Clear Sky Science · de
Leistungsvergleich großer Sprachmodelle bei der Wissensbewertung zur Bor-Neutroneneinfangtherapie
Intelligente Tutoren für eine neue Form der Krebsbestrahlung
Die Bor-Neutroneneinfangtherapie, oder BNCT, ist eine aufstrebende Form der Strahlentherapie, die darauf abzielt, Tumore zu zerstören und dabei angrenzendes gesundes Gewebe zu schonen. Während sich diese komplexe Therapie von Forschungslaboren in Krankenhäuser ausbreitet, müssen Ärztinnen und Ärzte sowie Auszubildende eine Vielzahl neuer, spezialiserter Kenntnisse beherrschen. Diese Studie stellt eine aktuelle Frage: Können die heute weit verbreiteten KI-Chatbots beim Lehren und Unterstützen von BNCT helfen und wenn ja, wie verlässlich sind sie?
Wodurch unterscheidet sich BNCT von herkömmlicher Strahlentherapie?
BNCT funktioniert ganz anders als Standardbehandlungen mit Röntgenstrahlen oder Protonen. Patientinnen und Patienten erhalten Medikamente mit einer speziellen Form von Bor, die sich in Tumorzellen anreichert. Werden diese Zellen anschließend einem Neutronenstrahl ausgesetzt, durchlaufen die Boratome eine winzige Kernreaktion, die Teilchen mit sehr kurzer Reichweite freisetzt und die Krebszelle von innen zerstört, während das umliegende Gewebe weitgehend verschont bleibt. Dieser hochgezielte Ansatz ist besonders vielversprechend bei schwer zu behandelnden oder sauerstoffarmen Tumoren. Noch vor kurzer Zeit war BNCT auf Kernreaktoren als Neutronenquelle angewiesen, was den klinischen Einsatz beschränkte. Die Zulassung acceleratorbasierter BNCT-Geräte in Japan im Jahr 2020 und neue Zentren, die inzwischen in Ländern wie China arbeiten, haben BNCT für mehr Patientinnen und Patienten zu einer realistischen Option gemacht — und einen dringenden Bedarf an gezielter Ausbildung und Zertifizierung geschaffen.
Vier führende KIs im Test
Um zu prüfen, wie gut allgemeine Chatbots BNCT-Themen abdecken, entwickelten die Forschenden einen 47‑Fragen-Test, der Grundideen, aktuelle Forschung, klinische Praxis sowie Rechen- und Argumentationsaufgaben umfasste. Die Fragen lagen auf Chinesisch und Englisch vor und reichten von einfachen Fakten (wie Definitionen) bis zu anspruchsvolleren Problemen, die Logik oder numerische Arbeit erforderten. Vier große KI‑Familien — repräsentiert durch weit verbreitete Systeme verschiedener Anbieter — wurden jeweils in fünf separaten Testzeiträumen, in zwei Sprachen und mit zwei Fragestellungen (einfache Direktfragen und in kurze klinische Szenarien eingebettete Fragen) geprüft. Fachleute aus der Krebsversorgung bewerteten jede Antwort anhand eines Standard-Antwortschlüssels, und das Team verfolgte außerdem, wie oft die KIs Unsicherheit einräumten, etwa durch Formulierungen wie „Ich weiß es nicht.“
Wer beantwortete am besten — und bei welchen Fragen?
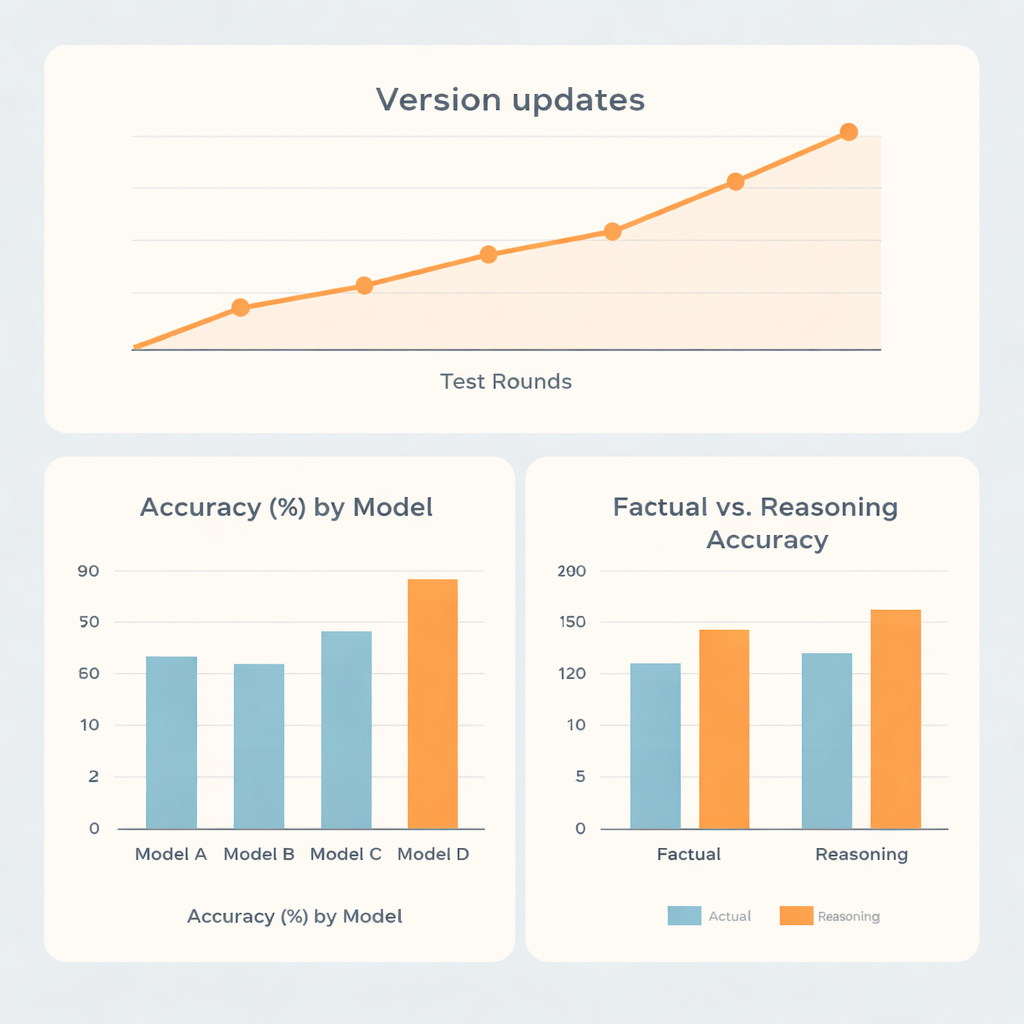
