Clear Sky Science · de
Skalierung digitaler Modelle
Warum das Verkleinern von Maschinen wichtig ist
Bevor neue Baumaschinen jemals Erde berühren, testen Ingenieure heute zuerst ihre virtuellen Gegenstücke. Diese digitalen Stellvertreter, genannt digitale Modelle, helfen vorherzusagen, wie echte Geräte sich verhalten, sparen Kosten und erhöhen die Sicherheit. Aber jede Maschinengröße – Vollgröße, Mittelklasse oder Tischmodell – braucht normalerweise einen eigenen, teuren Satz Sensoren und Prüfungen, damit das digitale Modell vertrauenswürdig wird. Dieses Papier zeigt einen Weg, nur eine echte Maschine zu kalibrieren und dieses Wissen dann „zu verkleinern“ oder „zu vergrößern“, sodass es für unterschiedlich große Maschinen gilt, ohne alle Experimente zu wiederholen.
Von realen Maschinen zu ihren virtuellen Zwillingen
Digitale Modelle versuchen, die tatsächliche Physik einer Maschine nachzubilden: wie schwere Teile sich bewegen, wie Hydraulikzylinder drücken, wie Boden dem Schaufelblatt Widerstand leistet. Werden diese Modelle mit realen Messwerten von Sensoren an der Maschine abgestimmt, können sie zu digitalen Zwillingen werden, die während des Betriebs aktualisiert werden. Für Baumaschinen wie Radlader sind solche Modelle besonders nützlich, weil die Branche mit geringer Produktivität bei sich wiederholenden Aufgaben kämpft. Frühere Arbeiten zeigten, dass physikbasierte Simulationen Bewegungen beim reinen Fahren meist genau nachbilden können, beim Graben mit der Schaufel jedoch oft stark versagen. In solchen Momenten werden die Kräfte komplex und schwer vorhersehbar. Sorgfältige Experimente mit Lastmessbolzen, Drucksensoren und Bewegungstrackern können das korrigieren, doch diesen Prozess für jede Modellgröße in einer Produktfamilie zu wiederholen, wird schnell zu teuer.

Warum einfache Skalierung versagt
Ingenieure nutzen seit Langem Skalamodelle: Windkanäle für Flugzeuge, Miniaturbrücken und verkleinerte Schiffe. Das übliche Werkzeug dahinter ist die Dimensionsanalyse, die die Physik in dimensionslose Zahlen umschreibt – Verhältnisse, die bei perfekter Ähnlichkeit auf jeder Skala gleiches Verhalten zeigen sollten. In der Praxis halten reale Produktlinien diese idealen „Similitude“-Regeln selten ein. Verschiedene Radlader können veränderte Proportionen, unterschiedliche Hydrauliklayouts oder leicht abweichende Materialien aufweisen. Diese Abweichungen, sogenannte verzerrte Skalierungsfaktoren, verändern die Beziehungen zwischen den wichtigen dimensionslosen Zahlen. Traditionelle Formeln und einfache Regressionswerkzeuge können diese Verzerrungen nicht zuverlässig erfassen, besonders wenn das zugrundeliegende Verhalten hochgradig nichtlinear ist. Folglich können klassische Skalierungsgesetze erhebliche Fehler erzeugen, wenn sie direkt auf moderne Industriemaschinen angewendet werden.
Die Verzerrungen durch Daten lernen lassen
Die Autorinnen und Autoren schlagen ein neues Rahmenkonzept vor, das das maschinelle Lernen die tatsächliche Skalierungsweise erlernen lässt, wenn die sauberen Lehrbuchannahmen versagen. Zuerst verwenden sie Dimensionsanalyse, um einen komplexen Radladermechanismus auf eine kleine Menge einflussreicher Variablen zu reduzieren, wie Gelenkkräfte, Schaufelgewicht, Hydraulikdrücke und Beschleunigungen. Diese werden zu dimensionslosen Gruppen kombiniert, die das Systemverhalten kompakter beschreiben. Als Nächstes führen sie „Verzerrungsterme“ ein, die messen, wie sich jede dieser Gruppen zwischen einer Referenzmaschine (z. B. einem mittelgroßen Radlader) und einer anderen Maschine (größer oder kleiner) unterscheidet. Ein neuronales Netzwerk wird dann trainiert, diese Verzerrungen auf einen einzigen Vorhersagefaktor abzubilden, der angibt, wie stark eine zentrale Größe – hier die Kraft in einem kritischen Schaufelgelenk – beim Übergang zwischen Skalen anzupassen ist. Anstatt für jeden Radladertyp ein neues Modell per Hand zu erstellen, entdeckt das Netzwerk diese Abbildung direkt aus simulierten und gemessenen Daten.
