Clear Sky Science · de
Objektgesteuertes kontrastives Sprach‑Bild‑Vortraining für Zero‑Shot‑Zielerkennung
Schlauere Augen für überfüllte Himmel und Meere
Moderne Sicherheits‑ und Katastrophenschutzsysteme verlassen sich auf Kameras in Himmel und auf See, um Flugzeuge, Schiffe und andere kritische Objekte zu erkennen. Es ist jedoch überraschend schwierig, Computern beizubringen, einen Jagdjet von einem Passagierflugzeug oder einen Kriegsträger von einem Frachtschiff zu unterscheiden, wenn Szenen überfüllt sind, Daten knapp sind und ständig neue Gerätemodelle auftauchen. Dieses Papier stellt OG‑CLIP vor, ein neues KI‑System, das militärische und zivile Ziele erkennt, auf die es nie explizit trainiert wurde, indem es groß angelegtes Vorwissen mit einem schärferen visuellen Fokus auf die entscheidenden Objekte kombiniert.
Warum traditionelle KI das Ziel verfehlt
Die meisten Bilderkennungssysteme lernen aus riesigen Sammlungen beschrifteter Fotos: Jedes Bild ist mit einer festen Liste von Kategorien verknüpft, etwa „Katze“ oder „Auto“. Dieser Ansatz versagt in spezialisierten Bereichen wie Verteidigung und Fernerkundung, wo Daten sensibel sind, die Beschriftung Experten erfordert und die Vielfalt der Ausrüstung enorm ist. Neuere Vision‑Language‑Modelle wie CLIP koppeln Bilder mit kurzen Bildunterschriften aus dem Web, was ihnen erlaubt, neue Konzepte zu erkennen, die in Worten beschrieben werden. In militärischer Bildgebung tun sich diese Modelle jedoch weiterhin schwer: Bildunterschriften sind oft vage, Hintergründe wie Wolken und Wellen dominieren die Pixel, und ihre internen Merkmale sind nicht flexibel genug, um effizient auf Geräten von kleinen Drohnen bis zu leistungsstarken Servern zu laufen. OG‑CLIP geht alle drei Probleme direkt an.
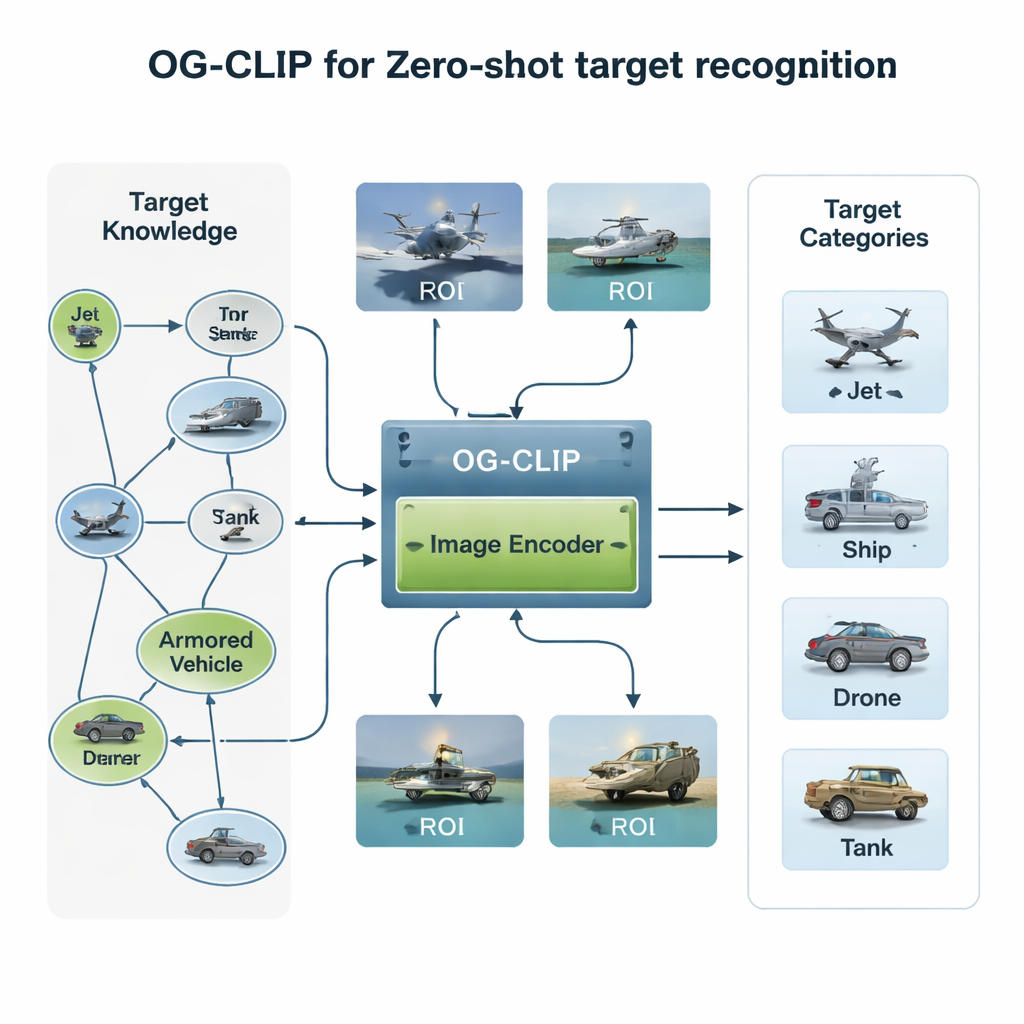
Aufbau einer wissensreichen Trainingswelt
