Clear Sky Science · de
Visuelle Wahrnehmungsbasierte Deep-Learning-Transformer zur Klassifizierung von Gemälden und Fotografien durch Merkmalsextraktion
Warum das für Alltagsbilder wichtig ist
In einer Zeit, in der jeder mit wenigen Klicks ein fotorealistisches Bild erzeugen kann, wird es immer schwieriger zu erkennen, ob ein Bild ein echtes Foto, ein traditionelles Gemälde oder etwas vollständig von Algorithmen Erstelltes ist. Diese Studie untersucht, wie moderne Künstliche Intelligenz automatisch von Menschen gemalte Werke von kameras aufgenommenen Fotos und sogar von KI-generierten Bildern unterscheiden kann, und damit Kunstmärkte, Archive und Online-Nutzer vor Verwirrung und Fälschung schützt.
Kunst, Fotos und der Aufstieg maschinell erzeugter Bilder
Gemälde und Fotografien können auf einem Bildschirm auf den ersten Blick ähnlich wirken, tragen aber sehr unterschiedliche visuelle Fingerabdrücke. Gemälde zeigen oft sichtbare Pinselstriche, stilisierte Farben und eher abstrakte Kompositionen, während Fotografien in der Regel schärfere Details und natürlichere Beleuchtung enthalten. Gleichzeitig produzieren neue Bildgeneratoren Werke, die beide Medien immer besser nachahmen. Museen, Galerien, Sammler und digitale Plattformen benötigen zunehmend Werkzeuge, die schnell und zuverlässig erkennen können, mit welcher Art von Bild sie es zu tun haben—sowohl zur Authentifizierung von Kunstwerken als auch zur Bewältigung der Flut synthetischer Inhalte.
Eine neue Pipeline, um Maschinen das Sehen beizubringen
Die Forschenden entwickelten eine komplette Bildanalyse-Pipeline, die auf einem Vision Transformer basiert, einem neueren Deep-Learning-Modell, das ursprünglich für Sprachverarbeitung entwickelt und nun auf Bilder adaptiert wurde. Sie trainierten dieses System mit einem öffentlichen Kaggle-Datensatz, der 1.361 Gemälde und 3.747 Fotografien enthält und eine große Vielfalt an Szenen und Stilen