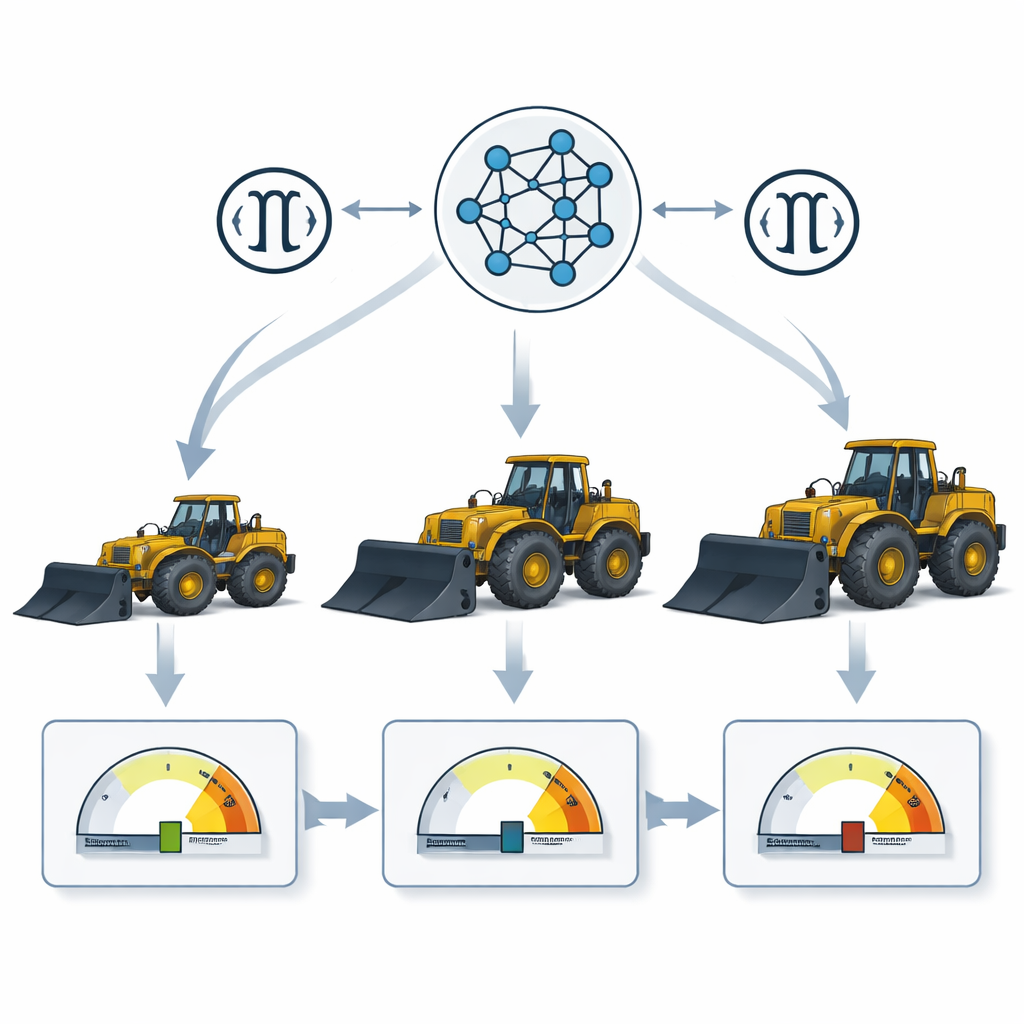
Test des Konzepts an drei Radladern
Um die Methode zu prüfen, verwendete das Team ein detailliertes digitales Modell eines industriellen Radladers, das bereits sorgfältig mit Sensoren kalibriert worden war. Dieses kombinierten sie mit einem größeren kommerziellen Radlader und einem winzigen 11‑Kilogramm-Tischmodell. Der mittelgroße und der große Wagen lieferten Trainingsdaten, erzeugt durch realistische Simulationen von Grabbewegungen. Der Miniaturlader wurde zurückbehalten als unverbrauchter Testfall. Es wurden mehrere Maschinelles‑Lernen‑Setups ausprobiert, darunter ein Standard-Feed‑Forward‑Netzwerk und komplexere rekurrente Netze, die Zeitverläufe berücksichtigen. Der beste Performer war das einfachere Feed‑Forward‑Netz, das den Skalierungsfaktor für Gelenkkräfte mit nahezu perfekter statistischer Genauigkeit auf den Trainingsskalen vorhersagte. Auf den Miniaturlader – dessen Daten es nie gesehen hatte – angewandt, verringerte die Methode den mittleren Fehler bei der geschätzten Gelenkkraft auf etwa 4 Prozent, verglichen mit mehr als 40 Prozent Fehler bei Anwendung der reinen Lehrbuchskalierung.
Was das für zukünftige Maschinen bedeutet
Für Nicht‑Spezialistinnen und -Spezialisten lautet die Quintessenz, dass Unternehmen bald in der Lage sein könnten, eine gut instrumentierte „Hero“-Maschine zu kalibrieren und dieses Wissen dann zuverlässig auf eine ganze Familie größerer und kleinerer Maschinen zu übertragen. Indem die Strenge der Dimensionsanalyse mit der Flexibilität neuronaler Netze kombiniert wird, verwandelt dieser Ansatz unordentliche reale Unterschiede in erlernbare Muster. Das könnte die Anzahl an Sensoren, Tests und Ingenieursstunden, die nötig sind, um akkurate digitale Zwillinge über eine Produktlinie hinweg zu erstellen, drastisch reduzieren. Über Radlader hinaus könnte dieselbe Strategie helfen, viele andere komplexe Systeme zu entwerfen und zu prüfen – von Kränen und Robotern bis zu Energieanlagen –, überall dort, wo das Bauen und Instrumentieren jeder Version in voller Größe zu langsam oder zu teuer wäre.
Zitation: Karanfil, D., Ravani, B. Scaling digital models. Sci Rep 16, 5962 (2026). https://doi.org/10.1038/s41598-026-36310-x
Schlüsselwörter: digitaler Zwilling, maschinelles Lernen, dimensionsanalyse, Baugeräte, Modellskalierung