Insgesamt schnitten zwei Modellfamilien deutlich besser ab als die anderen beiden. Das stärkste System erreichte etwa 73 % Trefferquote, das zweitbeste rund 70 %, während die übrigen Modelle bei etwa 62 % bzw. 56 % lagen. Auffällig war, dass die Spitzenreiter sich nicht nur bei auswendig gelerntem Wissen hervortaten. Sie waren deutlich besser bei fragen, die intensive Schlussfolgerungen erforderten, als bei reinem Faktenabruf, was darauf hindeutet, dass diese Systeme innerhalb dieses engen medizinischen Feldes relativ stark bei mehrstufigen Denkaufgaben sind, etwa bei Dosierungsberechnungen oder Planungsaufgaben. Ein Modell zeigte nahezu gleiche Ergebnisse bei Fakten- und Argumentationsfragen, während ein anderes insgesamt zurückblieb, obwohl es bei logikintensiven Aufgaben etwas besser abschnitt als bei Faktenfragen.
Updates, Sprachen und die Bereitschaft, „Ich weiß es nicht“ zu sagen
Da KI-Systeme häufig aktualisiert werden, untersuchten die Forschenden auch, wie sich die Leistung über fünf Testrunden von Ende 2023 bis Mitte 2025 veränderte. Große Versionsupdates führten tendenziell zu klaren Sprüngen in der Genauigkeit, während kleinere Anpassungen innerhalb derselben Version wenig Unterschied machten. Eine Familie kletterte im Zeitverlauf von unter 60 % auf über 80 % Genauigkeit, was zeigt, wie schnell sich die Technologie weiterentwickelt. Überraschenderweise hatten die Sprache der Fragestellung (Chinesisch oder Englisch) und die Formulierung (direkt vs. in Rollenspiel-Prompts eingebettet) nur geringe Effekte im Vergleich zu den jeweiligen Stärken der Modelle. Auffälliger waren die Unterschiede darin, wie offen die Systeme mit eigener Unsicherheit umgingen: Manche Modelle räumten bei fast jeder fünften falschen Antwort Unsicherheit ein, während ein anderes dies selten tat und stattdessen häufig selbstbewusste, aber falsche Antworten gab.
Was das für Ärztinnen, Studierende und Patientinnen bedeutet
Die Studie kommt zu dem Schluss, dass die derzeit besten allgemeinen Chatbots bereits relativ zutreffende Erläuterungen und Übungsfragen zu BNCT liefern können und damit vielversprechende Hilfen für Bildung und Selbststudium darstellen. Keines der Systeme ist jedoch bislang zuverlässig genug, um alle BNCT-Fragen korrekt zu beantworten, und ihre Art, Unsicherheit zu äußern — oder zu verschleiern — unterscheidet sich in sicherheitsrelevanter Weise. Gegenwärtig sind diese Werkzeuge am sinnvollsten als intelligente Assistenten zu betrachten, die fachliche Urteile unterstützen, aber nicht ersetzen. Die Autoren empfehlen, spezialisierte, BNCT-fokussierte KI-Modelle sowie klare Standards für den Einsatz solcher Werkzeuge in Kliniken und Lehrveranstaltungen zu entwickeln, bevor KI eine verlässliche vorderste Rolle in dieser hochspezialisierten Form der Krebsbehandlung übernehmen kann.
Zitation: Shen, S., Wang, S., Gao, M. et al. Performance comparison of large language models in boron neutron capture therapy knowledge assessment. Sci Rep 16, 5321 (2026). https://doi.org/10.1038/s41598-026-36322-7
Schlüsselwörter: Bor-Neutroneneinfangtherapie, Krebsstrahlung, medizinische Ausbildung, künstliche Intelligenz, große Sprachmodelle