abbildet. Jedes Bild wird zunächst standardisiert: Es wird skaliert, leicht beschnitten und dann durch Spiegelungen, kleine Rotation, Helligkeitsänderungen und Rauschunterdrückung augmentiert, damit das Modell viele realistische Variationen erlebt. Nach dieser Vorbereitung teilt der Vision Transformer jedes Bild in kleine Patches und lernt, wie verschiedene Bildbereiche zueinander über das gesamte Bildfeld in Beziehung stehen. 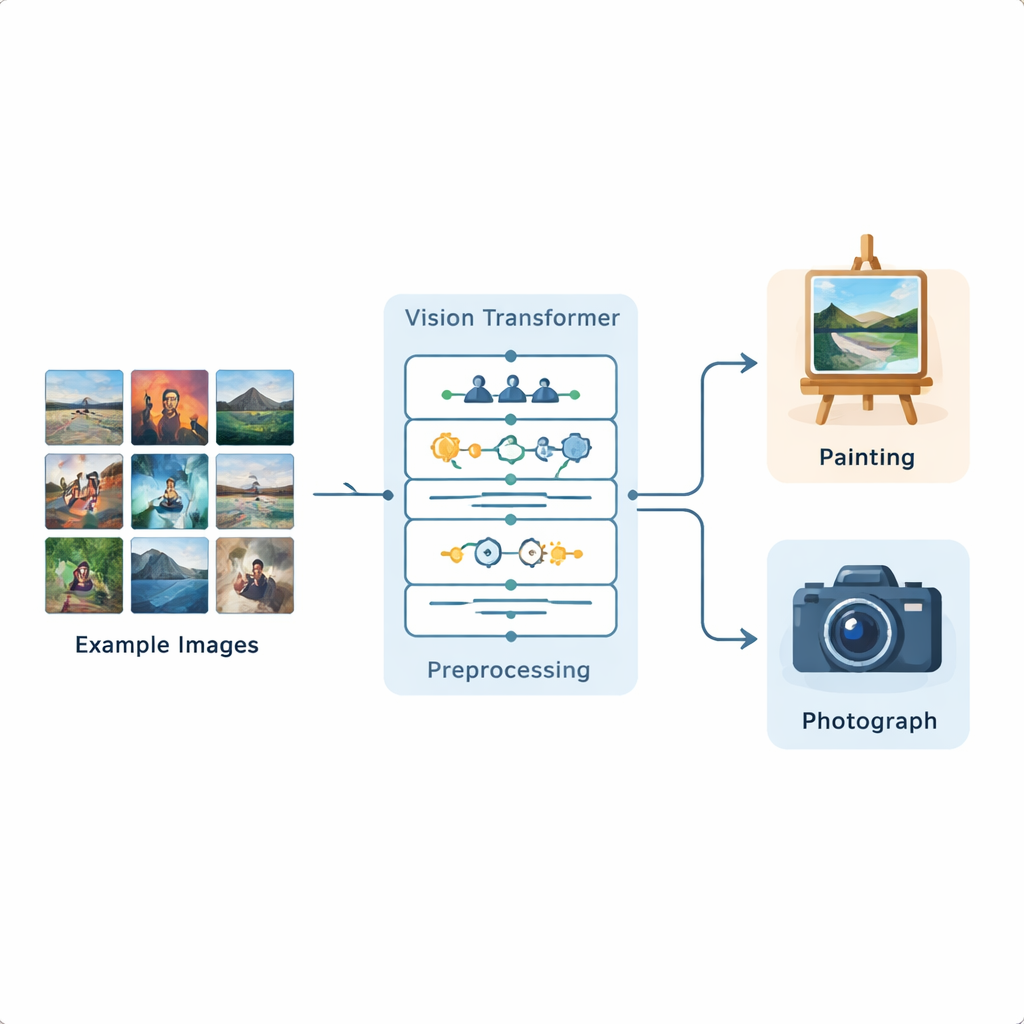
Wie das Modell sich auf die richtigen Details konzentriert
Im Gegensatz zu früheren neuronalen Netzen, die vor allem lokale Muster betrachten, verwendet der Vision Transformer einen „Attention“-Mechanismus, um zu entscheiden, welche Teile eines Bildes für die Aufgabe am wichtigsten sind. Er fragt effektiv für jeden Patch, wie stark er auf jeden anderen Patch achten sollte. Das macht ihn besser darin, die globale Struktur zu erkennen: wie Farben über eine Leinwand fließen, wie Licht eine Szene durchfällt oder wie sich Texturen wiederholen. Um zu prüfen, dass das Modell nicht blind rät, wenden die Autorinnen und Autoren zudem eine Visualisierungsmethode namens Grad-CAM an, die die spezifischen Regionen hervorhebt, die jede Entscheidung beeinflusst haben. Bei Gemälden fallen diese Hervorhebungen tendenziell auf Pinselstrichtexturen und stilisierte Bereiche; bei Fotografien konzentrieren sie sich auf feine Kanten, realistische Oberflächen und Lichtübergänge. 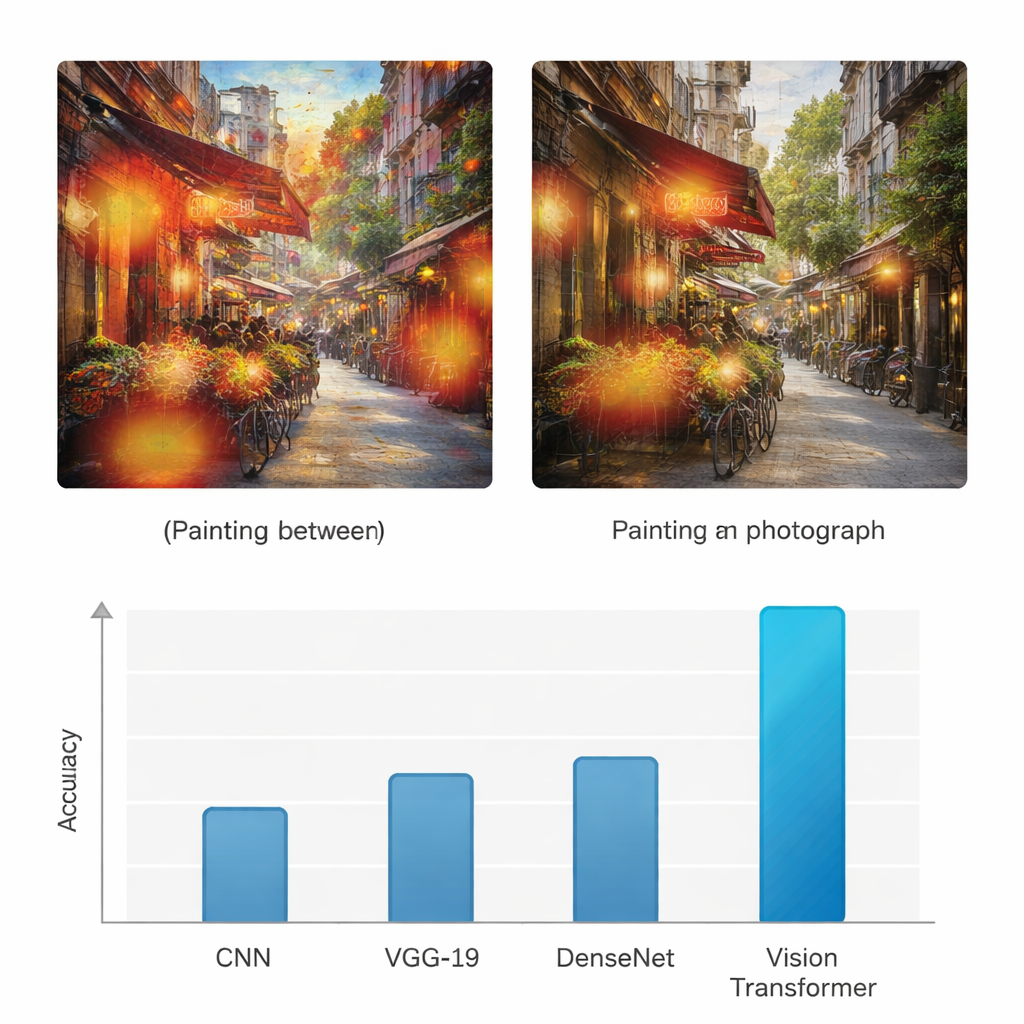
Übertrifft frühere Bilderkennungsmethoden
Um zu prüfen, ob dieser Ansatz tatsächlich einen Mehrwert bietet, vergleicht die Studie den Vision Transformer mit drei weit verbreiteten Deep-Learning-Architekturen: einem standardmäßigen Convolutional Neural Network (CNN), dem VGG-19-Netzwerk und DenseNet. Alle Modelle werden auf demselben Datensatz trainiert und getestet und mit gängigen Metriken wie Genauigkeit, Präzision, Recall und