Die erste Zutat von OG‑CLIP ist ein sorgfältig gestaltetes Trainingsuniversum. Die Autorinnen und Autoren stellten eine Datenbank mit 5.000 Zieltypen zusammen — von Jägern und Bombern bis zu Kriegsschiffen und zivilen Flugzeugen — und organisierten sie in einem detaillierten Wissensgraphen. Jeder Eintrag enthält strukturierte Fakten wie Reichweite, Gewicht und Waffenkonfiguration, entnommen aus öffentlichen Verteidigungsreferenzen, Enzyklopädien und technischen Dokumenten. Anschließend sammelten sie rund eine Million Bilder aus öffentlichen Datensätzen, Websuchen, älteren internen Archiven und sogar simulierten Szenen aus Spielengines. Um die Daten vertrauenswürdig zu halten, gruppierten sie Bilder mit einem bestehenden Modell, um Ausreißer zu finden, folgten mit Expertenprüfungen nach und filterten fehlerhafte Labels heraus. Schließlich nutzten sie fortgeschrittene Sprach‑Bild‑Werkzeuge, um den Wissensgraphen in reichhaltige, natürlichsprachliche Beschreibungen jedes Bildes zu verwandeln, sodass das System nicht nur „das ist ein Jet“ lernt, sondern „ein Single‑Aisle‑Flugzeug mit nach oben gebogenen Flügelspitzen“ oder „ein Tarnkappenbomber in Flying‑Wing‑Form“.
Dem Modell beibringen, das Rauschen zu ignorieren
Eine zweite Innovation liegt darin, wohin das Modell schaut. In vielen Satelliten‑ oder Luftbildern nimmt das tatsächliche Schiff oder Flugzeug nur ein kleines Bildfeld ein, umgeben von ablenkendem Himmel, Meer oder Gelände. OG‑CLIP ergänzt ein Region‑of‑Interest‑(ROI‑)Modul, das imitiert, wie ein Mensch eher das Schlüsselorjekt als den gesamten Rahmen betrachtet. Ein hochmoderner Segmentierungsalgorithmus umreißt automatisch wahrscheinliche Objekte im Bild und erzeugt weiche Masken, die das Ziel hervorheben und den Hintergrund abdunkeln. Diese Masken werden zusammen mit dem Originalbild in den visuellen Backbone des Modells eingespeist, sodass seine Aufmerksamkeit sich natürlicherweise auf markante Merkmale wie Flügelform, Deckanordnung oder Rumpfsilhouette konzentriert. Dieses Plug‑in‑Design lässt sich bestehenden Systemen hinzufügen, ohne deren Kernarchitektur umzuschreiben, und verleiht ihnen einen stärker „objektgesteuerten“ Blick.

