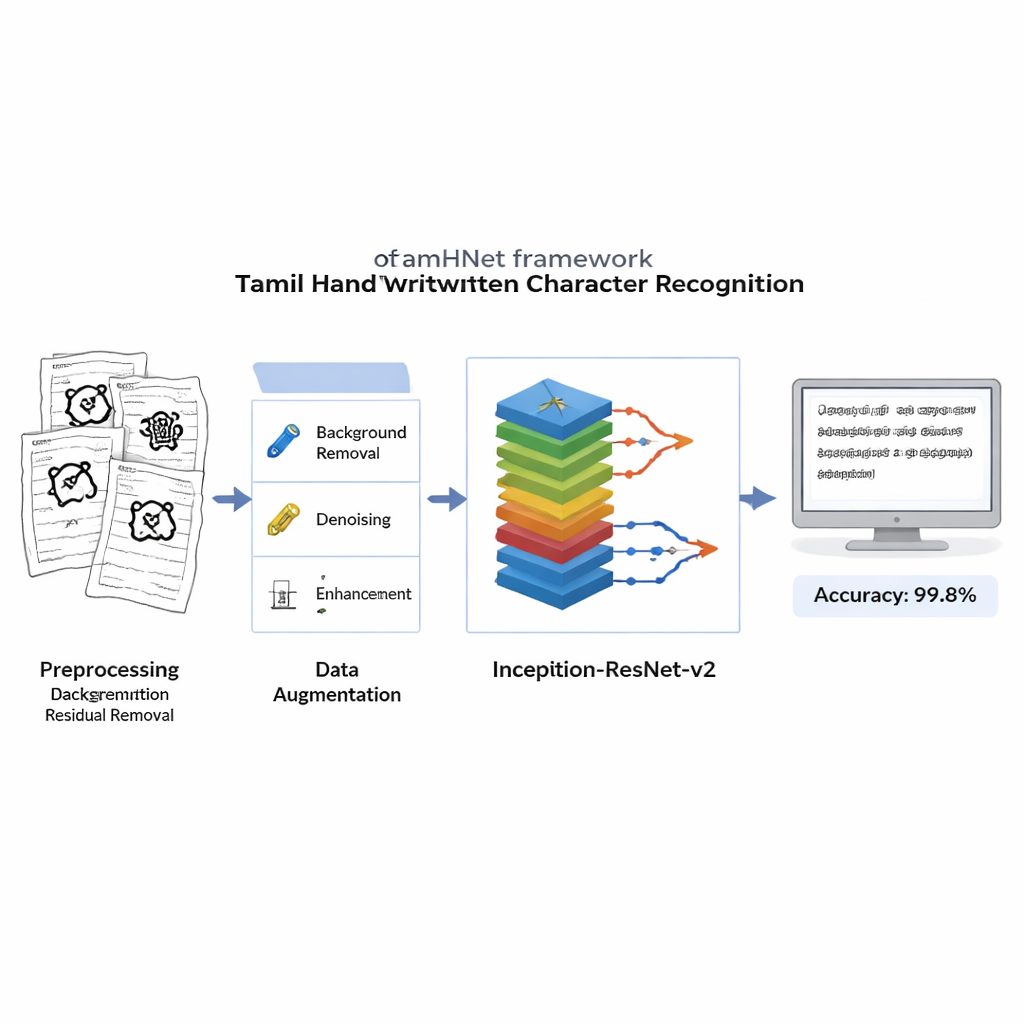
Reinigen, strecken und die Bilder lehren
Bevor ein Lernprozess beginnt, wird jedes eingescanntes Bild bereinigt, um störende Hintergründe, Verschmierungen und ungleichmäßige Beleuchtung zu entfernen, während die feinen Striche, die jedes Zeichen definieren, erhalten bleiben. Die Bilder werden in scharfe Schwarz‑Weiß‑Bilder umgewandelt und auf ein Standardformat skaliert, damit der Computer jedes Beispiel auf dieselbe Weise sieht. Um das System robust gegenüber verschiedenen Schreibgewohnheiten zu machen, wenden die Autorinnen und Autoren kontrollierte Verzerrungen an: Sie verschieben leicht Schlüsselpunkte im Bild und führen sanfte Verformungen durch, wodurch neue Versionen jedes Zeichens erzeugt werden, die für einen Menschen weiterhin wie dasselbe Zeichen aussehen. Dieses erweiterte Trainingsset hilft dem Modell, Zeichen zu erkennen, selbst wenn sie schräg, gestaucht oder mit ungewöhnlichen Proportionen geschrieben sind.