F1-Score bewertet, die korrekte Treffer und Fehler für beide Klassen ausbalancieren. Während die Baseline-Netze Genauigkeiten im Bereich von etwa 70–80+ Prozent erreichen, erzielt der Vision Transformer eine Genauigkeit von 95 % sowohl für Gemälde als auch für Fotografien, mit ähnlich hohen Werten bei Präzision und Recall. Die Autorinnen und Autoren führen zudem mehrere statistische Tests durch, um zu bestätigen, dass diese Verbesserung nicht zufällig ist, und zeigen, dass das transformerbasierte Modell zuverlässig besser über wiederholte Durchläufe und unterschiedliche Bewertungsmaßstäbe hinweg abschneidet.
Was das für Kunst, Vertrauen und Technologie bedeutet
Die Ergebnisse deuten darauf hin, dass moderne Transformer-Modelle als leistungsfähige und erklärbare Werkzeuge dienen können, um Gemälde von Fotografien zu trennen und KI-generierte Bilder, die eines der Medien nachahmen, zu kennzeichnen. Für Nichtfachleute ist die Erkenntnis, dass Computer nun subtile Hinweise erkennen können—wie Pinselarbeit, Glätte oder Lichtverläufe—die selbst aufmerksamen Betrachtern verborgen bleiben könnten, und dies in großem Maßstab. Solche Systeme könnten Galerien und Sammler bei der Verifizierung von Werken unterstützen, Kuratoren und Archivare bei der Organisation großer digitaler Sammlungen helfen und Online-Plattformen beim Kennzeichnen oder Filtern synthetischer Inhalte unterstützen. Da Bildgeneratoren die Grenze zwischen Realität und Erfindung weiter verwischen, bieten Methoden wie die hier vorgestellte einen praktischen Weg, Vertrauen in das, was wir sehen, zu bewahren.
Zitation: Yu, L. Visual perception based deep learning transformers for classifying paintings and photographs through feature extraction. Sci Rep 16, 5326 (2026). https://doi.org/10.1038/s41598-026-36298-4
Schlüsselwörter: KI-erzeugte Bilder, Kunstauthentifizierung, Bildklassifikation, Vision Transformer, digitale Kunstanalyse