Details an die Hardware anpassen
Der dritte Baustein greift ein praktisches, aber entscheidendes Problem auf: Nicht alle Geräte können sich denselben Detailgrad leisten. Eine Satellitenbodenstation kann reichhaltige, hochdimensionale Merkmale verarbeiten, während eine kleine Drohne schnellere, leichtere Berechnungen benötigt. Traditionelle Methoden fixieren eine einzelne Merkmalsgröße oder trainieren mehrere separate Modelle für verschiedene Größen. OG‑CLIP verwendet stattdessen eine „Matroschka“‑artige Repräsentation, die Informationen auf mehreren Detailebenen in einem Vektor bündelt, wie ineinander verschachtelte Puppen. Das System kann kürzere oder längere Abschnitte dieses Vektors abschneiden — gröbere oder feinere Beschreibungen dessen, was im Bild ist — ohne neu trainiert werden zu müssen. Ein Gewichtungsmechanismus ermutigt jede Ebene, die nützlichsten Informationen für die Klassifikation zu behalten, und ein zusätzlicher Verlustterm bringt die Ebenen dazu, semantisch konsistent zueinander zu bleiben.
Wie gut funktioniert es in der Praxis?
Um OG‑CLIP zu testen, bauten die Forschenden einen anspruchsvollen Evaluationssatz mit 99 Zielkategorien auf, darunter 51 Typen militärischer Flugzeuge, 29 Typen Kriegsschiffe und 19 zivile oder gemischte Ziele. Entscheidend ist, dass keine dieser Kategorien in den Trainingsdaten vorkommt, sodass das System auf sein erlerntes Verständnis von Sprache und visuellen Mustern angewiesen ist — ein Zero‑Shot‑Test. Im Vergleich zu mehreren starken CLIP‑basierten Baselines verbesserte OG‑CLIP die mittlere Genauigkeit um mehr als 11 Prozentpunkte und erreichte insgesamt 84,28 Prozent. Besonders gut schnitt es in überfüllten, komplexen Szenen und bei feinen Unterscheidungen zwischen ähnlichen Modellen ab, etwa bei verschiedenen Kampfflugzeugen, wo das ROI‑Modul und die wissensreichen Beschreibungen ihm einen klaren Vorteil verschafften. Ablationsstudien zeigten, dass jede Komponente — die Wissensgraphdaten, der ROI‑Fokus und die adaptiven Repräsentationen — messbare Verbesserungen beitrug.
Was das für die Überwachung in der Praxis bedeutet
Für Nicht‑Fachleute lautet die wichtigste Erkenntnis, dass OG‑CLIP einen Schritt in Richtung Sicherheits‑ und Überwachungssysteme darstellt, die unbekannte Flugzeuge und Schiffe aus realen Bildern zuverlässiger erkennen können, selbst wenn beschriftete Beispiele rar sind. Durch die Kombination strukturierter Expertenkenntnisse, automatischer Fokussierung auf das interessante Objekt und anpassbarer Detailebenen macht der Ansatz Vision‑Language‑KI sowohl schlauer als auch praktischer. Über die Verteidigung hinaus könnten ähnliche Ideen der Umweltüberwachung, Katastrophenhilfe und industriellen Inspektion helfen, komplexe Szenen zu deuten und auf einer breiten Palette von Hardware zu laufen.
Zitation: Zheng, C. Object-guided contrastive language-image pre-training for zero-shot target recognition. Sci Rep 16, 6425 (2026). https://doi.org/10.1038/s41598-026-36314-7
Schlüsselwörter: Zero‑Shot‑Erkennung, Vision‑Language‑Modelle, Objekterkennung, Fernerkundung, Wissensgraphen