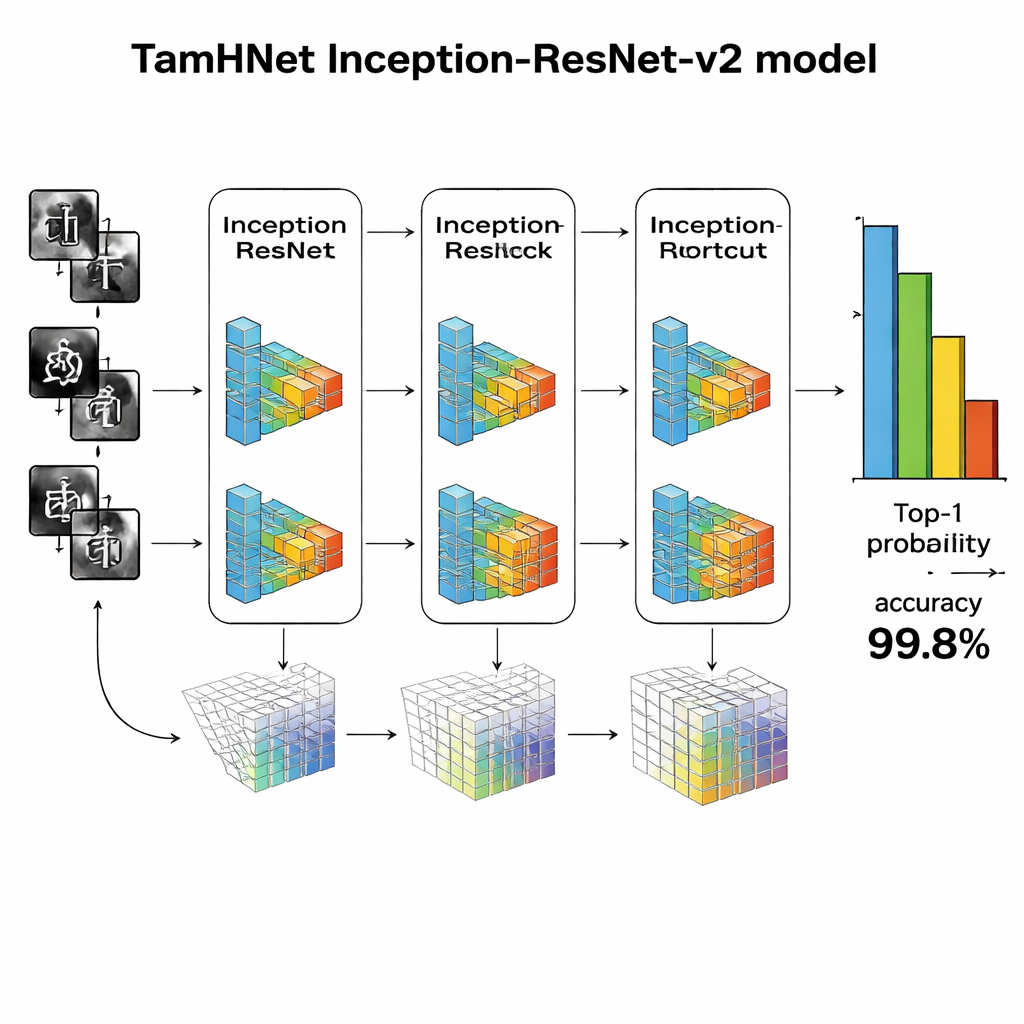
Ein tiefes Netzwerk, das subtile Unterschiede lernt
Im Kern von TamHNet steht eine leistungsstarke Deep‑Learning‑Architektur namens Inception‑ResNet‑v2, ursprünglich für allgemeine Objekterkennung entwickelt. Die Autorinnen und Autoren passen dieses Netzwerk speziell für tamilische Handschrift an und feinabstimmen es. Das Modell verarbeitet jedes Bild durch viele Schichten, die rohe Pixel schrittweise in höherwertige Muster wie Kanten, Kurven und Zeichenbestandteile verwandeln. Besondere Abkürzungsverbindungen, sogenannte Residual‑Verbindungen, stabilisieren das Training und helfen dem Netzwerk, sich auf kleine, aber entscheidende Unterschiede zwischen ähnlichen Zeichen zu konzentrieren. Anstatt alle internen Einstellungen auf einmal anzupassen, „tauten“ die Forschenden selektiv die nützlichsten Schichten auf und optimierten diese für diese Aufgabe. Sie verwenden eine Optimierungstechnik namens Adam, die automatisch anpasst, wie schnell sich jeder Parameter ändert, sodass das Netzwerk effizient aus komplexer und teils unordentlicher Handschrift lernen kann.
Wie gut das System Handschrift liest
Die Forschenden bewerten TamHNet auf dem neuen Datensatz mit standardisierten Maßen zur Erkennungsqualität. Das System erreicht etwa 99,8 % Genauigkeit über 104 Zeichenklassen und übertrifft damit eine breite Palette früherer Methoden auf Basis von Support‑Vector‑Machines, traditionellen Faltungsnetzwerken und anderen fortgeschrittenen Deep‑Learning‑Designs. Detaillierte Tests zeigen, dass selbst Zeichen mit extrem ähnlichen Formen in den meisten Fällen korrekt unterschieden werden, und statistische Kurven bestätigen, dass das Modell nur sehr selten ein Zeichen mit einem anderen verwechselt. Im Vergleich zur vorherigen Arbeit stellt dies einen deutlichen Fortschritt in der Zuverlässigkeit der Erkennung handgeschriebener tamilischer Zeichen dar.
Was das für Leser und Archive bedeutet
Für Nicht‑Fachleute ist die wichtigste Erkenntnis, dass Computer dramatisch besser darin werden, tamilische Handschrift zu lesen. Ein System wie TamHNet kann Werkzeuge antreiben, die Stapel von Notizbüchern, historische Manuskripte und handschriftliche Formulare mit minimaler menschlicher Korrektur in durchsuchbaren digitalen Text verwandeln. Während das aktuelle Modell noch nicht alle punktbasierten Symbole und ältere Schriftsystemvarianten abdeckt, skizzieren die Autorinnen und Autoren Pläne, es auf alte Schreibstile auszuweiten. Praktisch bringt uns diese Forschung der großflächigen, genauen Digitalisierung tamilischer Dokumente näher, hilft, das kulturelle Erbe zu sichern, und macht schriftliches Wissen künftigen Generationen leichter zugänglich.
Zitation: Periyasamy, H., Natarajan, S. & Amirtharajan, R. Deep inception neural network with residual connections for Tamil handwritten character recognition. Sci Rep 16, 6053 (2026). https://doi.org/10.1038/s41598-026-36330-7
Schlüsselwörter: Erkennung handgeschriebener tamilischer Zeichen, optische Zeichenerkennung, Deep Learning, Inception-ResNet, digitale Erhaltung